| Россия, Пошатово |
Инспектор
Вы можете этот курс.
Опубликован: 08.04.2009 | Уровень: для всех | Доступ: платный
Лекция 12:
Оптимальное кодирование
12.3. Код Хаффмена
Теперь задача о коде минимальной средней длины приобретает такую
форму: для данных положительных 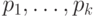 , равных
в сумме единице, найти целые положительные
, равных
в сумме единице, найти целые положительные 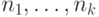 , для которых выполнено неравенство
Крафта-Макмиллана, а сумма
, для которых выполнено неравенство
Крафта-Макмиллана, а сумма
 ,
удовлетворяющих неравенству). Задача 12.2.5. показывает, что средняя длина однозначного кода не
меньше этого минимума, а задача 12.2.3. говорит,
что этот минимум достигается, причем даже для префиксного кода.
Как же найти числа , доставляющие этот минимум?
,
удовлетворяющих неравенству). Задача 12.2.5. показывает, что средняя длина однозначного кода не
меньше этого минимума, а задача 12.2.3. говорит,
что этот минимум достигается, причем даже для префиксного кода.
Как же найти числа , доставляющие этот минимум?12.3.1.
Доказать, что для двух букв оптимальный код состоит из
двух слов длины 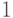 , независимо от частот букв.
, независимо от частот букв.
Чтобы решить задачу в общем случае, начнем с нескольких простых замечаний.
12.3.2.
Пусть частоты расположены в убывающем порядке:  . Доказать, что тогда длины слов оптимального
кода идут в неубывающем порядке:
. Доказать, что тогда длины слов оптимального
кода идут в неубывающем порядке:  .
.
Решение. Если бы более редкая буква имела бы более короткое кодовое слово, то, обменяв кодовые слова, мы сократили бы среднюю длину кода.
12.3.3. Останется ли утверждение предыдущей задачи в силе, если частоты расположены в невозрастающем порядке (возможны равные)?
Решение. Нет: если, скажем, имеются три буквы с частотой 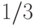 ,
то оптимальный код будет иметь длины слов
,
то оптимальный код будет иметь длины слов 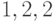 (если бы два
кодовых слова имели длину , то на третье уже не осталось бы
места), и они могут идти в любом порядке.
(если бы два
кодовых слова имели длину , то на третье уже не осталось бы
места), и они могут идти в любом порядке.
Заметим, однако, что при поиске оптимального кода (для невозрастающих частот) мы вправе ограничиваться лишь кодами, в которых длины кодовых слов неубывают (поскольку кодовые слова для букв одинаковых частот можно переставлять без изменения средней длины кода).
12.3.4.
Пусть частоты расположены в невозрастающем порядке
(  ), а длины слов в оптимальном коде
расположены в неубывающем порядке
), а длины слов в оптимальном коде
расположены в неубывающем порядке  .
Доказать, что
.
Доказать, что  (при
(при  ).
).
Решение. Предположим, что это не так, и что есть единственное
самое длинное кодовое слово длины 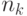 . Тогда неравенство
Крафта-Макмиллана не может обращаться в равенство, поскольку
все слагаемые, кроме наименьшего (последнего), кратны
удвоенному последнему слагаемому. Значит, в этом
неравенстве есть запас, причем не меньший последнего слагаемого.
А тогда можно уменьшить на единицу, не нарушая
неравенства, что противоречит предположению об оптимальности
исходного кода.
. Тогда неравенство
Крафта-Макмиллана не может обращаться в равенство, поскольку
все слагаемые, кроме наименьшего (последнего), кратны
удвоенному последнему слагаемому. Значит, в этом
неравенстве есть запас, причем не меньший последнего слагаемого.
А тогда можно уменьшить на единицу, не нарушая
неравенства, что противоречит предположению об оптимальности
исходного кода.
Эта задача показывает, что при поиске оптимального кода можно рассматривать лишь коды, в которых две самые редкие буквы имеют коды одинаковой длины.
12.3.5.
Как свести задачу отыскания длин кодовых слов
оптимального кода для  частот
частот

 частот
частот
Решение. Мы уже знаем, что можно рассматривать лишь коды
с  . Неравенство Крафта-Макмиллана тогда
запишется как
. Неравенство Крафта-Макмиллана тогда
запишется как

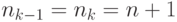 . Таким образом, числа
. Таким образом, числа  должны удовлетворять неравенству Крафта
Макмиллана для букв. Средняя длины этих двух кодов
будут связаны:
должны удовлетворять неравенству Крафта
Макмиллана для букв. Средняя длины этих двух кодов
будут связаны:![\begin{multiline*}
p_1 n_1+\ldots+p_{k-2} n_{k-2}+ p_{k-1} n_{k-1}+ p_k n_k = {}\\
{}= p_1 n_1+\ldots+p_{k-2} n_{k-2}+ (p_{k-1}+p_k)n + [p_{k-1}+p_k].
\end{multiline*}](/sites/default/files/tex_cache/59cc5c00652857cdc97d39326997e78c.png) для частот
для частот  . После этого
надо положить , и это даст оптимальный код для
исходной задачи.
. После этого
надо положить , и это даст оптимальный код для
исходной задачи.Используя эту задачу, несложно составить рекурсивную программу
для отыскания длин кодовых слов. С каждым вызовом число букв
будет уменьшаться, пока мы не сведем задачу к случаю двух букв,
когда оптимальный код состоит из слов  и . Затем
можно найти и сами кодовые слова (согласно
задаче 12.2.3.). Но проще объединить эти действия
и сразу искать кодовые слова: ведь замена числа
и . Затем
можно найти и сами кодовые слова (согласно
задаче 12.2.3.). Но проще объединить эти действия
и сразу искать кодовые слова: ведь замена числа  на два числа
на два числа  соответствует замене кодового слова
соответствует замене кодового слова 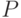 на два
слова
на два
слова 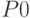 и
и 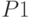 на единицу большей длины (и эта последняя замена
сохраняет префиксность кода).
на единицу большей длины (и эта последняя замена
сохраняет префиксность кода).
Код, построенный таким методом, называется кодом Хаффмена. Мы доказали, что он имеет минимальную среднюю длину среди всех кодов (для данных частот букв). В следующей задаче оценивается число операций, необходимых для построения кода Хаффмена.
12.3.6.
Показать, что можно обработать частоты , сделав 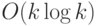 операций, после чего
операций, после чего  -ое кодовое слово
можно указать за время, пропорциональное его длине.
-ое кодовое слово
можно указать за время, пропорциональное его длине.
Указание.
Заметим, что оценка времени довольно сильная: только на
сортировку чисел 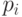 уже уходит действий.
Поэтому, применяя предыдущую задачу, нужно использовать
результаты сортировки чисел при сортировке меньшего
количества чисел. Это можно сделать с помощью очереди
с приоритетами, вынимая два минимальных числа и добавляя их
сумму за
уже уходит действий.
Поэтому, применяя предыдущую задачу, нужно использовать
результаты сортировки чисел при сортировке меньшего
количества чисел. Это можно сделать с помощью очереди
с приоритетами, вынимая два минимальных числа и добавляя их
сумму за  действий. Это позволяет определить,
какие две буквы надо соединять в одну на каждом шаге.
Параллельно с соединением букв можно строить дерево кодов,
проводя ребра (помеченные и ) от соединенной буквы к каждой из ее половинок. При этом требуется
действий. Это позволяет определить,
какие две буквы надо соединять в одну на каждом шаге.
Параллельно с соединением букв можно строить дерево кодов,
проводя ребра (помеченные и ) от соединенной буквы к каждой из ее половинок. При этом требуется 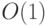 действий на каждом шаге. После завершения построение
прослеживать код любой буквы можно
символ за символом.
действий на каждом шаге. После завершения построение
прослеживать код любой буквы можно
символ за символом.