Московский государственный университет путей сообщения
Опубликован: 22.12.2006 | Доступ: свободный | Студентов: 2505 / 622 | Оценка: 4.07 / 4.02 | Длительность: 16:07:00
ISBN: 978-5-9556-0071-0
Специальности: Разработчик аппаратуры
Лекция 2:
Микропроцессорные системы и способы распараллеливания
Распределенный и разделяемый вычислительный ресурс второго уровня. Решающие поля
Произведем некоторые обобщения.
Итак, второй уровень распараллеливания предполагает распределение команд, инструкций, операций, элементарных функций и других несложных процедур — для выполнения исполнительными устройствами процессоров или в общем вычислительном ресурсе симметричной ВС. Здесь существуют свои проблемы, связанные с "элементарным" характером операций, небольшим объемом содержащихся в них работ, с их еще большей критичностью по отношению к "накладным расходам" на организацию и синхронизацию. Мы предполагаем, что исполнительные устройства ВС образуют вычислительный ресурс второго уровня (распараллеливания).
Сложились традиции построения этого ресурса, где основное внимание уделяется построению многофункциональных АЛУ. Однако в ряде архитектур пока еще робко пробивает себе дорогу объединение АЛУ в единый разделяемый ресурс системы — построение решающих полей.
Проработка этой идеи проводилась неоднократно в отечественной практике разработки ВС. Она проявлялась во включении в состав ВС специализированных процессоров на правах интеллектуальных терминалов для эффективного выполнения определенных операций. Это были векторные процессоры с доступом от нескольких ЦП (ПС-3100), векторный сопроцессор в ПС-2100. Эта же идея фактически воплощена в семействе "Эльбрус", допускающем включение в свой состав спецпроцессоров — эмуляции других систем, векторно-конвейерных модулей и др.
При реализации идеи решающего поля проблема выбора и развития вычислительного ресурса неотделима от выбора вариантов архитектуры системы вообще. Единственным средством обоснования и исследования этого выбора является моделирование. Построение детерминированных имитаторов позволяет с любой детализацией выявить целесообразные технические решения и обосновать язык системы. Целью стохастических моделей является оценка эффективности различных архитектур на основе полноты полезной загрузки оборудования.
На основе традиций разработки многопроцессорных симметричных вычислительных систем можно сделать вывод о практике и тенденции развития вычислительного ресурса второго уровня.
Все модели семейства МВК "Эльбрус" предполагают наличие в составе АЛУ процессора нескольких исполнительных устройств (ИУ), специализированных по типам операций. Тогда в целом для ВС можно сказать, что вычислительный ресурс второго уровня является распределенным и неоднородным (рис. 2.2).
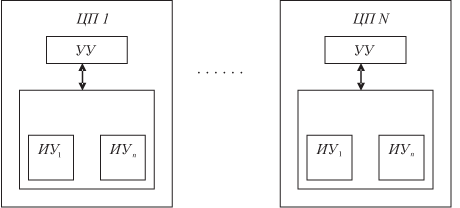
Выше говорилось, что использование ресурса второго уровня неотделимо от общих идей функционирования процессоров ВС — от их архитектуры и от архитектуры ВС в целом. Поэтому сказанного о распределенном ресурсе недостаточно, надо говорить и о способе его использования.
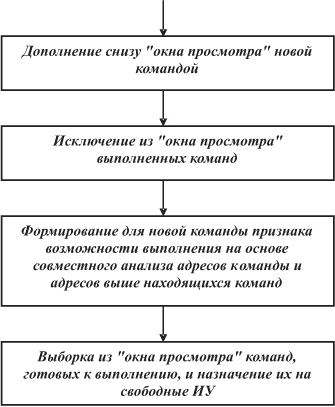
Так, в МВК "Эльбрус-2" применена динамическая загрузка ИУ в процессе выполнения последовательности безадресных команд программы, которую подробно рассмотрим в лекции 3. Обобщенный алгоритм такой загрузки основан на промежуточном переводе безадресных команд в трехадресные. Появление адресов аргументов и результатов в каждой команде позволяет на основе совместного анализа нескольких команд, представленных в "окне просмотра", выявлять их частичную упорядоченность и выделять независимые команды для одновременного выполнения. Это — адресный метод распараллеливания, который рассматривался в архитектуре data flow. Команды проходят стадии обработки, как показано на рис. 2.3.
Однако проект МВК "Эльбрус-3", породивший микропроцессорное воплощение — МВК "Эльбрус-3М", — основан на использовании идеи "длинного" командного слова и управления каждым тактом системы. Динамическое распределение работ между ИУ заменено статическим — предписанием каждому ИУ, что он должен начать делать в данном такте. В "длинном" командном слове, в соответствующих позициях, записаны инструкции каждому ИУ.
Это означает, что решение проблем оптимального использования ИУ, их синхронизации при выполнении данного алгоритма возлагаются на оптимизирующий транслятор. Он фактически производит диспетчирование, оптимальное планирование параллельного вычислительного процесса на одном процессоре.