Московский государственный университет путей сообщения
Опубликован: 22.12.2006 | Доступ: свободный | Студентов: 2503 / 622 | Оценка: 4.07 / 4.02 | Длительность: 16:07:00
ISBN: 978-5-9556-0071-0
Специальности: Разработчик аппаратуры
Лекция 10:
Асинхронная ВС на принципах "data flow"
Аннотация: Обсуждается проблема практического применения принципа data flow
при построении асинхронных вычислительных систем. В таких системах коммутация взаимодействия
процессорных элементов решающего поля для выполнения программы отделена от
собственно вычислений и слабо зависит от них. Формулируются принципы
составления программы коммутации и анализируется ее выполнение.
Ключевые слова: ВС, data flow, программа коммутации, ПЭ и процессора памяти, процессор коммутации, процессор, ПО, решающее поле, буфер, операции, адрес, регистр, текст которой, процессор памяти, запись, очередь заявок, параллелизм, работ, команда, ПОЛИЗ, информационный граф, граф, ярусно-параллельная форма, инструкция, память, эта программа выполняется, виртуальный вычислительный ресурс, процессорный элемент, адресный генератор, Виртуализация, if - then - else, виртуальный адрес, программа, коммутация, тег, генератор, ситуационное управление, группа, определение, бесскобочная запись, индексация, номер ПЭ, номер регистра его буфера, алгоритм выполнения заявок к памяти данных., интерливинг
Структура и программирование
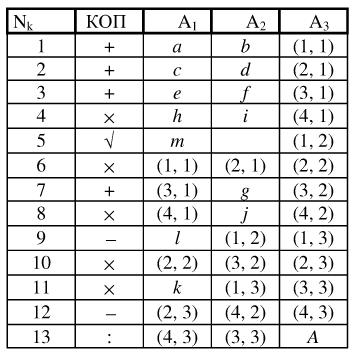
Рассмотрим модель ВС, управляемую потоком данных ( data flow ), сочетающую в себе принципы "фон-Неймановской" и "не-фон-Неймановской" архитектур.
Вычислительный процесс представлен не традиционной программой, а программой коммутации исполнительных устройств — ПЭ и процессора памяти (рис. 10.1). Выполняет ее процессор коммутации (просто процессор ). Обрабатывая команду за командой, и даже выполняя команды перехода (т.е. работая по принципу "фон-Неймана"), он по каждой анализируемой команде сообщает некоторому выбранному для этого ПЭ решающего поля, в один из свободных регистров его буфера, код предписываемой ему операции и адрес некоторого другого или даже этого же ПЭ, точнее, адрес регистра его буфера, куда следует отправить результат в качестве операнда. Этим он формирует отдельную инструкцию в буфере выбранного ПЭ.
Таким образом, каждый регистр каждого буфера имеет места для записи кода операции, всех операндов (почему именно четыре, рассмотрим далее), результата операции и адреса, по которому он должен быть отправлен.
Каждый ПЭ "смотрит" на свой буфер и по мере своего освобождения пытается выбрать для выполнения ту инструкцию, в текст которой поступили все операнды.
Одним из ПЭ является процессор памяти, который в ходе анализа каждой команды процессором получает заявки к памяти данных и тоже располагает адресом регистра буфера ПЭ, куда он должен послать результат считывания. Для выполнения записи ПЭ располагает адресом заявки на запись в буфере процессора памяти (в очереди заявок ), куда он пошлет нужный результат, после чего эта заявка сможет быть рассмотрена для выполнения.
Таким образом, в ходе работы процессора коммутации исполнительные устройства ВС оказываются информационно связанными между собой так, что могут работать асинхронно, но соблюдать преемственность в обработке данных. Параллелизм проявляется полностью и с максимальной естественностью, с минимальными накладными расходами.
Принципиально возможно окончание работы процессора задолго до того как закончится выполнение работ решающим полем; сдерживают условные переходы и ограниченность вычислительного ресурса (в частности, объемы буферов).
Упрощенно рассмотрим принцип программирования и даже трансляции для данной ВС.
Пусть команда программы коммутации имеет трехадресную структуру 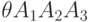 ,
где A1, A2 — адреса операндов (ОПД или регистра буфера), A3 — адрес регистра
буфера того ПЭ, который будет выполнять инструкцию, сформированную на основе
этой команды. При отсутствии виртуализации ресурса такой адрес будем задавать парой
(номер ПЭ, номер регистра буфера).
,
где A1, A2 — адреса операндов (ОПД или регистра буфера), A3 — адрес регистра
буфера того ПЭ, который будет выполнять инструкцию, сформированную на основе
этой команды. При отсутствии виртуализации ресурса такой адрес будем задавать парой
(номер ПЭ, номер регистра буфера).
Пусть при n = 4 задано выражение

По его записи на ПОЛИЗ легко построить информационный граф G (рис. 10.2), отражающий возможный параллелизм.
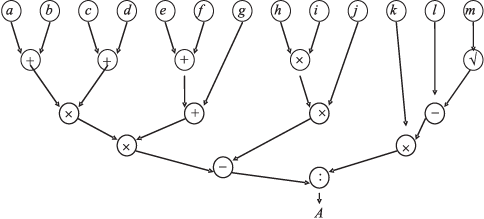
Данный граф имеет так называемую ярусно-параллельную форму, наглядно иллюстрирующую возможность параллельного выполнения всех операций, которые составляют один ярус.
Следуя разбиению на ярусы, сформируем команды (рис. 10.3), соответствующие первым возможным параллельным операциям. При этом для каждой операции назначим ПЭ и номер регистра его буфера, в котором при выполнении программы коммутации будет формироваться соответствующая ему инструкция. Заявки к памяти данных формируются в ОЗП.