|
приветствую создателей курса и благодарю за доступ к информации! понимаю, что это уже никто не исправит, но, возможно, будут следующие версии и было бы неплохо дать расшифровку сокращений имен регистров итд, дабы закрепить понимание их роли в общем процессе. |
Национальный исследовательский ядерный университет «МИФИ»
Опубликован: 03.03.2010 | Доступ: свободный | Студентов: 5426 / 1354 | Оценка: 4.35 / 3.96 | Длительность: 24:14:00
ISBN: 978-5-9963-0267-3
Тема: Аппаратное обеспечение
Специальности: Разработчик аппаратуры
Теги:
Лекция 9:
Конвейерная организация работы микропроцессора
Конфликты в конвейере и способы минимизации их влияния на производительность процессора
Конфликты - это такие ситуации в конвейерной обработке, которые препятствуют выполнению очередной команды в предназначенном для нее такте.
Конфликты делятся на три группы:
- структурные,
- по управлению,
- по данным.
Структурные конфликты возникают в том случае, когда аппаратные средства процессора не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением.
Причины структурных конфликтов:
-
Не полностью конвейерная структура процессора, при которой некоторые ступени отдельных команд выполняются более одного такта.
Пусть этап выполнения команды i+1 занимает 3 такта. Тогда диаграмма работы конвейера будет иметь вид, представленный в табл. 9.3.
Таблица 9.3. Конвейерная обработка при задержке команды i+1 на этапе EX Команда Такт 1 2 3 4 5 6 7 8 9 i IF ID OR EX WB i+1 IF ID OR EX EX EX WB i+2 IF ID OR O O EX WB i+3 IF ID OR O O EX i+4 IF ID OR O O В этом случае в работе конвейера возникают так называемые "пузыри" (pIPelINe bubble) в обработке команд i+2 и следующих за ней начиная с такта 6, которые снижают производительность процессора.
Если какой-то блок конвейера вносит задержку, то тормозится работа всего конвейера. Образуемый при этом "пузырь" должен пройти от места своего возникновения до самого конца конвейера (если, например, возникла задержка на ступени считывания команды, то в следующем такте блок декодирования от него ничего не получит, а через 3 такта соответственно блок сохранения результатов ничего не получит от блока выполнения). Таким образом, скорость конвейера определяется скоростью самой медленной его ступени.
Этой ситуации можно было бы избежать двумя способами. Первый предполагает увеличение времени такта до такой величины, которая позволила бы все этапы любой команды выполнять за один такт. Однако при этом существенно снижается эффект конвейерной обработки, так как все этапы всех команд будут выполняться значительно дольше, в то время как обычно нескольких тактов требует выполнение лишь отдельных этапов очень небольшого количества команд. Второй способ предполагает использование таких аппаратных решений, которые позволили бы значительно снизить затраты времени на выполнение действия, приводящего к появлению "пузырей" (например, использовать матричные схемы умножения). Но это приведет к усложнению схемы процессора и сокращению на кристалле места для реализации на этой БИС других, функционально более важных узлов. Так как представленная в табл. 9.3 сcитуация возникает при реализации команд, относительно редко встречающихся в программе, то обычно разработчики процессоров ищут компромисс между увеличением длительности такта и усложнением того или иного устройства процессора.
- Недостаточное дублирование некоторых ресурсов.
Одним из типичных примеров таких конфликтов служит конфликт из-за доступа к запоминающим устройствам. Из табл. 9.1 ввидно, что в случае, когда операнды и команды находятся в одном запоминающем устройстве начиная с такта 3, работу конвейера придется постоянно приостанавливать, поскольку различные команды в одном и том же такте обращаются к памяти на считывание команды, выборку операнда, запись результата.
Борьба с конфликтами такого рода проводится путем увеличения количества однотипных функциональных устройств, которые могут одновременно выполнять одни и те же или схожие функции. В запоминающих устройствах в современных микропроцессорах с этой целью разделяют кэш-память для хранения команд и кэш-память данных, а также используют многопортовую схему доступа к регистровой памяти, при которой к регистрам можно одновременно обращаться по нескольким каналам для записи и считывания информации. Например, в микропроцессоре Itanium к блоку регистров общего назначения допускается одновременное обращение на выполнение 8 операций чтения и 6 операций записи. Конфликты из-за исполнительных устройств обычно сглаживаются введением в состав микропроцессора дополнительных блоков. Так, в микропроцессоре Pentium 4 для обработки целочисленных данных предусмотрено 4 АЛУ. При этом появляется возможность параллельной обработки информации в нескольких конвейерах. Процессоры, имеющие в своем составе более одного конвейера, называются суперскалярными.
Недостатком суперскалярных микропроцессоров является необходимость синхронного продвижения команд в каждом из конвейеров. В табл. 9.4 п представлена последовательность выполнения команд в микропроцессоре, имеющем два конвейера, при условии, что команде К1 требуется 3 такта на этапе EX.
| Этап | Такт | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||||||||
| IF | K1 | K2 | K3 | K4 | K5 | K6 | K7 | K8 | K7 | K9 | K7 | K10 | K11 | K12 |
| ID | K1 | K2 | K3 | K4 | K5 | K6 | K5 | K8 | K5 | K9 | K7 | K10 | ||
| OR | K1 | K2 | K3 | K4 | K3 | K6 | K3 | K8 | K5 | K9 | ||||
| EX | K1 | K2 | K1 | K4 | K1 | K6 | K3 | K8 | ||||||
| WB | K2 | K4 | K1 | K6 | ||||||||||
При этом команды будут завершаться в порядке, отличающемся от того, который предусмотрен программой: К2-К4-К1-К6-...
Следовательно, для обеспечения правильной работы суперскалярного микропроцессора при возникновении затора в одном из конвейеров должны приостанавливать свою работу и другие. В противном случае может нарушиться исходный порядок завершения команд программы. Но такие приостановки существенно снижают быстродействие процессора.
Разрешение этой ситуации состоит в том, чтобы дать возможность выполняться командам в одном конвейере вне зависимости от ситуации в других конвейерах, а аппаратные средства микропроцессора должны гарантировать, что результаты выполненных команд будут записаны в приемник в том порядке, в котором команды записаны в программе. Это обеспечивается путем использования так называемого принципа неупорядоченного выполнения команд. Суть его заключается в следующем. Блок выборки и декодирования выбирает команды из памяти и заносит их в буфер команд. По мере готовности операндов и исполнительного блока соответствующего типа команды извлекаются из буфера для обработки. Порядок их исполнения может отличаться от предписанного программой.
Результаты этапа выполнения команды сохраняются в специальном буфере восстановления последовательности команд. Запись результата очередной команды из этого буфера в приемник результата проводится лишь после того, как выполнены все предшествующие команды и записаны их результаты. Преимущества такого подхода очевидны: команды максимально используют возможности всех конвейеров, присутствующих в микроархитектуре микропроцессора, что обеспечивает его максимальную производительность.
Конфликты по управлению возникают при конвейеризации команд переходов и других команд, изменяющих значение счетчика команд.
Суть конфликтов этой группы наиболее удобно проиллюстрировать на примере команд условного перехода. Пусть в программе, представленной в табл. 9.1, команда i+1 является командой условного перехода, формирующей адрес следующей команды в зависимости от результата выполнения команды i. Команда i завершит свое выполнение в такте 5. В то же время команда условного перехода уже в такте 3 должна прочитать необходимые ей признаки, чтобы правильно сформировать адрес следующей команды. Если конвейер имеет большую глубину (например, 20 ступеней), то промежуток времени между формированием признака результата и тактом, где он анализируется, может быть еще больше.
Простейший способ разрешения этой ситуации - использование так называемого метода выжидания. Он заключается в замораживании операций в конвейере путем блокировки выполнения любой команды, следующей за командой условного перехода, до тех пор, пока не станет известным направление перехода. Привлекательность такого решения заключается в его простоте. Главный недостаток - резкое уменьшение преимуществ конвейерной обработки. В инженерных задачах примерно каждая шестая команда является командой условного перехода, поэтому приостановки конвейера при выполнении команд переходов до определения истинного направления перехода существенно скажутся на производительности процессора.
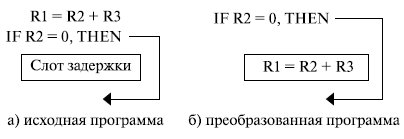
Можно несколько улучшить эту ситуацию, использую схему "задержанных переходов". При этом на стадии компиляции компилятор таким образом структурирует получаемый объектный код, чтобы сделать команды, следующие за командой перехода, действительными и полезными (рис. 9.1).
Слот задержки заполняется независимой командой, находящейся перед командой условного перехода. Эта команда выполняется за то время, пока микропроцессор формирует истинное условие, по которому должно быть определено направление выполнения программы. Одной из основных трудностей в этом подходе является определение точного времени выполнения команды, вносимой в слот задержки. Аппаратура должна гарантировать реальное выполнение этих команд перед выполнением собственно перехода.
Более эффективными для снижения потерь от конфликтов по управлению являются методы предсказания переходов. Они призваны максимально ускорить определение адреса команды, выполняемой после команды перехода.
Так как преимущества конвейерной обработки проявляются при большом числе последовательно выполненных команд, перезагрузка конвейера приводит к значительным потерям производительности. Поэтому вопросам эффективного предсказания направления ветвления разработчики всех микропроцессоров уделяют большое внимание.
Среди основных достоинств практически каждого нового микропроцессора производители анонсируют "улучшенный блок предсказания переходов". Суть конкретных механизмов, обеспечивающих эти улучшения, как правило, не детализируется. Однако здесь все-таки можно выделить несколько основных подходов.
Методы предсказания переходов делятся на статические и динамические. При использовании статических методов до выполнения программы для каждой команды условного перехода указывается направление наиболее вероятного ветвления. Это указание делается программойкомпилятором по заложенным в ней алгоритмам. Подобный подход реализован, например, в HP PA-8x00. Также это может делать и сам программист по опыту выполнения аналогичных программ либо по результатам тестового выполнения программы. Например, в системе команд микропроцессора Itanium для этого предназначена специальная команда.
Суть данного метода заключается в том, что при выполнении команды условного перехода специальный блок микропроцессора определяет наиболее вероятное направление перехода, не дожидаясь формирования признаков, на основании анализа которых этот переход реализуется.
Процессор начинает выбирать из памяти и выполнять команды по предсказанной ветви программы (так называемое исполнение по предположению, или "спекулятивное" исполнение). Однако так как направление перехода может быть предсказано неверно, получаемые результаты с целью обеспечения возможности их аннулирования не записываются в память или регистры (то есть для них не выполняется этап WB ), а накапливаются в специальном буфере результатов.
Если после формирования анализируемых признаков оказалось, что направление перехода выбрано верно, все полученные результаты переписываются из буфера по месту назначения и выполнение программы продолжается в обычном порядке. Если направление перехода предсказано неверно, все инструкции, выбранные после перехода, помечаются, согласно интеловской терминологии, как поддельные (bogus INsTRuctions).
При этом буфер результатов и конвейер, содержащий команды, которые следуют за командой условного перехода и находятся на разных этапах обработки, - очищаются. Аннулируются результаты всех уже выполненных этапов этих команд. Конвейер начинает загружаться с первой команды другой ветви программы.
Следует отметить, что конфликты по управлению не исчерпываются только проблемами, связанными с командами условных переходов. Они возникают при выполнении всех команд, меняющих значение счетчика команд. Это хорошо видно из табл. 9.1. Если команда i является командой такого типа (например, команда безусловного перехода), то адрес перехода будет вычислен ею в такте 5, в то время как уже в такте 2 необходимо выбирать в микропроцессор следующую команду по этому адресу.
Методы динамического предсказания реализуются при выполнении программы в микропроцессоре. Они осуществляют предсказание направления переходов на основании результатов предыдущих выполнений данной команды.
При использовании этих методов для команд условных переходов анализируется предыстория переходов - результаты нескольких предыдущих команд ветвления по данному адресу. В этом случае возможно определение чаще всего реализуемого направления ветвления, а также выявление чередующихся переходов.
Для команд безусловных переходов однажды вычисленный целевой адрес сохраняется в специальной памяти BTB ( Branch Target Buffer ), откуда он извлекается сразу же при декодировании данной команды.
Аналогичный подход используется для команд вызова - возврата из процедуры (анализ связок CALL - RETURN ).
Владислав Салангин
