|
приветствую создателей курса и благодарю за доступ к информации! понимаю, что это уже никто не исправит, но, возможно, будут следующие версии и было бы неплохо дать расшифровку сокращений имен регистров итд, дабы закрепить понимание их роли в общем процессе. |
Национальный исследовательский ядерный университет «МИФИ»
Опубликован: 03.03.2010 | Доступ: свободный | Студентов: 5628 / 1515 | Оценка: 4.35 / 3.96 | Длительность: 24:14:00
ISBN: 978-5-9963-0267-3
Тема: Аппаратное обеспечение
Специальности: Разработчик аппаратуры
Лекция 10:
Структура и особенности архитектуры микропроцессора Pentium 4
Аннотация: Цель лекции: изучение особенностей архитектуры микропроцессора INTel Pentium 4, а также обработки данных в блоках MMX/SSE.
Ключевые слова: микропроцессор, pentium, IA-32, FSB, поток команд, hyper-pipelined, dynamic execution, branch prediction, анализ потока данных, data flow analysis, тактовая частота, кеш-память, SIMD, SSE, процессор, x86, шина, мультиплексирование, front, two-sided, BUS, контроллер, доступ, RDRAM, memory, CONS, hub, канал передачи данных, шина данных, шина адреса, физическая память, информация, кэш, обмен данными, бит, память данных, память, декодирование, микрокоманда, execution, ACE, cache, execution tracing, OPS, поток инструкций, команда, условный переход, адрес, MMX, ступень конвейера, поток, производительность, интерфейс, способ адресации, регистр, чтение данных, выборка, FPU, TLB, ядро, арифметико-логическое устройство, ALU, плавающая запятая, препроцессор, суперскалярная архитектура, операции, условие ветвления, тактовый сигнал, модуль, ассоциативная память, BTB, команды переходов, анализ, I-MPEG, поддержка, игровая программа, &-параллелизм, разрядность, константы, Instruction, механизмы, время выполнения, сложение, переполнение, очередь, умножение, слово, байт, extension, файл, SSE2, инструкция, SSE3, SSE4, core
Структура и особенности архитектуры микропроцессора Pentium 4
Микропроцессор Pentium 4 является завершающей моделью 32-разрядных микропроцессоров фирмы Intel с архитектурой IA-32 (позже появились 64-битные процессоры с выходом Pentium 4 Prescott). Основные особенности этого процессора:
Микроархитектура процессора определяет реализацию его внутренней структуры, принципы выполнения поступающих команд, способы размещения и обработки данных. Микроархитектура NetBurst отличается от своих предшественников по целому ряду позиций:
- Применена гарвардская структура с разделением потоков команд и данных.
- Используется гиперконвейерная технология (Hyper-PIPelINed Technology) выполнения команд, при которой число ступеней конвейера достигает 31 (в Pentium III - 11 ступеней). Таким образом, одновременно в процессе выполнения на разных стадиях реализации может находиться свыше 30 команд.
- Используется динамическое выполнение команд ( dynamic execution ), построенное на трех базовых концепциях: предсказание переходов ( branch prediction ), динамический анализ потока данных (dynamic data flow analysis) и спекулятивное выполнение (OUT-oforder execution). Аналогичный механизм, названный Dynamic Execution, используется в МП Pentium III, однако в INTel Pentium 4 он улучшен.
- Выполнение арифметических и логических операций происходит с удвоенной тактовой частотой процессора, что позволяет за один такт получить результаты для двух команд.
- Кеш-память 2-го уровня емкостью 256 Кбайт размещается непосредственно на кристалле процессора, что позволяет сократить время выборки по сравнению с Pentuim III, где эта кэш-память располагается на отдельном кристалле в общем корпусе с процессором (в процессорах Pentium III Coppermine и Pentium III Tualatin кэш L2 интегрирован в ядро процессора).
- Значительно расширены возможности обработки чисел по принципу SIMD в новом блоке SSE-2.
Рассмотрим эти особенности более подробно.
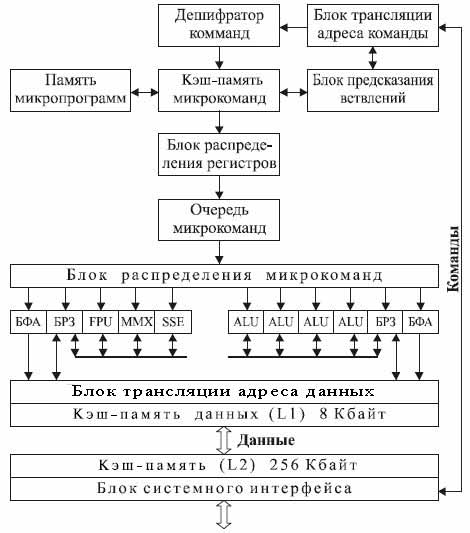
Структура МП Pentium 4 представлена на рис. 10.1.
Команды и данные поступают в микропроцессор через блок системного интерфейса.
Любой процессор архитектуры x86 обязательно оснащен процессорной шиной. Эта шина служит каналом связи между процессором и всеми остальными устройствами в компьютере: памятью, видеокартой, жестким диском и так далее. Так, классическая схема организации внешнего интерфейса процессора предполагает, что параллельная мультиплексированная процессорная шина, которую принято называть FSB (Front Side Bus), соединяет процессор (иногда два процессора или даже больше) и контроллер, обеспечивающий доступ к оперативной памяти и внешним устройствам. Этот контроллер обычно входит в состав северного моста набора системной логики (чипсета).
Для ускорения обмена с памятью в Pentium 4 используется новая реализация системной шины, обеспечивающая обмен с эквивалентной частотой 400 МГц. Такая скорость достигается путем применения нового типа сверхбыстродействующей двухканальной памяти типа RDRAM и специальной микросхемы MCH (Memory Con TR oller Hub), реализующей 4 канала передачи данных. При тактовой частоте каждого канала 100 МГц обеспечивается общая частота обмена, эквивалентная 400 МГц. Шина включает 64-разрядную двунаправленную шину данных, дающую пропускную способность в 3,2 Гбайт/с, и 36-разрядную шину адреса (33 адресных линии А35-А3 и 8 линий выбора байтов BE7-ВЕ0), что позволяет адресовать физическую память емкостью до 64 Гбайт.
Именно учетверенная результирующая частота передачи данных является одним из главных предметов гордости разработчиков Pentium 4.
Однако для многочисленных мелких запросов, где данные в большинстве своем умещаются в одну 64-байтную порцию (и, соответственно, не используются возможности многоканальной передачи), важнее именно частота тактирования.
Последние модели Pentium 4 работают на частотах системной шины 100, 133 и 200 МГц, что обеспечивает эквивалентную частоты FSB в 400, 533 и 800 МГц и пропускные способности в 3,2, 4,2 и 6,4 Гбайт/с.
Полученная по системной шине информация для ядра Willamette сохраняется в кэш-памяти 2-го уровня (L2) емкостью 256 Кбайт, общей для команд и данных, которая размещается непосредственно на кристалле МП. Ширина шины, по которой идет обмен данными между кэш-памятью L2 и процессором, составляет 256 бит (32 байта), а ее тактовая частота совпадает с тактовой частотой ядра процессора.
Гарвардская внутренняя структура реализуется на уровне кэш-памяти 1-го уровня (L1) путем разделения потоков команд и данных. Кэш-память данных 1-го уровня имеет емкость 8 Кбайт (данная емкость кэш-памяти 1-го уровня для данных характерна для Pentium 4 с ядром Willamette и Northwood. В последущих версиях была увеличена до 16 Кб.). Вместо кэш-памяти команд 1-го уровня в Pentium 4 используется кэш-память для декодированных команд (микрокоманд). Execution TR ace Cache - это название и одновременно способ реализации L1-кэша инструкций в архитектуре NetBurst. Смысловое содержание этого термина можно перевести как "кэш трассировки выполняемых микрокоманд". В Execution TRace Cache хранятся микрокоманды ( ?ops ), которые были получены в результате декодирования входного потока инструкций исполняемого кода и готовы для передачи на выполнение конвейеру. Емкость Execution TRace Cache составляет 12000.
После заполнения кэш-памяти микрокоманд практически любая команда будет храниться в ней в декодированном виде. Поэтому при поступлении очередной команды блок трассировки выбирает из этой кэшпамяти необходимые микрокоманды, обеспечивающие ее выполнение.
Если в потоке команд оказывается команда условного перехода, то включается механизм предсказания ветвления, который формирует адрес следующей выбираемой команды до того, как будет определено условие выполнения перехода.
После формирования потоков микрокоманд производится выделение регистров, необходимых для выполнения декодированных команд.
Эта процедура реализуется блоком распределения регистров. Он выделяет для каждого указанного в команде логического регистра (регистра цлочисленных операндов EAX, EBX и т. д., регистра операндов с плавающей точкой ST0-ST7 или регистра блоков MMX, SSE ) один из 128 физических регистров, входящих в состав блоков регистров замещения (БРЗ) целочисленного блока микропроцессора и блока обработки чисел с плавающей точкой. Эта процедура позволяет минимизировать конфликты в конвейерах и выполнять команды, использующие одни и те же логические регистры, одновременно или с изменением их последовательности.
Ступени распределения/переименования конвейера могут выпустить три микрокоманды за такт на следующую ступень конвейера.
Выбранные микрокоманды размещаются в очереди микрокоманд. В ней содержатся микрокоманды, реализующие выполнение до 120 поступивших и декодированных команд, которые затем направляются в исполнительные устройства. Отметим, что в процессорах Pentium III в очереди находятся микрокоманды для 40 поступивших команд. Значительное увеличение числа команд, стоящих в очереди, позволяет более эффективно организовать поток их исполнения, изменяя последовательность выполнения команд и выделяя команды, которые могут выполняться параллельно. Эти функции реализует блок распределения микрокоманд. Он выбирает микрокоманды из очереди не в порядке их поступления, а по мере готовности соответствующих операндов и исполнительных устройств. В результате команды, поступившие позже, могут быть выполнены до ранее выбранных команд. При этом реализуется одновременное выполнение нескольких микрокоманд (команд) в параллельно работающих исполнительных устройствах. Таким образом, естественный порядок следования команд (микрокоманд) нарушается, чтобы обеспечить более полную загрузку параллельно включенных исполнительных устройств и повысить производительность процессора.
Адреса операндов, выбираемых из памяти, вычисляются блоком формирования адреса (БФА), который реализует интерфейс с кэш-памятью данных 1-го уровня. В соответствии с заданными в декодированных командах способами адресации формируются 48 адресов для загрузки операндов из памяти в регистр БРЗ и 24 адреса для записи из регистра в память (в Pentium III формируются 16 адресов для загрузки регистров и 12 адресов для записи в память). При этом БФА формирует адреса операндов для команд, которые еще не поступили на выполнение. При обращении к памяти БФА одновременно выдает адреса двух операндов: один для загрузки операнда в заданный регистр БРЗ, второй - для пересылки результата из БРЗ в память. Таким образом реализуется процедура предварительного чтения данных для последующей их обработки в исполнительных блоках (спекулятивная выборка).
Аналогичным образом организуется параллельная работа блоков SSE, FPU, MMX, которые используют отдельный набор регистров и блок формирования адресов операндов.
При выборке операнда из памяти производится обращение к кэшпамяти данных ( L1 ), которая имеет отдельные порты для чтения и записи. За один такт производится выборка операндов для двух команд.
При формировании адресов обеспечивается обращение к заданному сегменту памяти. Каждый сегмент может делиться на страницы. Для сокращения времени трансляции используется буфер ассоциативной трансляции страничного адреса TLB, который хранит базовые адреса наиболее часто используемых страниц.
Микрокоманды поступают в исполнительное ядро из блока распределения по 4 портам в 8 исполнительных блоков. Эти порты выполняют функцию шлюзов к функциональным устройствам. Для обработки целочисленных данных и выполнения логических операций в Pentium 4 используются 4 однотипных арифметико-логических устройства ( ALU ).
Обработка чисел с плавающей запятой проходит в FPU. Блоки MMX и SSE предназначены для выполнения команд этих типов.
За один такт через порты может пройти до шести микрокоманд. Это больше, чем может выполнить препроцессор (3 микрокоманды за такт), что дает некоторую свободу в случае резкого увеличения количества готовых к исполнению микрокоманд. Суперскалярная архитектура микропроцессора реализуется путем организации исполнительного ядра МП в виде ряда параллельно работающих блоков.
Арифметико-логические блоки ALU производят обработку целочисленных операндов, которые поступают из заданных регистров БРЗ. В эти же регистры заносится и результат операции. При этом проверяются условия ветвления для команд условных переходов и выдаются сигналы перезагрузки конвейера команд в случае неправильно предсказанного ветвления. Рабочая тактовая частота модулей ALU в два раза выше тактовой частоты процессора. Это достигается за счет срабатывания как по переднему, так и по заднему фронтам задающего тактового сигнала. Таким образом, каждый ALU-модуль способен выполнить до двух целочисленных операций за один рабочий такт процессора.
Эффективность конвейера резко снижается из-за необходимости его перезагрузки при выполнении условных ветвлений, когда требуется произвести очистку всех предыдущих ступеней и выбрать команду из другой ветви программы. Чтобы сократить потери времени, связанные с перезагрузкой конвейера, используется улучшенный блок предсказания ветвлений. Его основной частью является ассоциативная память, называемая буфером адресов ветвлений BTB, в которой хранятся 4092 адреса ранее выполненных переходов. Отметим, что в BTB процессора Pentium III хранятся адреса только 512 переходов. Кроме того, BTB содержит биты, хранящие предысторию ветвления, которые указывают, выполнялся ли переход при предыдущих выборках данной команды. При поступлении очередной команды условного перехода указанный в ней адрес сравнивается с содержимым BTB. Если этот адрес не содержится в BTB, то есть ранее не производились переходы по данному адресу, то предсказывается отсутствие ветвления. В этом случае продолжается выборка и декодирование команд, следующих за командой перехода. При совпадении указанного в команде адреса перехода с каким-либо из адресов, хранящихся в BTB, производится анализ предыстории. В процессе анализа определяется чаще всего реализуемое направление ветвления, а также выявляются чередующиеся переходы. Если предсказывается выполнение ветвления, то выбирается и загружается в конвейер команда, размещенная по предсказанному адресу. Более совершенный механизм предсказания переходов в МП Pentium 4 обеспечивает уменьшение количества ошибочно предсказанных переходов в среднем на 33 % по сравнению с Pentium III. Таким образом, резко уменьшается число перезагрузок конвейера при неправильном предсказании ветвления.
В Pentium 4 также интегрирован набор из 144 новых SIMD-инструкций, обеспечивающих одновременное выполнение одной операции над несколькими операндами. Рассмотрим особенности использования этой схемы обработки данных подробнее.
Технология MMX - итог совместной работы создателей архитектуры микропроцессоров INTel и программистов. При ее разработке был исследован широкий круг программ аудиовизуальной обработки информации: обработка изображений, MPEG-видео, синтеза музыки, сжатия речи и ее распознавания, поддержка видеоконференций, компьютерные игровые программы и т. д. В результате этого анализа были выявлены основные особенности таких программ:
- использование данных целого типа небольшой разрядности, например, 8-разрядные графические пиксели и 16-разрядная оцифровка звука;
- короткие циклы с высокими коэффициентами повторяемости;
- большое количество операций умножения и суммирования, в том числе из-за широкого использования быстрого преобразования Фурье;
- применение алгоритмов, требующих интенсивных вычислений;
- широкое использование операций с высоким уровнем параллелизма.
Было отмечено, что в мультимедийных приложениях 80 % времени выполнения программы приходится на 10-20 % программного кода.
Малая разрядность данных требует дополнительных действий при их обработке на 32-разрядном микропроцессоре, не позволяя в то же время использовать всю мощь 32-разрядной архитектуры.
Простым и наглядным примером такого рода обработки может служить изменение значений всех пикселей видеопамяти на определенную величину. Пусть емкость видеопамяти составляет 1 Мбайт, а каждый пиксель кодируется 1 байтом. Тогда для выполнения указанного действия потребуется выполнить примерно 1 млн операций по прибавлению константы к однобайтовому операнду, который выбирается из памяти. Одновременное выполнение таких действий над 4 операндами, что сократило бы количество операций в 4 раза, невозможно в классической архитектуре IA-32 из-за отсутствия соответствующих команд в системе команд и форматов используемых данных.
На устранение этих противоречий и были направлены основные усилия разработчиков технологии MMX. Процессор Pentium MMX, в котором впервые была реализована новая технология, был представлен фирмой INTel в январе 1997 года. Он позволил на 10-20 % повысить производительность на стандартных тестах, а для специализированных мультимедийных приложений - на 50 %.
Владислав Салангин
