|
приветствую создателей курса и благодарю за доступ к информации! понимаю, что это уже никто не исправит, но, возможно, будут следующие версии и было бы неплохо дать расшифровку сокращений имен регистров итд, дабы закрепить понимание их роли в общем процессе. |
Национальный исследовательский ядерный университет «МИФИ»
Опубликован: 03.03.2010 | Доступ: свободный | Студентов: 5628 / 1515 | Оценка: 4.35 / 3.96 | Длительность: 24:14:00
ISBN: 978-5-9963-0267-3
Тема: Аппаратное обеспечение
Специальности: Разработчик аппаратуры
Лекция 11:
Основные направления развития архитектуры универсальных микропроцессоров
Аннотация: Цель лекции: изучить основные направления развития архитектуры универсальных микропроцессоров.
Ключевые слова: тактовая частота, ступень конвейера, значение, расходы, IPC, PER, cycle, alpha, микрооперация, устройство управления, &-параллелизм, энергопотребление, DVD, многопроцессорная конфигурация, транзистор, логическая схема, процессорный элемент, accumulate, Instruction, VLIW, EPIC, itanium, коммутация каналов, SMT, ultrasparc, поток инструкций, АЛУ, FPU, MMX, SSE, длина конвейера, поток команд, тестировщик, микропроцессор, IA-64, шина, память, исполнение, команда, операции, поле, отображение, архитектура, файл, прямой, запись, ядро, арифметические команды, логические команды, SIMD, бит, поиск, кэш, алгоритм, загрузка, branch prediction, table, регистр, буфер, адрес, счетчик, цикла
Основные направления развития архитектуры универсальных микропроцессоров
Развитие микропроцессорной техники в области универсальных микропроцессоров идет по пути постоянного повышения их производительности. Традиционными направлениями такого развития являются повышение тактовой частоты работы МП и увеличение количества одновременно выполняемых команд за счет увеличения числа конвейеров (исполнительных устройств) в МП.
Однако оба эти направления следует признать экстенсивными, имеющими естественные ограничения.
Повышение тактовой частоты, которое в основном обеспечивается путем увеличения количества ступеней в конвейере, приводит к большим потерям времени при необходимости перезагрузки конвейера вследствие конфликтов по управлению или при переключении на новую задачу. Такое увеличение имеет также и физические ограничения, связанные со схемотехникой кристалла БИС. Ограничения определяются также влиянием накладных расходов при передаче частично обработанной команды на следующую ступень конвейера (значение ?t при определении длительности такта). На больших частотах эти расходы становятся соизмеримыми с длительностью обработки на очередном этапе. Во многом это направление исчерпало себя в микропроцессоре Pentium 4, работающем на частотах, близких к 4 ГГц.
Повышение производительности за счет увеличения числа конвейеров в микропроцессоре можно оценить увеличением числа команд, выполняемых программами за такт (IPC - INsTRuctions Per Cycle). Так, для МП Alpha 21264 этот показатель равен 6, столько же микроопераций за такт может выдать Pentium 4. Но это предельные значения, а реальные программные коды, в частности, из-за различных взаимозависимостей, дают гораздо более низкое значение IPC. Дальнейшее увеличение числа исполнительных устройств ведет к усложнению расположенного в БИС устройства управления, распределяющего команды по конвейерам, а также к сложным взаимозависимостям между данными. К тому же реальные коды программ не позволяют обеспечить эффективную загрузку всех имеющихся в МП исполнительных устройств, что приводит к их простоям. Следует отметить также, что рост производительности микропроцессора не является прямо пропорциональным росту количества конвейеров, а обычно существенно ниже.__
В настоящее время для повышения производительности микропроцессоров используется ряд новых подходов, основными из которых являются:
- CMP (Chip Multi ProcessINg) - создание на одном кристалле системы из нескольких микропроцессоров (многоядерность);
- SMT (Simultaneous MultiThreadINg) - многонитевая архитектура;
- EPIC (Explicitly Parallel INsTRuction ComputINg) - вычисления с явным параллелизмом в командах.
Рассмотрим эти направления подробнее.
-
Направление CMP обеспечивается возросшими технологическими возможностями, которые позволяют создать на одном кристалле несколько микропроцессоров и организовать их работу по принципу мультипроцессорных систем.
Производители чипов уже не гонятся за частотой, сместив акцент на многоядерную архитектуру, которая позволяет наращивать производительность, сохраняя в приемлемых границах энергопотребление и тепловыделение.
Многоядерные процессоры хорошо приспособлены для требовательных мультимедийных задач, таких как обработка видеозаписей, работы с большими базами данных, одновременное выполнение нескольких ресурсоемких заданий, например, компьютерной игры, записи DVD и загрузки файлов из Интернета.
При таком подходе задача повышения производительности работы отдельных приложений требует распараллеливания последних, то есть проблема перемещается с аппаратного на программный уровень. На данный момент сложности заключаются в том, что большая часть существующего программного обеспечения создавалась без расчета на использование в многоядерных и многопроцессорных конфигурациях. Другими словами, прогресс в области аппаратных средств на какое-то время опередил прогресс в области программного обеспечения.
Развитие микропроцессорной техники в этом направлении идет очень быстрыми темпами. Так, компания Tilera в 2007 году начала поставки специализированных процессоров Tile64, насчитывающих 64 ядра. А в 2009 году, как ожидается, свет увидит 120-ядерная модификация этого процессора.
80-ядерный процессор от фирмы INTel
Еще в 2001 году руководство фирмы Intel уверенно обещало дотянуть одноядерную архитектуру процессоров Pentium до 2010 года с поднятием планки их рабочей частоты до 10 ГГц. Однако уже в 2008 году Intel объявила о прекращении выпуска одноядерных микропроцессоров. Новый 80-ядерный процессор от Intel, который в некоторых документах имеет обозначение Polaris, обеспечивает производительность до 1,28 триллиона операций с плавающей точкой в секунду (терафлопс) при частоте 4 ГГц.
Микропроцессор построен по технологии 65 нм из 100 млн транзисторов на кристалле площадью 275 мм2. Для сравнения: двухъядерный Intel Core 2 Ex TR eme, также с технологическими нормами 65 нм, содержит 291 млн транзисторов на площади 143 мм2. Разница обусловлена малым количеством памяти на кристалле нового МП и доминированием логических схем и схем ввода-вывода, размер которых трудно минимизировать. Большое внимание в нем уделено новому показателю, который занимает все более главенствующее положение, - производительность/ватт. По этому показателю Polaris обеспечивает чрезвычайную энергоэффективность: 16 гигафлопс/Вт. Процессор работает при напряжении питания 0,95 В.
Согласно заявлению представителей Intel, достигнутые показатели отнюдь не являются предельными. Инженеры компании могут значительно увеличить производительность процессора за счет увеличения его тактовой частоты. Так, например, на частоте 5,1 ГГц процессор демонстрирует 1,63 терафлопс, а на частоте 5,7 ГГц - 1,81 терафлопс. Однако с ростом тактовой частоты растет и потребляемая мощность, составляя при вышеуказанных режимах работы 175 и 265 ватт соответственно.
Polaris представляет собой 80 одинаковых процессорных элементов, каждый из которых состоит из вычислителя и маршрутизатора на 6 портов. Вычислитель содержит 2 устройства для операций умножения с накоплением ( FP MultIPle-Accumulator, FPMAC ), 3 Кбайт памяти команд и 2
Кбайт памяти данных, набор 32-разрядных регистров и оперирует 96-разрядными сверхдлинными словами команд ( Very Long INsTRuction Word -VLIW ). Планирование и параллельное выполнение команд возлагается на компилятор (архитектура EPIC, аналогичная реализованной разработчиками Intel и в процессоре Itanium). Она позволяет процессору исполнять до восьми команд за один такт. По своему набору инструкций новый микропроцессор несовместим с x86.
Все арифметические операции выполняются на FPMAC-модулях.
Эффективность многоядерных процессоров во многом определяется пропускной способностью памяти системы. Применение многоканальных шин памяти и повышение их частоты сопряжено с чрезмерным усложнением контроллеров. Другой путь уменьшения задержки - ввести еще один уровень иерархии кэш-памяти. Однако это приведет к неоправданному увеличению памяти на кристалле, площадь которого эффективнее использовать для вычислительной логики. Несколько мегабайт дополнительной кэш-памяти занимают площадь, достаточную для 10 процессорных ядер. Такой подход обеспечит широкий доступ ядер процессора к памяти. Каждый слой будет содержать до 256 Мбайт.
Другой фактор, ограничивающий производительность современных компьютеров, - пропускная способность процессорной шины. Разделяемые шины уже уступают свое место соединениям типа "точка-точка". В Polaris используется сеть процессорных элементов, основанная на передаче данных с коммутацией каналов. Каждый маршрутизатор содержит шесть 39-битных портов и обеспечивает суммарную пропускную способность до 80 Гбайт/c при частоте микросхемы 4 ГГц. Четыре порта ведут к смежным процессорным элементам, один к вычислителю, а шестой порт в перспективе будет взаимодействовать с многослойной памятью. Система коммутации предусматривает взаимодействие каждого маршрутизатора с каждым. В микропроцессоре ядра независимы в плане операций ввода-вывода. Поэтому, добавив необходимое ПО, можно реализовать различные интерфейсы и добиться любой функциональности устройства.
В настоящее время главное достижение Polaris - это создание фундамента (как аппаратного, так и идейного) для отработки новых технологий многоядерных архитектур. Он представляет собой скорее исследовательский проект, чем инженерное решение.
-
Направление SMT в развитии архитектуры микропроцессоров базируется на том, что одна задача не в состоянии полностью загрузить все возрастающие ресурсы микропроцессора. Поэтому на одном процессоре осуществляется запуск нескольких задач одновременно, при этом распараллеливание программ осуществляется аппаратными средствами МП.
Это позволяет более равномерно загрузить ресурсы процессора. Параллельно в разных устройствах МП могут выполняться команды из разных задач. Так, микропроцессор Alpha 21264 поддерживает выполнение до 4 задач одновременно. При поддержке SMT на 4 нити каждый процессор с точки зрения операционной системы выглядит как 4 логических процессора. Исследования показали, что SMT позволяет увеличить производительность данного процессора до двух раз, а дополнительные схемы управления занимают всего около 10 % площади кристалла.
Некоторые микропроцессоры для максимального повышения своей производительности используют оба вышеназванных подхода. Так, компания Sun Microsystems представила новый процессор ULTRaSPARC T2.
Новый чип снабжен восемью ядрами, каждое из которых может обрабатывать восемь потоков инструкций. Таким образом, он одновременно способен оперировать с 64 потоками. Тактовая частота ULTRaSPARC T2 составляет от 900 МГц до 1,4 ГГц.
-
Направление EPIC фактически использует известную технологию VLIW (Very Large INsTRuction Word) - очень длинного командного слова.
Распараллеливание алгоритма между исполнительными модулями производится компилятором на этапе создания машинного кода, когда команды объединяются в связки и не конкурируют между собой за ресурсы микропроцессора. При этом упрощается блок управления на кристалле.
Особенности архитектуры EPIC:
- Явный параллелизм в машинном коде. Поиск зависимостей между командами проводит не процессор, а компилятор.
- Большое количество регистров.
- Масштабируемость архитектуры до большого количества функциональных устройств (АЛУ, FPU, MMX, SSE и т. п.).
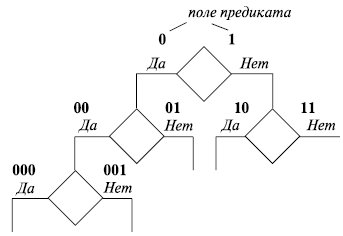
- Применение предикатов. Предикатный подход исходит из предпосылки, что возросшие мощности микропроцессоров позволяют запускать параллельно команды из разных ветвей условного ветвления вместо того, чтобы ожидать формирования истинных признаков для выбора правильного направления или полагаться на блок предсказания переходов, рискуя прийти к необходимости перезагрузки достаточно длинных конвейеров в случае неудачного предсказания. При этом каждая команда снабжается специальным полем условия (предикатом) (рис. 11.1). По мере определения истинных признаков ветвления те команды, предикаты которых указывали, что они выбраны из другой ветви, снимаются с обработки в конвейере. Результаты команд не записываются в прием ник до определения правильности направления перехода.
Отметим основные достоинства этого подхода:
- Упрощается архитектура процессора. Вместо логики распараллеливания на EPIC-процессоре можно разместить больше регист ров, функциональных устройств и т. п.
- Процессор не тратит время на анализ потока команд.
- Возможности процессора по анализу программы во время выполнения ограничены сравнительно небольшим участком программы, тогда как компилятор способен произвести анализ всей программы.
- Если некоторая программа должна запускаться многократно (а именно так и бывает в подавляющем большинстве случаев), выгоднее распараллелить ее один раз при компиляции, а не тратить на это время каждый раз, когда она исполняется на процессоре.
Однако архитектуре EPIC присущ и ряд недостатков:
- Компилятор производит статический анализ программы, раз и навсегда планируя вычисления. Однако даже при небольших изменениях исходных данных путь выполнения программы существенно изменяется.
- Значительно усложняются компиляторы, следовательно, увеличиваются время компиляции программы и число ошибок в самих компиляторах. Если первый фактор, учитывая высокое быстродействие современных компьютеров, не очень существенен, то на второй следует обратить определенное внимание. Исследования показывают, что к моменту поставки даже ответственного программного обеспечения в нем содержится примерно 1 ошибка на 10 000 строк исходного кода. Следовательно, программа из 500 тыс. строк будет содержать около 50 ошибок, как бы хорошо ни работали тестировщики. И эти ошибки могут проявиться самым неожиданным образом.
- Производительность микропроцессора во многом определяется качеством компилятора. Правда, здесь необходимо четко определить, что понимается под производительностью, ведь количество операций, выполняемых микропроцессором в единицу времени, от компилятора не зависит. Но это тема будет особо рассмотрена далее.
- Увеличивается сложность отладки, так как отлаживается не исходная программа, а оптимизированный параллельный код. Программисту тяжело определить место и причину появления ошибки, так как в процессе трансляции исходной программы ее отдельные команды будут переставлены компилятором для обеспечения оптимальности работы микропроцессора.
Типичным представителем архитектуры EPIC является микропроцессор Itanium фирмы Intel.
Владислав Салангин
