Язык SQL
8.10 Регулярные выражения
8.10.1 Преодоление атомарности
Мы уже отмечали (раздел 4.1), что в реляционной модели используемые типы просты, а значения с позиций модели данных атомарны, хотя в действительности они могут иметь некоторую структуру, недоступную в рамках модели.
В определении первой нормальной формы (радел 5.4) мы обратили внимание что существует непервая нормальная форма, в которой требуется наличие ключей, но допускается существование не атомарных атрибутов. Позднее станет ясно, что в использовании Н1НФ заключается возможность расширения моделей данных до объектных. Достаточно допустить векторные типы данных конструируемые пользователем.
Язык SQL также нарушает принцип атомарности данных. Например, запрос
SELECT ename FROM emp WHERE ename LIKE 'S%'
выбирает все фамилии, начинающиеся с буквы "S".
Правда, шаблоны поиска, помещаемые после слова LIKE, примитивны. Они представляют последовательность обычных символов и двух выделенных символов. Символ подчёркивания "_" означает точно один основной символ, а "%" задаёт любо количество основных символов.
Оператор "не число" (IS NAN) также разбирает операнд по символам.
Существует два пути преодоления ограничения атомарности:
- вынесение работы с внутренними структурами данных из сервера баз данных в сервер приложений или в клиентскую часть;
- встраивание в язык, например, SQL функций, работающих с этими структурами.
Для работы со значениями данных имеющих внутреннюю структуру во всех возможных вариантах можно использовать регулярные выражения, регламентированные стандартами POSIX, которые, к сожалению, не всегда исполняются в полном объёме.
8.10.2 Что такое регулярные выражения
Простые варианты регулярных выражений вы уже встречали в DOS (помните шаблоны для поиска файлов типа *.doc?). В языке Cache ObjectScript используются шаблоны отмечаемые знаками ? или '?. Мы их не рассматривали из-за того, что с кириллицей они не работают.
Регулярные выражения — это один из возможных способов поиска подстрок (соответствий) в строках. Осуществляется это с помощью просмотра строки в поисках некоторого шаблона.
Типичные примеры использования регулярных выражений: проверка соответствия формату (например телефонного номера, IP-адреса, имени файла), обнаружение лишних пробелов, поиск HTML-тегов, замена полей в строке и многое другое. Самое простое регулярное выражение состоит только из символов, например, "cat". Этот шаблон из трёх букв найдётся в следующих строках: cat, location и Tomcat.
В состав регулярного выражения можно включать метасимволы. Перечислим некоторые из них.
Точка "." в регулярном выражении означает любой символ за исключением символов с кодами ASCII 10-13. Например, шаблон означает "два любых символа ". Строки "aa", "ab", "xv" и "rrrr" этот шаблон содержат.
Шаблон можно привязать к началу или концу строки. Метасимволов привязки два. Это циркумплекс обозначающий начало строки и доллар "$" обозначающий её конец. Например, шаблону "^a.b$", в котором символ "a" привязан к началу строки, а "b" к её концу, соответствуют строки "aab", "abb" или "axb".
А что делать, если метасимвол должен войти в шаблон как простой символ? Например, в конце образца должна стоять точка. Достаточно перед метасимволом поместить обратную косую черту. Так, "." это любой символ, но "\." это символ "точка". А "\[" это "[".
Шаблон "\w" задаёт любой алфавитно-цифровой символ на любом регистре или символ подчёркивания. Для обозначения непечатаемых символов применяют тот же приём. Так "\f" это перевод страницы (form feed), "\n" это перевод строки (line feed). "\r" обозначает перевод каретки (carriage return), "\t" это табуляция (tab), "\v" — вертикальная табуляция (vertical tab). В некоторых случаях возможна инверсия условия. Так, "\D" означает "не цифра", "\W" это все символы кроме определённых шаблоном "\w".
Для задания нескольких вхождений символа в шаблон применяются квантификаторы. Один из них "*" повторяет предшествующее вхождение ноль и более раз. Например, строка из любого числа любых символов, начинающаяся буквой "a" и заканчивающаяся буквой "b" задаётся регулярным выражением ""^a.*b$".
| Квантификатор | Описание |
|---|---|
| * | ноль и более раз |
| ? | ноль или один раз |
| + | один и более раз |
| m | точно m раз |
| m, | m или более раз |
| m,n | по крайней мере m раз, но не более n раз |
Перечисление задаётся вертикальной чертой разделяющей допустимые варианты. Так, "a|e" позволяет выбрать либо "a" либо "e".
Группировка выполняется путём заключения части шаблона в круглые скобки. Например, шаблон "gray|grey" можно переписать, используя группировку, как "gr(a|e)y".
В одиночных квадратных скобках задаются классы символов. При каждом применении шаблона используется один из символов класса. Например, конструкция "gr[ae]y" даёт тот же результат, что шаблон "gr(a|e)y". Шаблон "\w" эквивалентен "[a-zA-Z0-9_ ]".
В классах можно указывать символы, которых не должно быть в найденной подстроке. Так, шаблон "["1-6]" находит все символы, кроме цифр от 1 до 6. Заметим, что дефис в середине текста класса означает диапазон, но дефис в первой позиции это просто символ дефис. Шаблону "\W" соответствует "[^a-zA-Z0-9_]]".
Кроме того, в список символов, обозначаемый квадратными скобками, может входить класс символов POSIX заключённый в свои квадратные скобки. Например, "[[:alnum:]]" обозначает один символ из класса алфавитно-цифровых символов, "[[:lower:]]" определяет один символ в нижнем регистре, а "[[:lower:]]{3}"" —три символа в нижнем регистре. Приведём пару полезных примеров:
- Шаблон телефонного номера "^\(\d{3} \) \d{3}-\d{4}$" ищет строку, которая начинается с трёхзначного числа в скобках. Эту особенность определяет подшаблон "^\(\d{3}\)". В нём знак переключения "\" помещён перед символами "(" и ")", чтобы интерпретировать их как скобки, а не как метасимвол группы. За цифрами в скобках идёт пробел, а за ним следует ещё одно трёхзначное число и дефис ("\d{3}-"). Строка заканчивается четырёхзначным числом ("\d{4}$"). Пример правильного номера: (123) 456-7890 и неправильного (123)456-7890.
- Шаблон адреса электронной почты "\w+@\w+(\.\w+)+" Здесь ищем любой алфавитно-цифровой символ повторяющийся один или более раз (то есть просто слово), затем символ @, затем снова слово, а после этого ищем шаблон состоящий из символа "." (поэтому используем знак переключения "\") и слова и этот шаблон может повторятся один или несколько раз.
На этом остановимся. Рассмотренных средств достаточно для решения простых задач, требующих использования регулярных выражений. Конечно, многие достаточно сложные конструкции (контекст, жадность алгоритма, юникод и т.д.) мы не затрагивали. Но ведь наша задача предельно ограничена — показать возможность преодоления ограничения атомарности.
На сайте книги вы найдете ссылки на литературу, которая позволит вам самостоятельно продолжить освоение регулярных выражений, и на сайты, с которых можно скачать необходимый инструментарий.
Заметим, что большие регулярные выражения довольно сложно писать и отлаживать. Ещё труднее разбирать сложные чужие шаблоны. Одна из неприятных особенностей регулярных выражений в том, что изменение одного символа часто приводит не к сообщению об ошибке, а к появлению трудно понимаемого результата.
Из-за различий в реализациях обычно не удаётся переносить регулярные выражения между языками и операционными системами без внесения необходимых изменений.
8.10.3 Регулярные выражения в базах данных и Web-клиентах
В Cache
Для работы с регулярными выражениями в Cache, начиная с версии 2012.2, в язык ObjectScript введены функции $LOCATE() и $MATCH(), а в классе %Regex.Matcher добавлены соответствующие методы.
Формат функции $LOCATE():
$LOCATE(строка,рег_выр[,начало][,конец][,значение])
Обязательны только первые два аргумента.
Функция $LOCATE() обнаруживает наличие шаблона "рег_выр" в строке и возвращает в виде целого числа позицию первого вхождения шаблона. Счёт позиций начинается с 1. Если шаблон не найден, вернётся 0. Аргумент "начало" указывает позицию, с которой начинается просмотр строки.
Если вхождение найдено, то аргументу "конец" присваивается номер позиции, следующей за концом найденного вхождения шаблона. Это позволяет в цикле найти все вхождения шаблона.
Атрибут "значение" отмечает, было ли найдено хотя бы одно вхождение шаблона.
Функция $MATCH() с булевым значением обнаруживает саму возможность применения шаблона. Ограничиться столь бедным набором функций удалось потому, что изначально в COS уже имелись средства для работы со списками и строками с разделителями.
В Oracle
Для работы с регулярными выражениями в Oracle существуют четыре функции: REGEXP_LIKE(), REGEXP_INSTR(), REGEXP_SUBSTR() и REGEXP_REPLACE().
Функция
REGEXP_LIKE(стpoкa, рег_выр [, параметр_сопоставления])
используется подобно оператору LIKE во фразе WHERE и в определениях ограничений на таблицу. Параметр_сопоставления позволяет использовать дополнительные параметры, такие как символ перехода на новую строку, многострочное форматирование и обеспечение управления учетом регистра. Функция
REGEXP_INSTR(стpoкa, рег_выр[, начало [, вхождение [, опция_возврата [, параметр_сопоставления ]]]])
Функция подобно INSTR() возвращает позицию символа, находящегося в начале или конце соответствия для шаблона. Атрибут "вхождение" по умолчанию равен 1, но может быть указан поиск последовательных вхождений. Если атрибут "опция_возврата" равен 0, то возвращается начальная
позиция найденного вхождения шаблона, если 1, то позиция символа, следующего за шаблоном.
В отличие от INSTR() функция REGEXP_INSTR() работает только вперёд от начала строки.
Функция
REGEXP_SUBSTR(HCxoflHaH_CTpoKa, шаблон[, позиция [, вхождение [,параметр_сопоставления]]])
возвращает подстроку, которая соответствует шаблону. Функция
REGEXP_REPLACE(исходная_строка, шаблон [, строка_замены[, позиция [, вхождение, [параметр_сопоставления]]]])
заменяет все вхождения шаблона во входной строке на значение, указанное в атрибуте "строка_замены".
Web-интерфейс
Проще всего продемонстрировать регулярные выражения в языке Java- Script. Скопируйте контейнер <script > </script>, приведенный ниже на рисунке, в текстовый редактор, например, WordPad. Сохраните файл как текстовый с расширением .html и откройте его любым браузером. В его окне появится фраза "Регулярные выражения" (рисунок 8.6).
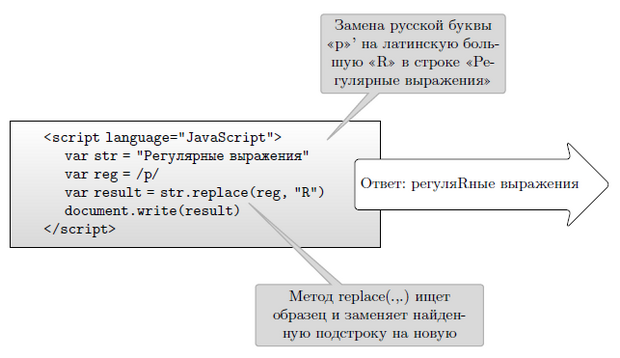
Обратите внимание на то, что шаблон, состоящий из единственной кириллической буквы "р" задан не совсем стандартным способом.
8.11 Хранение деревьев и сетей в таблицах
Для работы с деревьями необходимо вводить в SQL рекурсию, либо использовать процедурные расширения языка.
Простейшая разметка, позволяющая хранить дерево в одной таблице, была рассмотрена на примере таблицы emp. Однако, для полноценной работы с деревьями необходимо ещё реализовать такие действия, как удаление, добавление ветвей, поиск в глубину и ширину и другие. Необходимо работать с лесами деревьев. Поэтому используются другие способы моделирования деревьев, в том числе двухтабличные.
Для моделирования сетей необходимо представлять дуги и узлы, установив их инцидентности и, может быть, выделив отдельные столбцы для записи меток.
В последние годы пропагандируется подход к СУБД, при котором необходимо не моделировать одни структуры данных в других, а реализовывать каждую модель данных непосредственно, добиваясь максимальной эффективности.
Подробнее с представлениями деревьев и сетей в SQL можно познакомиться в книге Джо Селко "SQL для профессионалов. Программирование". М.: "Лори", 2004.