Иерархические модели данных. Деревья в СУБД Cache
3.3.2 Навигация по данным
В иерархической модели данных для работы с базой необходимо, прежде всего, обеспечить навигацию по данным. Это означает, что всегда можно определить, в какой структуре, в каком элементе данных находится система управления базой и как попасть в нужное место. Для программной навигации необходимо хранить метаданные в словаре. В примерах предыдущего раздела метаданные хранились в глобалах, а процедурная часть словаря проработана не была.
В деревьях Cache навигация осуществляется на физическом уровне. Необходимо обеспечить движение в ширину (функция $ORDER) и движение в глубину (функция $QUERY). При конструировании глобалов их узлы создаются и удаляются командами SET и KILL. Копирование поддеревьев обеспечивает команда MERGE.
Существуют функции, поставляющие дополнительную информацию, необходимую для обеспечения навигации:
- какой тип имеет узел (функция $DATA), сколько индексов у переменной (функция $QLENGTH);
- какое значение имеет указанный индекс (функция $QSUBSCRIPT);
- каково значение узла (функция $GET)
Начнём с получения вспомогательных данных.
Определение типа узла, уровня дерева, извлечение индекса и значения
Узлы можно характеризовать двумя признаками — наличием потомков и наличием значений. Если у узла нет потомков, но есть значение, то это листовой узел (на рисунке 3.22 — узлы a(2), a(1,1,1)). Если у узла есть потомки и значения, то это либо корень дерева, либо реальный промежуточный узел (узлы a, a(1)). Узел, имеющий потомков, но не имеющий значений — виртуальный (узел a(1,1)).
Тип узла определяет функция $DATA. Её значения сведены в таблицу 3.3
| Потомки | Значение узла | Код | Значение $DATA |
| 0 | 0 | 00 | 0 |
| 0 | 1 | 01 | 1 |
| 1 | 0 | 10 | 10 |
| 1 | 1 | 11 | 11 |
Cache не печатает ведущие (стоящие слева) нули. Поэтому возвращаются значения $DATA такие, как указано в последнем столбце таблицы.
В следующую таблицу 3.4 сведены варианты условий, проверяемых функцией $DATA.
| Условие | Значение $DATA | Запись условий |
| Потомки имеются | 10,11 | $DATA(узел)\10 |
| Значения имеются | 1,11 | $DATA(узел)#10 |
| Узел не существует | 0 | $DATA(узел)=0 |
| Узел виртуальный | 10 | $DATA(узел)=10 |
| Узел существует | 1,10,11 | $DATA(узел) |
Создадим локал с древесной структурой и проверим типы узлов с помощью функции $DATA (листинг 3.38).
USER>S a="", a(1)="A", a(2)="B", a(1,1,1)="C" USER>W $D(a),?10,$D(a(1)),?20,$D(a(2)),?30,$D(a(1,1,1)) 11 11 1 1 USER>W $D(a(1,1)) 10Пример 3.38. Проверка типа узла функцией $DATA
Уровень узла, то есть число индексов в записи узла определяется функцией $QL[ENGTH]. Корень дерева имеет уровень 0 (у него нет индексов), на уровне 1 находятся узлы с одним индексом и т. д.
Для только что введенного дерева, просмотрим уровень всех узлов (листинг 3.39).
Функция $QL не просматривает реального узла, а только изучает текст своего аргумента. Поэтому можно определить глубину несуществующего узла несуществующего дерева (листинг 3.39рисунок 3.54, последняя командная строка).
USER>S a="", a(1)="A", a(2)="B", a(1,1,1)="C"
USER>W $QL("a"),?10,$QL("a(1)"),?20,$QL("a(1,1)")
0 1 2
USER>W $QL("a(1,1,1)")
3
USER>K W $QL("a(2,5)")
2
Пример
3.39.
Функция $QLENGTH
Функция $QS[UBSCRIPT] работает с полным именем переменной, в том числе извлекает индексы.
Полное имя включает имя области имён, которое окружается символами "|" и "|". Записывают его между знаком "^" и именем переменной с индексами (листинг 3.40).
Частные случаи команды:
- $QS("имя",-1) возвращает окружение, если оно есть в полном имени;
- $QS("имя",0) возвращает имя;
- $QS("имя",n), где n > 1 возвращает индекс, если он есть, и пустую строку, если его нет.
USER>S ^a(1)=77
USER>ZN "%SYS"
%SYS>S a=^|"USER"|a(1) w a
77
%SYS>W $QS("^|""USER""|a(1)", -1)
USER
%SYS>W $QS("^|""USER""|a(1)", 0)
^a
%SYS>W $QS("^|""USER""|a(1)", 1)
1
%SYS>W $QS("^|""USER""|a(1)", 2)
%SYS>
Пример
3.40.
Полное имя
Функция $G[ET] (аргумент) возвращает значение узла (листинг 3.41). Если аргумент отсутствует, вернётся пустая строка.
USER>K y S a="0" a(1)="B" USER>W "a=",$G(a),?10,"a(1)=",$G(a(1)),?20,"a(y)=",$G(y) a=0 a(1)=B a(y)=Пример 3.41. Функция $GET
Неполная глобальная ссылка
Почти все команды или функции, обращающиеся к глобалам, изменяют указатель, называемый индикатором неполной глобальной ссылки. Он запоминает предка последнего узла, к которому производилось обращение.
В программе неполная глобальная ссылка записывается как знак """, за которым в круглых скобках следуют индексы, которые должны быть добавлены к индексам, хранящимся в индикаторе.
Примеры использования неполной глобальной ссылки приведены в листинге 3.42.
USER>S ^a="",^a(1)="A",^a(2)="B",^a(1,1)="C" USER>S ^a(1,1,1)="D",^a(1,1,2)="E" USER>S x=^a(1) w ^(2) B USER>S x=^a(1,1,1) w ^(2) EПример 3.42. Неполная глобальная ссылка
Неполная глобальная ссылка становится не определённой после ссылки на неиндексированную переменную и после вызова функции $QUERY, которая будет описана в следующем разделе. Там же станет понятно, что неполная глобальная ссылка хорошо работает вместе с функцией $ORDER.
Последняя функция $NA[ME] возвращает имя с вычисленными индексами. Более точно,
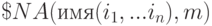 ,
,
где  —число, вернёт:
—число, вернёт:
при  —только имя без индекса;
—только имя без индекса;
при 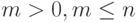 —имя с n индексами;
—имя с n индексами;
при  —ошибка;
—ошибка;
при  —то же, что
—то же, что  .
.
Следует помнить, что обращения к узлу не происходит. Он может вообще не существовать.
Обратите внимание на то, что глобал при записи сокращается за счёт удаления повторяющихся значений индексов. Рассмотрим пример из документации Cache. Глобал:
^Data(1999) = 100 ^Data(1999,1) = "January" ^Data(1999,2) = "February" ^Data(2000) = 300 ^Data(2000,1) = "January" ^Data(2000,2) = "February"
будет храниться примерно в таком виде:
Data(1999):100|1:January|2:February|2000:300|1:January| 2:February|...
Такая запись может уменьшить количество читаемых блоков памяти.