Иерархические модели данных. Деревья в СУБД Cache
Получив общее представление о базах данных и освоив первую модель данных ("сущность —связь"), можем приступить к изучению других моделей данных. В этой главе мы бегло рассмотрим иерархическую и сетевую модели в их старых реализациях, относящихся к 70-м - 80-м годам прошлого века, и, подробно, современную иерархическую модель, используемую в СУБД Cache. В следующих главах с разной степенью подробности будут изучаться объектная, объектно-реляционная и другие модели. Подобное изобилие не должно пугать. Во-первых, они всё равно существуют, нравится ли нам это или нет. Во-вторых, мы освоим отображения моделей, что позволит "свернуть" знания, выработать единый взгляд на базы данных, независимо от используемых в них моделей данных.
Иерархии так широко распространены в моделях окружающей нас действительности, что профессионал в области баз данных не может без них обойтись. Если вы не будете работать с иерархическими моделями данных, то уж моделировать иерархии в рамках используемых моделей вам придется обязательно.
3.1 Иерархическая и сетевая модели
Возможно, где-нибудь вы прочли о том, что иерархическая модель была первой реализованной в базах данных моделью. Это так. Обычно за этой фразой следует утверждение о том, что иерархическая модель представляет только исторический интерес, или о том, что иерархические базы данных в настоящее время не существуют. Вот это уже неправда. Давайте разберемся.
Прежде всего, иерархии настолько распространены, что трудно представить игнорирующую их модель сколько-нибудь интересного фрагмента Мира.
Во-вторых, в информатике иерархические структуры данных встречаются на каждом шагу. Достаточно вспомнить структуру каталогов нашего компьютера или любого сайта Интернет.
В этом разделе будут бегло рассмотрены не иерархические и сетевые модели вообще, а те ограниченные их варианты, которые доминировали на рынке баз данных в 60-е и 70-е годы прошлого века. В настоящее время иерархии чаще всего связаны с XML, либо эмулируются в других моделях, например, реляционной, а сетевые модели это скорее всего семантические сети.
Зачем нужно что-то знать об устаревших моделях? По трём причинам. Во-первых, мы по возможности будем вырабатывать единый подход к любым моделям данных и строить отображения между ними. Для этого нужно знать сами модели. Точное представление иерархической, сетевой и реляционной моделей в СУБД Cache позволит нам рассматривать их отображения в "Объектные модели данных" . Во-вторых, для правильного понимания современного состояния дел полезно иметь какое-то представление о прошлом. В-третьих, методы доступа к данным до сих пор во многом основываются на разработках, выполненных в рамках тех старых моделей.
Помня о том, что само понятие модели данных появилось в связи с разработкой реляционной модели, перечислим основные особенности реализаций ранних моделей данных:
- Доступ к данным мог быть выполнен только на уровне записей путём явной навигации по схеме базы. Использовались языки программирования общего назначения, расширенные функциями доступа к хранимым данным.
- Не существовало средств оптимизации доступа к данным. Не поддерживалось ничего из того, что в настоящее время называется администрированием базы данных.
Конечно, перечисленные особенности относятся скорее к реализациям, чем к самим моделям. Тем не менее, классические сетевая и иерархическая модели вошли в историю именно с такими недостатками.
3.1.1 Сетевая модель
Существовало несколько определений сетевой модели данных. В некоторых допускались бинарные связи "многие ко многим". В варианте, предложенном CODASYL, допускаются только связи типов 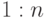 и следовательно
и следовательно 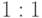 . Это представление и будет рассмотрено.
. Это представление и будет рассмотрено.
Сетевая модель строится из элементов данных, типов записей и типов наборов. Как станет понятно в следующих главах, их аналогами в реляционной модели являются атрибут, отношение и связь между отношениями, соответственно.
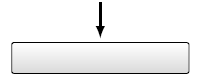
Графически такая сеть представляется диаграммами, в которых прямоугольники изображают типы записей, а стрелки, имеющие наименования, типы набора. Для связи типа 1 : n между двумя типами записей стрелка должна исходить от типа, называемого владельцем набора, к типу, называемому членом набора (рисунок 3.1).
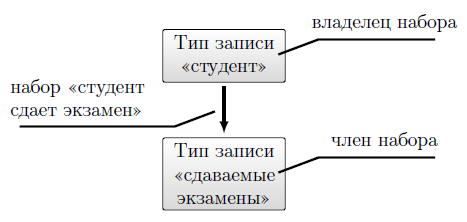
Пожалуйста, не путайте наборы значений, введённых в "Модель сущность-связь" , и рассматриваемые здесь типы наборов, объединяющие типы записей.
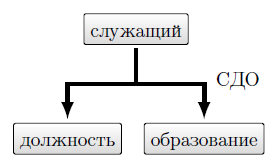
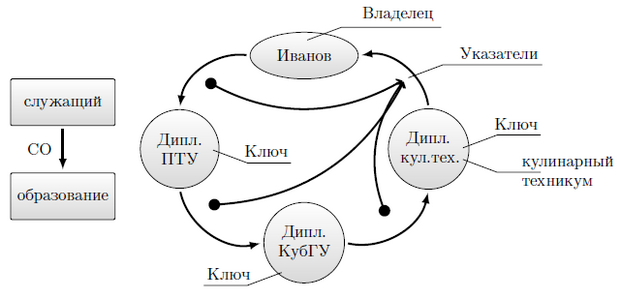
Заметим, что аналоги типа набора известны и в языках программирования общего назначения. Это записи с повторениями значений элемента данных. Существуют многочленные наборы, у которых на одного владельца набора приходится более одного члена набора (рисунок 3.2), выделен класс сингулярных типов набора (рисунок 3.3), которые используются для объединения записей, не имеющих естественного владельца, либо для включения записей, которые при вводе в базу не имеют естественного владельца, но могут приобрести его впоследствии (при этом, запись перемещается из сингулярного набора в экземпляр набора с новым владельцем записи).
Наборы реализуются программно с помощью указателей, устанавливающих связь между владельцем и членом набора. Для создания связи 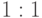 в запись-владелец отношения включается дополнительное поле, представляющее указатель на запись-член отношения. Для организации связей и
в запись-владелец отношения включается дополнительное поле, представляющее указатель на запись-член отношения. Для организации связей и 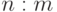 вводится дополнительный тип записей, полями которого являются указатели.
вводится дополнительный тип записей, полями которого являются указатели.
В сетевой модели тип записи может быть членом нескольких наборов. В одних он может играть роль владельца набора, а в других — роль члена набора. В этом случае вводится несколько дополнительных групп указателей, а в типе-владельце набора добавляют несколько полей, указывающих на эти группы.
В итоге множество типов записей и типов связей между ними образует сетевую структуру представляемую ориентированным графом. Вершины этого графа —типы записей, его дуги, направленные от владельца к члену набора, — связи между типами записей. Операции над данными в сетевой модели реализуются через действия со списковыми структурами.
Для того чтобы понять, какие проблемы возникают при работе со списковыми структурами рассмотрим два варианта реализации указателей: с указателем следующей записи и с массивом указателей.
Вариант с указателем следующей записи (рисунок 3.4) обеспечивает последовательный доступ к записям-членам набора. По экземпляру записи-владельца набора обеспечивается последовательный просмотр записей-членов наборов.
Если удалить запись, то в предыдущей записи необходимо скорректировать указатель. Это недостаток. Достоинство —экономия памяти.
Вариант с массивом указателей отличается независимостью указателей, но увеличивает их число (рисунок 3.5).
Из-за общности сетевой модели в ней может быть представлена любая ER-диаграмма. К недостаткам сетевой модели можно отнести сложность получаемой на её основе концептуальной схемы и трудность её восприятия пользователем.
3.1.2 Иерархическая модель
Реализация наборов в иерархической модели, как и в сетевой, может осуществляться с помощью указателей. Иерархическая модель отличается от сетевой модели рядом особенностей. Многочленные наборы определяют отношения соподчиненности. Тип —владелец набора называется предком, подчиненный тип —потомком. Особенности иерархической модели:
- Иерархия начинается с единственного корневого узла.
- Каждый узел некоторого уровня соединён с единственным узлом предыдущего уровня и, может быть, с несколькими узлами следующего уровня.
- Доступ к каждому узлу, за исключением корневого, возможен только через исходный узел. Выборка каждого узла, представленного в иерархии, осуществляется через цепь исходных узлов, образующих путь от корня к выбираемому узлу.
- Количество экземпляров узлов каждого уровня не ограничено.
- В графе дерева отсутствуют циклы.
- На низших уровнях дерева могут существовать зависимые узлы. В этом случае устанавливаются дополнительные горизонтальные связи между узлами нескольких уровней.
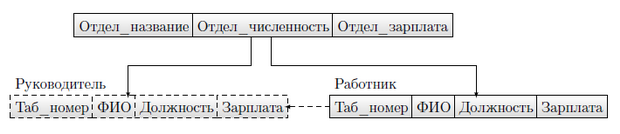
Пример иерархической модели приведен на рисунках 3.6 и 3.7. Штриховыми линиями выделены виртуальные узлы и связи, которые обеспечивают физическое хранение единственного экземпляра записи, воспринимаемого на логическом уровне одновременно как экземпляр типов "Руководитель" и "Работник".

Иерархическая база данных может представлять совокупность нескольких деревьев. В частности, некоторые из них могут описывать структуры данных, а другие — сами данные, размещённые в этих структурах. Дополнительные горизонтальные ссылки могут существовать между узлами нескольких уровней, в том числе находящихся в разных деревьях. Такие ссылки позволяют использовать один набор записей в нескольких деревьях, не дублируя его. Широкое распространение иерархической модели было обусловлено, в частности тем, что большинство организационных систем в то время имели иерархическую структуру.
Программы, реализующие операции иерархической модели, существенно проще, чем аналогичные программы для сетевой модели. При выполнении операций манипулирования данными в иерархической модели следует учитывать, что узел потомка не может существовать при удалении предка. Недостатки у иерархической модели те же, что у сетевой, плюс недостатки, связанные с ограниченностью связей.