
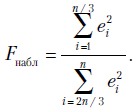

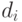
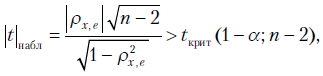
 и с числом степеней свободы
и с числом степеней свободы  .
.
|
В дисциплине "Основы эконометрики" тест 6 дается по теме 7. |
Опубликован: 10.09.2016 | Доступ: свободный | Студентов: 976 / 175 | Длительность: 15:27:00
Тема: Экономика
Специальности: Менеджер, Руководитель, Экономист, Бухгалтер
Лекция 4:
Гетероскедастичность моделей, ее обнаружение и методы устранения
Ключевые слова: связь, значимость, гипотеза, значение, гетероскедастичность, график, метода наименьших квадратов, точность, матрица, дисперсия, ранг, вектор, доказательство, определитель, равенство
4.1. Понятие гетероскедастичности модели
Одним из предположений теории наименьших квадратов является предположение, что все ошибки 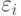 наблюдений имеют одинаковые дисперсии. Однако при моделировании реальных экономических процессов это предположение выполняется далеко не всегда. Посмотрев на ряд показателей урожайности пшеницы в США с 1866 по 1988 гг. (рис. 4.1), можно предположить, что с начала XX в. с повышением уровня агротехники, индустриализацией и химизацией сельского хозяйства росли не только средняя урожайность, но и абсолютные колебания урожаев вокруг среднего уровня. Если описать изменения среднего уровня урожайности некоторым уравнением регрессии, то ошибки наблюдений будут возрастать с течением времени.
наблюдений имеют одинаковые дисперсии. Однако при моделировании реальных экономических процессов это предположение выполняется далеко не всегда. Посмотрев на ряд показателей урожайности пшеницы в США с 1866 по 1988 гг. (рис. 4.1), можно предположить, что с начала XX в. с повышением уровня агротехники, индустриализацией и химизацией сельского хозяйства росли не только средняя урожайность, но и абсолютные колебания урожаев вокруг среднего уровня. Если описать изменения среднего уровня урожайности некоторым уравнением регрессии, то ошибки наблюдений будут возрастать с течением времени.
Предположение о том, что ошибки наблюдений имеют одинаковые дисперсии, называется гомоскедастичностью. Если же ошибки наблюдений имеют разные дисперсии, то говорят о гетероскедастичности наблюдений.
В связи с этим возникают три вопроса:
- как правильно провести диагностику (тестирование) существования гетероскедастичности;
- какие следствия для оценок получаемых по методу наименьших квадратов влечет гетероскедастичность;
- как решать проблему гетероскедастичности?
4.2. Тестирование гетероскедастичности
В примере урожайности зерновых культур в России за 200 лет (см. рис. 3.1) присутствие гетероскедастичности не вызывает сомнений. Однако во многих случаях обнаружение гетероскедастичности визуально не столь очевидно. Чтобы определить наличие гетероскедастичности, применяют различные тесты.
Все тесты основаны на предположении о наличии связи между дисперсиями остатков моделей и объясняющими переменными или расчетными значениями зависимой переменной в случае гетероскедастичности.
Эта связь обнаруживается с помощью:
- коэффициента ранговой корреляции в тесте ранговой корреляции Спирмена;
- предположения о пропорциональности стандартных отклонений
 и зависимой переменной
и зависимой переменной  в тесте Голдфелда - Квандта;
в тесте Голдфелда - Квандта; - построения различных линейных и нелинейных регрессий
 на объясняющие переменные или степени зависимой переменной и проверки значимости полученных коэффициентов регрессии в тестах Анскомба, Рамсея, Уайта и Глейзера.
на объясняющие переменные или степени зависимой переменной и проверки значимости полученных коэффициентов регрессии в тестах Анскомба, Рамсея, Уайта и Глейзера.
В асимптотическом тесте Бреуша и Пагана проверяется по критерию 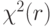 значимость величины
значимость величины 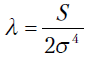 , где
, где 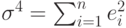 , а
, а  - сумма квадратов, объясняемая регрессией произвольного вида
- сумма квадратов, объясняемая регрессией произвольного вида 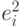 на некоторые переменные
на некоторые переменные  .
.
Тест Голдфелда - Квандта исходит из того, что ошибки регрессии 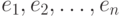 являются выборочными значениями нормально распределенной случайной величины. В случае гомоскедастичности первая треть наблюдений и последняя треть наблюдений имеют одинаковые дисперсии. Эта гипотеза проверяется с помощью критерия Фишера - Снедекора.
являются выборочными значениями нормально распределенной случайной величины. В случае гомоскедастичности первая треть наблюдений и последняя треть наблюдений имеют одинаковые дисперсии. Эта гипотеза проверяется с помощью критерия Фишера - Снедекора.
Строится наблюдаемое значение критерия
Если 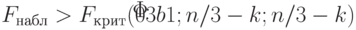 , где
, где  - уровень значимости,
- уровень значимости,  - число объясняющих переменных (регрессоров),
- число объясняющих переменных (регрессоров),  - табличное значение критерия Фишера, то гипотеза о гомоскедастичности отвергается на -процентном уровне. В противном случае нет оснований отвергнуть нулевую гипотезу о гомоскедастичности остатков модели.
- табличное значение критерия Фишера, то гипотеза о гомоскедастичности отвергается на -процентном уровне. В противном случае нет оснований отвергнуть нулевую гипотезу о гомоскедастичности остатков модели.
Тест ранговой корреляции Спирмена не требует предположения о нормальности распределения регрессионных остатков. Проверяется лишь предположение, что в случае гетероскедастичности остатки коррелированны со значениями регрессоров или расчетными значениями зависимой переменной. Для нахождения коэффициента ранговой корреляции следует предварительно ранжировать наблюдения по одной из объясняющей переменной 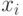 или расчетные значения зависимой переменной
или расчетные значения зависимой переменной  и ранжировать остатки
и ранжировать остатки 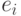 . Далее вычисляется выборочное значение коэффициента корреляции Спирмена по формуле
. Далее вычисляется выборочное значение коэффициента корреляции Спирмена по формуле
После этого проверяется значимость коэффициента корреляции. Гетероскедастичность считается доказанной на уровне значимости , если наблюдаемое значение критерия Стьюдента
Рассмотрим график изменения урожайности пшеницы в США с 1866 по 1998 г. (см. рис. 4.1). Аппроксимируем ряд моделью вида  . Выполнив расчеты в модуле "Нелинейная регрессия" пакета STATISTICA, получим уравнение
. Выполнив расчеты в модуле "Нелинейная регрессия" пакета STATISTICA, получим уравнение
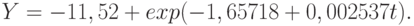
В модуле "Непараметрические статистики", сохранив предварительно остатки и расчетные значения модели, рассчитаем значение коэффициента ранговой корреляции Спирмена и его значимость (табл. 4.1).
Таблица 4.1
Результаты таблицы свидетельствуют о значимости коэффициента Спирмена, а следовательно, о гетероскедастичности остатков модели.