Обучение с учителем: Распознавание образов
Двухслойные персептроны
Возможности линейного дискриминатора весьма ограничены. Он способен правильно решать лишь ограниченный круг задач - когда классы, подлежащие классификации линейно-разделимы, т.е. могут быть разделены гиперплоскостью ( рисунок 3.2).
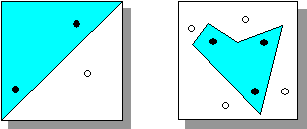
В d-мерном пространстве гиперплоскость может разделить произвольным образом лишь d+1 точки. Например, на плоскости можно произвольным образом разделить по двум классам три точки, но четыре - в общем случае уже невозможно (см. рисунок 3.2). В случае плоскости это очевидно из приведенного примера, для большего числа измерений - следует из простых комбинаторных соображений. Если точек больше чем d+1 всегда существуют такие способы их разбиения по двум классам, которые нельзя осуществить с помощью одной гиперплоскости. Однако, этого можно достичь с помощью нескольких гиперплоскостей.
Для решения таких более сложных классификационных задач необходимо усложнить сеть, вводя дополнительные (их называют скрытыми) слои нейронов, производящих промежуточную предобработку входных данных таким образом, чтобы выходной нейрон-классификатор получал на свои входы уже линейно-разделимые множества.
Причем легко показать, что, в принципе, всегда можно обойтись всего лишь одним скрытым слоем, содержащим достаточно большое число нейронов. Действительно, увеличение скрытого слоя повышает размерность пространства, в котором выходной нейрон производит дихотомию, что, как отмечалось выше, облегчает его задачу.
Не вдаваясь в излишние подробности резюмируем результаты многих исследований аппроксимирующих способностей персептронов.
- Сеть с одним скрытым слоем, содержащим H нейронов со ступенчатой функцией активации, способна осуществить произвольную классификацию Hd точек d-мерного пространства (т.е. классифицировать Hd примеров).
- Одного скрытого слоя нейронов с сигмоидной функцией активации достаточно для аппроксимации любой границы между классами со сколь угодно высокой точностью.
Для задач аппроксимации последний результат переформулируется следующим образом:
- Одного скрытого слоя нейронов с сигмоидной функцией активации достаточно для аппроксимации любой функции со сколь угодно высокой точностью. (Более того, такая сеть может одновременно аппроксимировать и саму функцию и ее производные.)
Точность аппроксимации возрастает с числом нейронов скрытого слоя. При H нейронах ошибка оценивается как 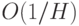 .
Эта оценка понадобится нам в дальнейшем.
.
Эта оценка понадобится нам в дальнейшем.
Персептрон Розенблатта
Исторически, первые персептроны, предложенные Фрэнком Розенблаттом в 1958 г., имели два слоя нейронов. Однако, собственно обучающимся был лишь один, последний слой. Первый (скрытый) слой состоял из нейронов с фиксированными случайными весами. Эти, по терминологии Розенблатта - ассоциирующие, нейроны получали сигналы от случайно выбранных точек рецепторного поля. Именно в этом признаковом пространстве персептрон осуществлял линейную дискриминацию подаваемых на вход образов (см. рисунок 3.3).
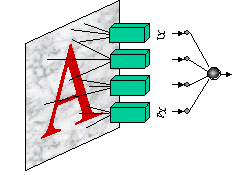
Рис. 3.3. Персептрон Розенблатта имел один слой обучаемых весов, на входы которого подавались сигналы с d = 512 ассоциирующих нейронов со случайными фиксированными весами, образующие признаковое пространство для 400-пиксельных образов
Результаты своих исследований Розенблатт изложил в книге "Принципы нейродинамики: Персептроны и теория механизмов мозга". Уже из самого названия чувствуется какое большое значение придавалось этому относительно простому обучающемуся устройству. Однако, многочисленные эксперименты показали неровный характер обучаемости персептронов. Некоторые задачи решались относительно легко, тогда как другие - вообще не поддавались обучению. В отсутствие теории объяснить эти эксперименты и определить перспективы практического использования персептронов было невозможно.
Подобного рода теория появилась к 1969г. с выходом в свет книги Марвина Минского и Сеймура Пейперта "Персептроны". Минский и Пейперт показали, что если элементы скрытого слоя фиксированы, их количество либо их сложность экспоненциально возрастает с ростом размерности задачи (числа рецепторов). Тем самым, теряется их основное преимущество - способность решать задачи произвольной сложности при помощи простых элементов.
Реальный же выход состоял в том, чтобы использовать адаптивные элементы на скрытом слое, т.е. подбирать веса и первого и второго слоев. Однако в то время этого делать не умели. Каким же образом находить синаптические веса сети, дающие оптимальную классификацию входных векторов?