Обучение с учителем: Распознавание образов
Градиентное обучение многослойных персептронов
Градиентное обучение
Наиболее общим способом оптимизации нейросети является итерационная (постепенная) процедура подбора весов, называемая обучением, в
данном случае - обучением с учителем, поскольку опирается на обучающую выборку примеров 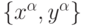 , например - примеров правильной классификации.
, например - примеров правильной классификации.
Когда функционал ошибки задан, и задача сводится к его минимизации, можно предложить, например, следующую итерационную процедуру
подбора весов: 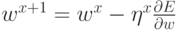 или, что то же самое:
или, что то же самое:
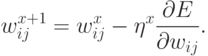
Здесь  - темп обучения на шаге
- темп обучения на шаге 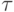 . Можно показать, что постепенно уменьшая темп обучения, например по закону
. Можно показать, что постепенно уменьшая темп обучения, например по закону 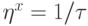 , описанная выше
процедура приводит к нахождению локального минимума ошибки.
, описанная выше
процедура приводит к нахождению локального минимума ошибки.
Исторически наибольшую трудность на пути к эффективному правилу обучения многослойных персептронов вызвала процедура эффективного
расчета градиента функции ошибки  . Дело в том, что ошибка сети определяется по ее выходам, т.е. непосредственно связаная лишь с
выходным слоем весов. Вопрос состоял в том, как определить ошибку для нейронов на скрытых слоях, чтобы найти производные по
соответствующим весам. Нужна была процедура передачи ошибки с выходного слоя к предшествующим слоям сети, в направлении обратном
обработке входной информации. Поэтому такой метод, когда он был найден, получил название метода обратного распространения ошибки.
. Дело в том, что ошибка сети определяется по ее выходам, т.е. непосредственно связаная лишь с
выходным слоем весов. Вопрос состоял в том, как определить ошибку для нейронов на скрытых слоях, чтобы найти производные по
соответствующим весам. Нужна была процедура передачи ошибки с выходного слоя к предшествующим слоям сети, в направлении обратном
обработке входной информации. Поэтому такой метод, когда он был найден, получил название метода обратного распространения ошибки.
Метод обратного распространения ошибки
Ключ к обучению многослойных персептронов оказался настолько простым и очевидным, что, как оказалось, неоднократно переоткрывался.
Между тем, в случае дифференцируемых функций активации рецепт нахождения производных по любому весу сети дается т.н. цепным правилом дифференцирования, известным любому первокурснику. Суть метода back-propagation - в эффективном воплощении этого правила.
Разберем этот ключевой для нейрокомпьютинга метод несколько подробнее. Обозначим входы n-го слоя нейронов ![x^{[n]}_j](/sites/default/files/tex_cache/bca605d1820b57c1ac5cf7f74a6d7f24.png) . Нейроны этого
слоя вычисляют соответствующие линейные комбинации:
. Нейроны этого
слоя вычисляют соответствующие линейные комбинации:
![a^{[n]}_j=\sum_jw^{[n]}_{ij}x^{[n]}_j](/sites/default/files/tex_cache/fea56a06872bd97f606e748bb2c1c3f4.png)
![x^{[n+1]}_j=f(a^{[n]}_i).](/sites/default/files/tex_cache/1a441da98cbbd5696c76303fb919b0f9.png)
![\frac{\partial{E}}{\partial{w^{[n]}_{ij}}}=\frac{\partial{E}}{\partial{a^{[n]}_i}}\frac{\partial{a^{[n]}_i}}{\partial{w^{[n]}_{ij}}}\equiv\delta^{[n]}_ix^{[n]}_j.](/sites/default/files/tex_cache/9c62646bd55b6ec8592e5c4eb3eca18b.png)
![\delta^{[n]}_i](/sites/default/files/tex_cache/4e5db8eaa1a0b21309bd831f0fd31236.png) на значение соответствующего
входа. (Из-за этого, в случае когда веса изменяют по направлению скорейшего спуска
на значение соответствующего
входа. (Из-за этого, в случае когда веса изменяют по направлению скорейшего спуска 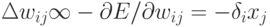 , такое правило обучения называют дельта-правилом.)
, такое правило обучения называют дельта-правилом.)Входы каждого слоя вычисляются последовательно от первого слоя к последнему во время прямого распространения сигнала:
![x^{[n+1]}_i=f\left(\sum_jw^{[n]}_{ij}x^{[n]}_j \right)](/sites/default/files/tex_cache/b5645e9a34ce69b138520eef1801fbbc.png)
![\delta^{[n]}_i=f'(a^{[n]}_i)(\sum_kw^{[n+1]}_{ki}\delta^{[n+1]}_k).](/sites/default/files/tex_cache/0108b720f78b6305bbdc3b5f8ab1a69c.png)
![\frac{\partial{E}}{\partial{a^{[n]}_i}}=\sum_k\frac{\partial{E}} {\partial{a^{[n+1]}_k}}\frac{\partial{a^{[n+1]}_k}}{\partial{x^{[n+1]}_i}}
\frac{\partial{x^{[n+1]}_i}}{\partial{a^{[n+1]}_i}}.](/sites/default/files/tex_cache/02d5963f7d31000298643f4309af6415.png)
Эффективность алгоритма back-propagation
Важность изложенного выше алгоритма back-propagation в том, что он дает чрезвычайно эффективный способ нахождения градиента функции
ошибки  . Если обозначить общее число весов в сети как W, то необходимое для вычисления градиента число операций растет пропорционально W, т.е. этот алгоритм имеет сложность O(W). Напротив, прямое вычисление градиента по формуле
. Если обозначить общее число весов в сети как W, то необходимое для вычисления градиента число операций растет пропорционально W, т.е. этот алгоритм имеет сложность O(W). Напротив, прямое вычисление градиента по формуле
![\frac{\partial{E}}{\partial{w^{[n]}_{ij}}}=\frac{E(w^{[n]}_{ij}+\varepsilon)-E(w^{[n]}_{ij})}{\varepsilon}](/sites/default/files/tex_cache/2e4b261069190e85516fac350db1987d.png)
 ,
что существенно хуже, чем у алгоритма back-propagation.
,
что существенно хуже, чем у алгоритма back-propagation.