Лексическая структура Haskell 98
2.5 Числовые литералы
Перевод:
| десятичный-литерал | 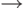 |
цифра{цифра} |
| восьмеричный-литерал | |
восьмиричная-цифра{восьмиричная-цифра} |
| шестнадцатиричный-литерал | |
шестнадцатиричная-цифра{шестнадцатиричная-цифра} |
| целый-литерал | |
десятичный-литерал |
| | | 0o восьмиричный-литерал | 0O восьмиричный-литерал | |
| | | 0x шестнадцатиричный-литерал | 0X шестнадцатиричный-литерал | |
| литерал-с-плавающей-точкой | |
десятичный-литерал . десятичный-литерал [экспонента] |
| | | десятичный-литерал экспонента | |
| экспонента | |
(e | E) [+ | -] десятичный-литерал |
Есть два различных вида числовых литералов: целые и с плавающей точкой. Целые литералы можно задавать в десятичной (по умолчанию), восьмиричной (начинается с 0o или 0O ) или шестнадцатиричной записи (начинается с 0x или 0X ). Литералы с плавающей точкой всегда являются десятичными. Литерал с плавающей точкой должен содержать цифры и перед, и после десятичной точки; это гарантирует, что десятичная точка не будет ошибочно принята за другое использование символа точка. Отрицательные числовые литералы рассматриваются в разделе "Выражения" . Типизация числовых литералов рассматривается в разделе "Предопределенные типы и классы" .
2.6 Символьные и строковые литералы
Перевод:
Символьные литералы записываются между одинарными кавычками, как например 'a', а строки - между двойными кавычками, как например "Hello".
Эскейп-коды можно использовать в символах и строках для представления специальных символов. Обратите внимание, что одинарную кавычку ' можно использовать внутри строки как есть, но для того, чтобы использовать ее внутри символа, необходимо записать перед ней символ обратной косой черты ( \ ). Аналогично, двойную кавычку " можно использовать внутри символа как есть, но внутри строки она должна предваряться символом обратной косой черты. \ всегда должен предваряться символом обратной косой черты.
Категория charesc (символ-эскейп) также включает переносимые представления для символов "тревога" ( \a ), "забой" ( \b ), "перевод страницы" ( \f ), "новая строка" ( \n ), "возврат каретки" ( \r ), "горизонтальная табуляция" ( \t ) и "вертикальная табуляция" ( \v ).
Эскейп-символы для кодировки Unicode, включая символы управления, такие как X, также предусмотрены. Числовые эскейп-последовательности, такие как \137, используются для обозначения символа с десятичным представлением 137; восьмиричные (например, \o137 ) и шестнадцатиричные (например, \x37 ) представления также допустимы.
Согласующиеся с правилом "максимального потребления", числовые эскейп-символы в строках состоят изо всех последовательных цифр и могут иметь произвольную длину. Аналогично, единственный неоднозначный эскейп-код ASCII "\SOH" при разборе интерпретируется как строка длины 1. Эскейп-символ \& предусмотрен как "пустой символ", чтобы позволить создание таких строк, как "\137\&9" и "\SO\&H" (обе длины два). Поэтому "\& " эквивалентен " ", а символ '\&' недопустим. Дальнейшие эквивалентности символов определены в разделе "Предопределенные типы и классы" .
Строка может включать "разрыв" - две обратные косые черты, окруженные пробельными символами, которые игнорируются. Это позволяет записывать длинные программные строки на более чем одной строке файла, для этого надо добавлять обратную косую черту (бэкслэш) в конец каждой строки файла и в начале следующей. Например,
"Это бэкслэш \\, так же как \137 - \
\ числовой эскейп-символ и \^X - управляющий символ."Строковые литералы в действительности являются краткой записью для списков символов (см. раздел "Выражения" ).
2.7. Размещение
В Haskell разрешено опускать фигурные скобки и точки с запятой, используемые в нескольких правилах вывода грамматики, посредством использования определенного размещения текста программы с тем, чтобы отразить ту же самую информацию. Это позволяет использовать и зависящий от размещения текста, и не зависящий от размещения текста стили написания кода, которые можно свободно смешивать в одной программе. Поскольку не требуется располагать текст определенным образом, программы на Haskell можно непосредственно генерировать другими программами.
Влияние размещения текста программы на смысл программы на Haskell можно полностью установить путем добавления фигурных скобок и точек с запятой в местах, определяемых размещением. Смысл такого дополнения программы состоит в том, чтобы сделать ее не зависимой от размещения текста.
Будучи неофициально заявленными, фигурные скобки и точки с запятой добавляются следующим образом. Правило размещения текста (или правило "вне игры") вступает в силу всякий раз, когда открытая фигурная скобка пропущена после ключевого слова where, let, do или of. Когда это случается, отступ следующей лексемы (неважно на новой строке или нет) запоминается, и вставляется пропущенная открытая фигурная скобка (пробельные символы, предшествующие лексеме, могут включать комментарии). Для каждой последующей строки выполняется следующее: если она содержит только пробельные символы или больший отступ, чем предыдущий элемент, то это означает, что продолжается предыдущий элемент (ничего не добавляется); если строка имеет тот же отступ, это означает, что начинается новый элемент (вставляется точка с запятой); если строка имеет меньший отступ, то это означает, что эакончился список размещения (вставляется закрывающая фигурная скобка). Если отступ лексемы без фигурных скобок, которая следует непосредственно за where, let, do или of, меньше чем или равен текущему уровню углубления, то вместо начала размещения вставляется пустой список Qquot;{}Qquot; и обработка размещения выполняется для текущего уровня (т.е. вставляется точка с запятой или закрывающая фигурная скобка). Закрывающая фигурная скобка также вставляется всякий раз, когда заканчивается синтаксическая категория, содержащая список размещения; то есть если неправильная лексема встретится в месте, где была бы правильной закрывающая фигурная скобка, вставляется закрывающая фигурная скобка. Правило размещения добавляет закрывающие фигурные скобки, которые соответствуют только тем открытым фигурным скобкам, которые были добавлены согласно этому правилу; явная открытая фигурная скобка должна соответствовать явной закрывающей фигурной скобке. В пределах этих явных открытых фигурных скобок, никакая обработка размещения не выполняется для конструкций вне фигурных скобок, даже если строка выравнена левее (имеет меньший отступ) более ранней неявной открытой фигурной скобки.
В разделе "Синтаксический справочник" дано более точное определение правил размещения.
Согласно этим правилам, отдельный символ новой строки на самом деле может завершить несколько списков размещения. Также эти правила разрешают:
f x = let a = 1; b = 2
g y = exp2
in exp1делая a, b и g частью одного и того же списка размещения.
В качестве примера на риc. 2.1 изображен (несколько запутанный) модуль, а на риc. 2.2 показан результат применения к нему правила размещения. Обратите внимание, в частности, на: (a) строку, начинающую }};pop, в которой завершение предыдущей строки вызывает три применения правила размещения, соответствующих глубине (3) вложенной инструкции where, (b) закрывающие фигурные скобки в инструкции where, вложенной в пределах кортежа и case-выражения, вставленные потому, что был обнаружен конец кортежа, и (c) закрывающую фигурную скобку в самом конце, вставленную из-за нулевого отступа лексемы конца файла.
data Stack a = Empty
| MkStack a (Stack a)
push :: a -> Stack a -> Stack a
push x s = MkStack x s
size :: Stack a -> Int
size s = length (stkToLst s) where
stkToLst Empty = []
stkToLst (MkStack x s) = x:xs where xs = stkToLst s
pop :: Stack a -> (a, Stack a)
pop (MkStack x s)
= (x, case s of r -> i r where i x = x) - (pop Empty) является ошибкой
top :: Stack a -> a
top (MkStack x s) = x - (top Empty) является ошибкой
Листинг
2.1.
Пример программы
module AStack( Stack, push, pop, top, size ) where
{data Stack a = Empty
| MkStack a (Stack a)
;push :: a -> Stack a -> Stack a
;push x s = MkStack x s
;size :: Stack a -> Int
;size s = length (stkToLst s) where
{stkToLst Empty = []
;stkToLst (MkStack x s) = x:xs where {xs = stkToLst s
}};pop :: Stack a -> (a, Stack a)
;pop (MkStack x s)
= (x, case s of {r -> i r where {i x = x}}) - (pop Empty) является ошибкой
;top :: Stack a -> a
;top (MkStack x s) = x - (top Empty) является ошибкой
Листинг
2.2.
Пример программы, дополненной размещением