Предопределенные типы и классы
6.1. Стандартные типы Haskell
Эти типы определены в Haskell Prelude. Числовые типы описаны в разделе "Предопределенные типы и классы" . Там, где это возможно, дается определение типа на Haskell . Некоторые определения могут не быть полностью синтаксически правильными, но они верно передают смысл лежащего в основе типа.
6.1.1. Булевский тип
data Bool = False | True deriving
(Read, Show, Eq, Ord, Enum, Bounded)Булевский тип Bool является перечислением. Основные булевские функции - это && (и), || (или) и not (не). Имя otherwise (иначе) определено как True, чтобы сделать выражения, использующие стражи, более удобочитаемыми.
6.1.2. Символы и строки
Символьный тип Char является перечислением, чьи значения представляют собой символы Unicode [11]. Лексический синтаксис для символов определен в разделе "Лексическая структура Haskell 98" ; символьные литералы - это конструкторы без аргументов в типе данных Char. Тип Char является экземпляром классов Read, Show, Eq, Ord, Enum и Bounded. Функции toEnum и fromEnum, которые являются стандартными функциями из класса Enum, соответственно отображают символы в тип Int и обратно.
Обратите внимание, что каждый символ управления ASCII имеет несколько представлений в символьных литералах: в виде числовой эскейп-последовательности, в виде мнемонической эскейп-последовательности ASCII, и представление в виде \^X. Кроме того, равнозначны следующие литералы: \a и \BEL, \b и \BS, \f и \FF, \r и \CR, \t и \HT, \v и \VT и \n и \LF.
Строка - это список символов:
type String = [Char]
Строки можно сократить, используя лексический синтаксис, описанный в разделе "Лексическая структура Haskell 98" . Например, "A string" является сокращением (аббревиатурой) [ 'A',' ','s','t','r', 'i','n','g']
6.1.3. Списки
data [a] = [] | a : [a] deriving (Eq, Ord)
Списки - это алгебраический тип данных для двух конструкторов, имеющих специальный синтаксис, описанных в разделе "Выражения" . Первый конструктор - это пустой список, который обозначается '[]' ("nil"), второй - это ':' ("cons"). Модуль PreludeList (см. раздел "Стандартное начало (Prelude)" ) определяет множество стандартных функций над списком. Арифметические последовательности и описание списка - это два удобных синтаксиса, используемых для записи специальных видов списков, они описаны в разделах "Выражения" и "Выражения" соответственно. Списки являются экземпляром классов Read, Show, Eq, Ord, Monad, Functor и MonadPlus.
6.1.4. Кортежи
Кортежи - это алгебраический тип данных со специальным синтаксисом, описанным в разделе "Выражения" . Тип каждого кортежа имеет один конструктор. Все кортежи являются экземплярами классов Eq, Ord, Bounded, Read, и Show (конечно, при условии, что все их составляющие типы являются экземплярами этих классов).
Нет никакой верхней границы размера кортежа, но некоторые реализации Haskell могут содержать ограничения на размер кортежей и на экземпляры, связанные с большими кортежами. Тем не менее, каждая реализация Haskell должна поддерживать кортежи вплоть до 15 размера, наряду с экземплярами классов Eq, Ord, Bounded, Read и Show. Prelude и библиотеки содержат определения функций над кортежами, таких как zip, для кортежей вплоть до 7 размера.
Конструктор для кортежа записывается посредством игнорирования выражений, соседствующих с запятыми; таким образом, (x,y) и (,) x y обозначают один и тот же кортеж. То же самое относится к конструкторам типов кортежей; таким образом, (Int,Bool,Int) и (,,) Int Bool Int обозначают один и тот же тип.
Следующие функции определены для пар (кортежей 2 размера): fst, snd, curry и uncurry. Для кортежей большего размера подобные функции не являются предопределенными.
6.1.5. Единичный тип данных
data () = () deriving (Eq, Ord, Bounded, Enum, Read, Show)
Единичный тип данных () имеет единственный, отличный от  , член - конструктор без аргументов (). См. также раздел
"Выражения"
.
, член - конструктор без аргументов (). См. также раздел
"Выражения"
.
6.1.6. Типы функций
Функции - это абстрактный тип: никакие конструкторы непосредственно не создают значения функций. В Prelude описаны следующие простые функции: id, const, (.), flip, ($) и until.
6.1.7. Типы IO и IOError
Тип IO указывает на операции, которые взаимодействуют с внешним миром. Тип IO является абстрактным: никакие конструкторы не видны для пользователя. IO является экземпляром классов Monad и Functor. В лекции "Основные операции ввода - вывода" описываются операции ввода - вывода.
Тип IOError является абстрактным типом, который представляет ошибки, вызванные операциями ввода - вывода. Он является экземпляром классов Show и Eq. Значения этого типа создаются различными функциями ввода - вывода. Более подробная информация о значениях в этом описании не представлена. Prelude содержит несколько функций ввода - вывода (определены в разделе "Стандартное начало (Prelude)" ). Гораздо больше функций ввода - вывода содержит часть II.
6.1.8. Другие типы
data Maybe a = Nothing | Just a deriving (Eq, Ord, Read, Show)
data Either a b = Left a | Right b deriving (Eq, Ord, Read, Show)
data Ordering = LT | EQ | GT deriving
(Eq, Ord, Bounded, Enum, Read, Show)Тип Maybe является экземпляром классов Functor, Monad и MonadPlus. Тип Ordering используется функцией compare в классе Ord. Функции maybe и either описаны в Prelude.
6.2. Строгое вычисление
Применение функций в Haskell не является строгим, то есть аргумент функции вычисляется только тогда, когда требуется значение. Иногда желательно вызвать вычисление значения, используя функцию seq:
seq :: a -> b -> b
Функция seq определена уравнениями:

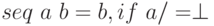
Функция seq обычно вводится для того, чтобы улучшить производительность за счет избежания ненужной ленивости. Строгие типы данных (см. раздел
"Объявления и связывания имен"
) определены в терминах оператора $!. Тем не менее, наличие функции seq имеет важные семантические последствия, потому что эта функция доступна для каждого типа. Как следствие, - это не то же самое, что 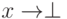 , так как можно использовать seq для того, чтобы отличить их друг от друга. По той же самой причине существование seq ослабляет параметрические свойства Haskell.
, так как можно использовать seq для того, чтобы отличить их друг от друга. По той же самой причине существование seq ослабляет параметрические свойства Haskell.
Оператор $! является строгим (вызываемым по значению) применением, он определен в терминах seq. Prelude также содержит определение оператора $ для выполнения нестрогих применений.
infixr 0 $, $! ($), ($!) :: (a -> b) -> a -> b f $ x = f x f $! x = x `seq` f x
Наличие оператора нестрогого применения $ может казаться избыточным, так как обычное применение (f x) означает то же самое, что (f $ x). Тем не менее, $ имеет низкий приоритет и правую ассоциативность, поэтому иногда круглые скобки можно опустить, например:
f $ g $ h x = f (g (h x))
Это также полезно в ситуациях более высокого порядка, таких как map ($ 0) xs или zipWith ($) fs xs.