2.1. Соглашения об обозначениях
Эти соглашения об обозначениях используются для представления синтаксиса:
| [pattern] |
необязательный |
| {pattern} |
ноль или более повторений |
| (pattern) |
группировка |
| pat1 <I> | pat2 |
разность - элементы, порождаемые с помощью pat, за исключением элементов, порождаемых с помощью pat'
|
| fibonacci |
терминальный синтаксис в машинописном шрифте |
Поскольку синтаксис в этом разделе описывает лексический синтаксис, все пробельные символы выражены явно; нет никаких неявных пробелов между смежными символами. Повсюду используется BNF-подобный синтаксис, чьи правила вывода имеют вид:
| nonterm |
 |
alt1 | alt2 | ... | altn |
| Перевод: нетерминал
|
|
альтернатива1 | альтернатива2 | ... | альтернативаn
|
Необходимо внимательно отнестись к отличию синтаксиса металогических символов, например, | и [...], от конкретного синтаксиса терминалов (данных в машинописном шрифте),например, | и [...], хотя обычно это ясно из контекста.
Haskell использует кодировку символов Unicode [11].
Тем не менее, исходные программы в настоящее время написаны в основном в кодировке символов ASCII, используемой в более ранних версиях Haskell.
Этот синтаксис зависит от свойств символов Unicode, определяемых консорциумом Unicode. Ожидается, что компиляторы Haskell будут использовать новые версии Unicode, когда они станут доступными.
2.2 Лексическая структура программы
| program |
|
{lexeme | whitespace } |
|
lexeme
|
|
qvarid | qconid | qvarsym | qconsym |
| | |
literal | special | reservedop | reservedid |
| literal |
|
integer | float | char | string |
| special |
|
(|)|,|;|[|]|'|{|} |
| whitespace |
|
whitestuff {whitestuff} |
| whitestuff |
|
whitechar | comment | ncomment |
| whitechar |
|
newline | vertab | space | tab | uniWhite |
| newline |
|
return linefeed | return | linefeed | formfeed |
| return |
|
возврат каретки |
| linefeed |
|
перевод строки |
| vertab |
|
вертикальная табуляция |
| formfeed |
|
перевод страницы |
| space |
|
пробел |
| tab |
|
горизонтальная табуляция |
| uniWhite |
|
любой пробельный символ Unicode |
| comment |
|
dashes [any<symbol> {any}] newline |
| dashes |
|
- {-} |
| opencom |
|
{- |
| closecom |
|
-} |
| ncomment |
|
opencom ANYseq {ncomment ANYseq}closecom |
| ANYseq |
|
{ANY}<{ANY}( opencom | closecom ) {ANY}> |
| ANY |
|
graphic | whitechar |
| any |
|
graphic | space | tab |
| graphic |
|
small | large | symbol | digit | special | : | " | ' |
| small |
|
ascSmall | uniSmall | _ |
| ascSmall |
|
a | b | ... | z |
| uniSmall |
|
любая буква Unicode нижнего регистра |
| large |
|
ascLarge | uniLarge |
| ascLarge |
|
A | B | ... | Z |
| uniLarge |
|
любая буква Unicode верхнего регистра или заглавная |
| symbol |
|
ascSymbol | uniSymbol<special | _ | : | " | '> |
| ascSymbol |
|
! | # | $ | % | & | * | + | . | / | < | = | > | ? | @ |
| | |
\ | ^ | | | - | ~ |
| uniSymbol |
|
любой символ или знак пунктуации Unicode |
| digit |
|
ascDigit | uniDigit |
| ascDigit |
|
0 | 1 | ... | 9 |
| uniDigit |
|
любая десятичная цифра Unicode |
| octit |
|
0 | 1 | ... | 7 |
| hexit |
|
digit | A | ... | F | a | ... | f |
Перевод:
| программа |
|
{лексема | пробельная-строка } |
|
лексема
|
|
квалифицированный-идентификатор-переменной |
| | |
квалифицированный-идентификатор-конструктора |
| | |
квалифицированный-символ-переменной |
| | |
квалифицированный-символ-конструктора |
| | |
литерал |
| | |
специальная-лексема
|
| | |
зарезервированный-оператор |
| | |
зарезервированный-идентификатор |
| литерал |
|
целый-литерал |
| | |
литерал-с-плавающей-точкой |
| | |
символьный-литерал |
| | |
строковый-литерал |
| специальная-лексема
|
|
( | ) | , | ; | [ | ] |'| { | } |
| пробельная-строка |
|
пробельный-элемент {пробельный-элемент} |
| пробельный-элемент |
|
пробельный-символ |
| | |
комментарий |
| | |
вложенный-комментарий |
| пробельный-символ |
|
новая-строка |
| | |
вертикальная-табуляция |
| | |
пробел |
| | |
горизонтальная-табуляция |
| | |
пробельный-символ-Unicode |
| новая-строка |
|
возврат-каретки перевод-строки |
| | |
возврат-каретки |
| | |
перевод-строки |
| | |
перевод-страницы |
| комментарий |
|
тире [ любой-символ<символ> {любой-символ}] новая-строка |
| тире |
|
- {-} |
| начало-комментария |
|
{- |
| конец-комментария |
|
-} |
| вложенный-комментарий |
|
начало-комментария ЛЮБАЯ-последовательность {вложенный-комментарий ЛЮБАЯ-последовательность}конец-комментария |
| ЛЮБАЯ-последовательность |
|
{ЛЮБОЙ-символ}<{ЛЮБОЙ-символ}( начало-комментария | конец-комментария ) {ЛЮБОЙ-символ}>
|
| ЛЮБОЙ-символ |
|
графический-символ | пробельный-символ |
| любой-символ |
|
графический-символ |
| | |
пробел |
| | |
горизонтальная-табуляция |
| графический-символ |
|
маленькая-буква |
| | |
большая-буква |
| | |
символ |
| | |
цифра |
| | |
специальная-лексема
|
| | |
: | " | ' |
| маленькая-буква |
|
маленькая-буква-ASCII |
| | |
маленькая-буква-Unicode |
| | |
_ |
| маленькая-буква-ASCII |
|
a | b | ... | z |
| большая-буква |
|
большая-буква-ASCII | большая-буква-Unicode |
| большая-буква-ASCII |
|
A | B | ... | Z |
| символ |
|
символ-ASCII |
| | |
символ-Unicode<специальная-лексема | _ | : | " | '>
|
| символ-ASCII |
|
! | # | $ | % | & | * | + | . | / | < | = | > | ? | @ |
| | |
\ | ^ | | | - | ~ |
| символ-Unicode |
|
любой символ или знак пунктуации Unicode |
| цифра |
|
цифра-ASCII | цифра-Unicode |
| цифра-ASCII |
|
0 | 1 | ... | 9 |
| цифра-Unicode |
|
любая десятичная цифра Unicode |
| восьмиричная-цифра |
|
0 | 1 | ... | 7 |
| шестнадцатиричная-цифра |
|
цифра | A | ... | F | a | ... | f |
Лексический анализ должен использовать правило "максимального потребления": в каждой точке считывается наиболее длинная из возможных лексем, которая удовлетворяет правилу вывода lexeme (лексемы).
Таким образом, несмотря на то, что case является зарезервированным словом, cases таковым не является. Аналогично, несмотря на то, что = зарезервировано, == и 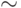 =- нет.
=- нет.
Любой вид whitespace (пробельной-строки) также является правильным разделителем для лексем.
Символы, которые не входят в категорию ANY (ЛЮБОЙ-символ), недопустимы в программах на Haskell и должны приводить к лексической ошибке.