Опубликован: 23.05.2008 | Доступ: свободный | Студентов: 1637 / 452 | Оценка: 4.80 / 4.10 | Длительность: 15:29:00
Специальности: Программист
Лекция 7:
Распределенное имитационное моделирование
< Лекция 6 || Лекция 7 || Лекция 8 >
Аннотация: Причины перехода к распределенному моделированию. Типы и свойства распределенных систем имитационного моделирования (прозрачность, масштабируемость, интероперабельность и т.д.). Отличие распределенного алгоритма от централизованного (отсутствие знаний о глобальном состоянии, о глобальном времени, недетерминизм). Объединение разнородных систем моделирования. Время в системах моделирования
Ключевые слова: имитационное моделирование, корпоративная информационная система, глобальные сети, компьютерные сети, моделирование, имитационные модели, событийное моделирование, discrete event simulation, TEDS, kit, DIS, interact, simulate, aggregation, HLA, RTI, system time, физическая система, управляющие программы, симулятор
В одной из лекций шла речь о методах исследования распределенных систем. В качестве одного из методов рассматривался метод имитационного моделирования.
Если предположить, что предметом исследования системы имитационного моделирования является корпоративная информационная система, охватывающая территориально распределенные офисы и/или производственные объекты, то возникает необходимость в исследовании аппаратуры (а это множество компьютеров, объединенных в локальные и глобальные сети), информационных потоков, бизнес-процессов, цепочек поставок и т.д.
Таким образом, система моделирования должна уметь оперировать с большим количеством объектов и процессов. Эти системы моделирования требуют больших вычислительных ресурсов. Целесообразно для таких имитационных экспериментов использовать многопроцессорные ЭВМ, кластеры или компьютерные сети. Системы моделирования, использующие многопроцессорные ЭВМ и компьютерные сети, называют параллельными или распределенными. В настоящее время устоявшимся термином является термин "распределенное моделирование", в дальнейшем будем использовать этот термин. Рассмотрим более подробно причины появления распределенного моделирования.
Причины для перехода к распределенному моделированию
Использование распределенного моделирования объясняется:
- возможностью использования вычислительных ресурсов нескольких процессоров (компьютеров) для выполнения имитационного эксперимента (предполагается. распределение компонентов имитационной модели по процессорам (компьютерам) и совместное их участие в имитационном эксперименте) с целью повышения производительности систем имитационного моделирования;
- использованием локальной памяти других процессоров (компьютеров);
- одновременным запуском нескольких репликаций параллельно на нескольких компьютерах (снижение временных затрат на эксперимент);
- объединением уже готовых имитационных моделей и их участием в совместном имитационном эксперименте (переиспользование кода).
- возможностью участия географически удаленных друг от друга пользователей в работе над одним имитационным проектом, возможность разработки модели, запуска имитационного эксперимента и одновременного наблюдения за выполнением разработанной модели,
- повышение надежности при выполнении имитационного эксперимента, поскольку при выходе из строя процессора или компьютера, на котором выполняется один из компонентов имитационной модели, выполнение его может быть продолжено на другом процессоре (компьютере).
Два направления в развитии распределенных систем моделирования
Развитие распределенного имитационного моделирования идет по двум направлениям. Это монолитные системы моделирования и готовые системы моделирования, объединенные с помощью специального программного обеспечения.
Для создания новых высокоэффективных "монолитных" систем моделирования, в которых поддерживается параллельное дискретно-событийное моделирование (PDES-Parallel Discrete Event Simulation) используют спецпроцессоры для параллельного моделирования, сопутствующие языки, библиотеки и инструментальные средства. Примерами этого подхода служат такие системы как TeD/GTW, SPEEDES, Task-Kit и др. В нашей стране тоже ведутся работы по созданию распределённых систем имитации (Мера (Новосибирск), Диана (МГУ)). Имитационные модели тесно связаны со средой, для которой они были разработаны, и это создает проблемы при смене окружения, например, при переносе системы на другую платформу.
Вторая парадигма, которая появилась в распределенном моделировании – это объединение разнородных систем моделирования. В этом случае компонентами имитационного моделирования являются не объекты (как это делается в последовательном моделировании), не логические процессы (PDES), а сами имитационные модели. Таким образом, задача этих проектов создать окружение для взаимодействия уже ранее созданных имитационных моделей. Этот подход используется в таких системах как DIS (Distributed Interactive Simulation), ALSP (Aggregate Level Simulation Protocol), HLA (High Level Architecture или "Архитектура высокого уровня"). В настоящее время широко используется HLA. Компонентами имитационного моделирования в этом случае являются федераты, а объединение федератов называют федерацией. Федераты одной федерации могут быть разнородными (это могут быть имитационные модели, тренажёры, программа для сбора данных и даже "живые участники"). Обмен данными между федератами и исполнение федератов в едином модел ьном времени выполняется с помощью программной оболочки RTI.
Синхронизация времени в распределенных вычислениях
Для выполнения распределенной модели необходимо реализовать взаимодействие ее компонентов. Кроме того, необходимо синхронизовать выполнение этих компонентов.
Проблемы синхронизации времени актуальны для всех распределенных приложений.
Физическое время
Рассмотрим пример: пусть на нескольких компьютерах (клиентах) располагаются директории с файлами – списки товаров, на сервере – сводная директория, которая периодически обновляется. Приложение, расположенное на сервере, просматривает директории других компьютеров со списками товаров и, если
tсервера > tпоследнего обновления клиента > tпоследнего обновления сервера
то приложение переписывает этот файл в сводную директорию.
На первый взгляд достаточно простая задача может быть выполнена некорректно. Это может произойти из-за рассинхронизации физических часов компьютеров, участвующих в работе.
Почти все компьютеры имеют таймеры, которые и определяют время компьютера. Но не все таймеры работают с одинаковой частотой. Разница в работе таймеров приводит к тому, что у каждого компьютеры часы будут указывать на своё время. Произойдет рассинхронизация.
Вследствие этого приложение, описание работы которого приведено выше, будет работать некорректно. Действительно, пусть на одном из компьютеров процессное время имеет отметку 234 и в этот момент времени произошло обновление файла ( tпоследнего обновления клиента ). Сервер начинает работу по обновлению своего списка, но отметка времени при этим tсервера = 232. Таким образом, уже обновленный файл на клиенте сервером не будет замечен (приведенное выше условие) не выполняется. Следовательно, приложение будет работать некорректно.
Для синхронизации физического времени существуют различные алгоритмы, в том числе, алгоритмы Кристиана, Беркли, усредняющие алгоритмы.
Если в алгоритме Кристиана сервер времени пассивен (другие компьютеры периодически запрашивают у него время), он только лишь отвечает на запросы. В операционной системе UNIX разработки университета Беркли (Berkeley) принят прямо противоположный подход. Здесь сервер времени активен, он опрашивает каждую из машин. На основании ответов он вычисляет среднее время и предлага¬ет всем машинам установить их часы на новое время или замедлить часы, пока не будет достигнуто необходимое уменьшение значения времени на сильно ушед¬ших вперед часах. Этот метод применим для систем, не имеющих машин с прием¬ником WWV. Время демона может периодически выставляться вручную опера¬тором.
Управление временем в последовательном имитационном моделировании
Известно, что большую роль в имитационных моделях играет фактор времени. По определению имитационное моделирование является методом исследования динамических систем, в котором реальный объект (система) заменяются имитационной моделью. Процесс моделирования сопровождается отображением реального объекта (системы) в модель, которая выполняется, изменяя свое состояние с течением времени, причём время необратимо, оно не замедляется и не ускоряется. Состояние системы определяется состоянием её элементов, а каждый элемент обладает набором свойств (характеристик).
Прежде всего, следует определить, что следует понимать под термином "время" в имитационном моделировании. В работе Fujimoto и других работах по имитационному моделированию различают: физическое (physical), модельное (system time) и процессорное (wallclock time). Рассмотрим более подробно все эти 3 разновидности:
- Физическое время (physical- Tp ) – это время, которое используется в реальной (физической) системе, которую моделируют. Например, мы моделируем работу некоторого предприятия в течение рабочего дня с 8.00 до 17.00.
- Модельное время (simulation time - Ts ) – это представление физического времени в модели. Так работу предприятия в модельном времени можно представить отрезком времени [8.00,17.00], за единицу модельного времени (h) можно принять временной интервал в 1 минуту, в 10 минут, в 30 минут, в один час и т.д. Ts = Tp/h.
- Процессорное время (wallclock time - Tw ) – время работы симулятора на компьютере. Так, например, моделирование предприятия может занять 1 час работы на компьютере.
Моделирование должно выполняться как можно скорее (as-fast-as-possible), т.е. модельное время продвигается с гораздо большей скоростью, чем процессорное. Например, работа некоторого физического процесса длится несколько суток, единицу модельного времени выбирают равной одному часу, а процесс моделирования на компьютере выполняется за 30 минут.
Иногда (при использовании тренажёров) продвижение модельного времени должно быть синхронизировано с процессорным. Такое моделирование называют моделированием в реальном времени (real time). Действительно, при использовании тренажёров человек погружается с виртуальную среду, которая должна выглядеть как можно более реалистичной.
Итак, одной из важнейших задач системы имитации является продвижение модельного времени. Вначале кратко рассмотрим алгоритм продвижения модельного времени в последовательном моделировании.
Известно, что существуют различные виды имитационных моделей, в основе которых лежит та или иная концепция:
- События (events).
- Процессы (processes).
- Объекты (objects) или агенты (agents).
- Непрерывные (continues) модели (системная динамика).
Событие – это изменение состояния системы, причём событие происходит мгновенно. В промежутке между двумя событиями модель остаётся неизменной. Процесс – это последовательность активностей, а активность – это элементарная работы по переводу системы из одного состояния в другое. Активность начинается и завершается событием.
Как уже говорилось ранее, система моделирования, управляющая выполнением модели, должна уметь продвигать модель из одного состояния в другое. Продвижение модели из одного состояния в другое выполняется по определённым правилам, эти правила определяют сценарий поведения модели во времени, причинно-следственные связи между активностями. Управляющая программа, которая выполняет продвижение времени называется симулятором.
В зависимости от того, какая концепция лежит в основании имитационной модели, системы моделирования делятся процессо-ориентированные, событийно-ориентированные, объектно-ориентированные, агентные.
Рассмотрим более подробно событийно-ориентированное моделирование
В событийно-ориентированных системах моделирования приняты следующие соглашения:
- модель продвигается во времени от события ei к событию ej, которые изменяют состояние модели,
- логика наступления событий определяет последовательность смены состояний модели, которые связаны с наступлением этих событий;
- время продвигается от события к событию;
Пусть время – частично упорядоченное множество T ={t1, t2,…,tn}. Пусть существует множество событий 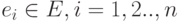 . Любое событие может включать преобразование Sch: E x T x E, т.е. событие ei (выполняющееся в момент времени ti ) может планировать выполнение другого события ej в момент времени tj и размещать его в календаре событий. Календарь событий состоит из элементов, каждый из которых содержит два поля:
. Любое событие может включать преобразование Sch: E x T x E, т.е. событие ei (выполняющееся в момент времени ti ) может планировать выполнение другого события ej в момент времени tj и размещать его в календаре событий. Календарь событий состоит из элементов, каждый из которых содержит два поля:
- ссылку на запланированное событие (ei) ;
- модельное время, на которое запланировано событие (ti).
Таким образом, можно сказать, что календарь событий (обозначим его SE) – это список элементов li, где каждый элемент li представляет собой пару ( ei, ti ).
Управляющая программа (симулятор) должна выбрать из календаря событий событие с минимальным временем. Это время становится текущим модельным временем. Симулятор присваивает системной переменной с текущим модельным временем (назовём эту переменную именем Systemtime ) минимальное значение времени, на которое запланировано событие из календаря событий, т.е. Systemtime = min (ti). Далее симулятор передаёт управление событию ei (с минимальным временем).
Цель: Необходимо выбрать очередное событие в календаре событий и передать ему управление:
while (не конец моделирования) do
begin
Просмотреть список SE = {li}, где li = (ei, ti), 0<= i <= n и выбрать элемент с минимальным временем ti.
Systemtime := min(ti);
Передать управление событию ei из элемента li = (ei , ti);
Обработать это событие. Если событие ei запланировало новое событие ej
(т.е. было выполнено преобразование Sch), то соответствующий элемент lj
следует поместить в список событий SE, т.е. выполнить операцию SE:=SE + lj
endЕсли сразу несколько событий запланировано на одно и то же время, то они выполняются последовательно друг за другом (квазипараллельно), системное время systemtime не изменяется до тех пор, пока все эти события не будут обработаны.
Для того чтобы поиск был эффективным, обычно список запланированных событий упорядочивают по возрастанию. Симулятор должен поместить новый элемент в календарь событий, причём упорядоченность по возрастанию должна быть сохранена.
Если число элементов в списке SE велико, поиск события с минимальным временем (и включение в список нового элемента) может занять много времени. Для оптимизации этого процесса исследователи предлагают усовершенствованные алгоритмы:
- Поиск с начала и конца списка.
- Использование различных списков для различных типов событий.
- Использование дополнительного указателя на середину списка. Сначала происходит сравнение с нужным элементом, а потом поиск происходит в нужной половине списка.
- Использование множества запланированных событий в виде бинарного дерева.
- Хранение наряду с календарём событий массива указателей на элементы списка. Таким образом, список событий делится на подсписки (между двумя соседними указателями). Эти подсписки соответствуют интервалам системного времени. Длины всех интервалов равны фиксированному значению. Это значение задаётся пользователем. При планировании нового события вычисляется его индекс в массиве указателей, после чего новый элемент календаря событий может быть размещён в соответствующем его подсписке.
< Лекция 6 || Лекция 7 || Лекция 8 >
Ольга Космодемьянская
|
Я прошла курс "Распределенные системы и алгоритмы". Сдала экзамен экстерном и получила диплом. Вопрос: можно ли после завершения теста посмотреть все вопросы, которые были на экзамене и все варианты ответов? Мне это необходимо для отчета преподавателю в моем ВУЗе. Заранее спасибо! |