Применение SPMD-технологии при построении сетевых баз данных с циркулирующей информацией
Многосерверные сетевые БД с циркулирующей информацией
Рассмотрим локальную вычислительную сеть, которая работает по принципу "клиент-сервер" при удовлетворении запросов от рабочих станций к сегментированной базе данных, находящейся на сервере.
Пусть 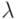 — интенсивность интегрированного потока
запросов, поступающего от всех РС,
— интенсивность интегрированного потока
запросов, поступающего от всех РС,  — интенсивность потока обслуживания.
— интенсивность потока обслуживания.
Пусть, далее, в силу специфики применения все запросы — простые, т.е. реализуют обращение не более чем к одному сегменту БД каждый и при обслуживании одного запроса не возникает обращений к другим сегментам (что характерно для сложных запросов).
Данную схему функционирования БД можно интерпретировать одноканальной системой массового обслуживания (сервер выполняет функции СУБД) с бесконечной очередью.
Тогда среднее время T*обсл обслуживания одной заявки вычисляется следующим образом:
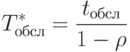 |
( 2.19) |
 — "чистое" время
выполнения работ по обслуживанию
одной заявки с помощью СУБД,
— "чистое" время
выполнения работ по обслуживанию
одной заявки с помощью СУБД, 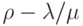 .
.Разработчики сетевых БД традиционно не учитывают те параметры
комплексирования сети, при которых дальнейшая нагрузка на БД (подключение новых РС) становится
недопустимой. Ведь  при
при  !
!
Выход из критического положения заключается в использовании не одного, а нескольких серверов, т.е. в переходе к модели многоканальной системы массового обслуживания.
Возможны различные схемы разделения нагрузки между серверами. Это — разделение сегментов БД между серверами при обеспечении связей всех РС с каждым сервером.
Другая схема может предполагать подключение групп РС к одному серверу при возможности использования одним сервером сегментов, расположенных на другом сервере. Такая схема приводит к появлению новых запросов в сети.
Возможна схема, при которой БД дублируется на каждом сервере. Тогда запросы, изменяющие состояние БД, должны "отслеживаться" на каждом сервере.
Все такие схемы затрудняют синхронизацию использования общих данных, усложняют работу СУБД.
Простой выход представляет организация движения, циркуляции сегментов БД между n серверами при подключении каждой РС к одному, "своему" серверу. Время выполнения заявки при этом увеличивается лишь за счет времени ожидания прихода нужного сегмента на сервер.
Такая схема организации сетевой БД показана на рис. 2.7.
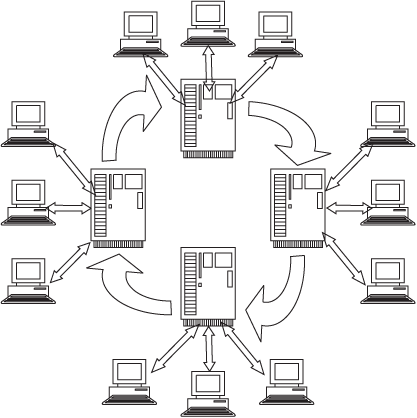
Если к каждому серверу подключено примерно одинаковое число k
РС, то интегрированный поток запросов делится поровну между серверами, и интенсивность  потока запросов к одному серверу можно считать
равной
потока запросов к одному серверу можно считать
равной 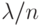 .
.
Тогда время обслуживания одного запроса РС вычисляется следующим образом:
 |
( 2.20) |
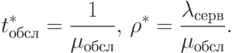
Очевидно, что t*обсл = tобсл + tож. Значение tож обусловлено циркуляцией сегментов БД между серверами и без учета "перехвата" другими серверами на пути следования может быть оценено (см. (2.2)):
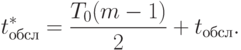 |
( 2.21) |
С учетом возможности единственного "перехвата" сегмента на пути его следования по (2.9) находим
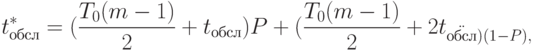 |
( 2.22) |
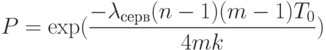 |
( 2.23) |
Здесь n — количество серверов, m — количество
сегментов БД, интенсивность запросов пользователя 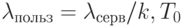 — длительность такта системы.
— длительность такта системы.
Тогда очевидно, что рассматриваемая организация сетевой базы данных имеет смысл, если Tобсл << T*обсл.
Отметим, что предлагаемые выше механизмы перемещения информации в сетевой БД, т.е. механизмы активизации ее совокупной памяти, отражают технический уровень построения БД, структуру, способ организации и способ использования памяти ЛВС. Над этим уровнем строится логическая и функциональная сущность БД, которая "не знает", как он устроен. В аналогичной ситуации разработчик программной системы (или транслятор) "не знает" (ибо не опирается на это), как реализуется идея виртуальной памяти компьютера, то есть, каковы механизмы замещения страниц, какова дисциплина замещения и т.д. Это — не его уровень.
В то же время, сегодня мы не можем с уверенностью опровергнуть сомнения в том, что применительно к БД удастся достичь полной независимости таких уровней. Громоздкость выкладок на основе вероятностных оценок, заведомо неполный учет всех факторов говорят, что в целом мы имеем дело с задачей детерминированного имитационного моделирования. Процесс должен быть воспроизведен как можно ближе к реальному, определяя натурный эксперимент. Это позволит оценить действительные возможности сетевого программного обеспечения и технические характеристики ЛВС.
Вместе с тем, здесь не предлагается новый, абсолютный способ организации хранения и использования информации в базах данных, отвергающий все то, что было разработано ранее. Цель настоящей публикации — показать, что существует способ сокращения времени обработки запросов к БД, основанный на организации "встречного" движения информации в ней. Этим способом можно пользоваться частично и весьма обоснованно, для чего предлагаются некоторые соотношения — критерии. Представленные же здесь схемы "рафинированно", по максимуму отражают предложения, но не навязывают каких-либо типовых структур данных.
В этом смысле арсенал средств повышения эффективности базы данных, которым располагает конструктор — разработчик БД, расширяется еще одним средством — средством активизации памяти для "встречного" предложения информации в сетевой базе данных, которым он может воспользоваться после тщательного обоснования. Можно предположить, что различные, прежде всего, по функциональному назначению, БД в разной степени допускают применение предложенного принципа. Например, можно надеяться на то, что встречное движение информации в вычислительной сети способно сократить длину очереди к билетным кассам на поезда дальнего следования.