|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Спонсор: Intel
Вы можете этот курс.
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 30.05.2014 | Доступ: свободный | Студентов: 304 / 36 | Длительность: 11:26:00
Специальности: Программист, Системный архитектор
Лекция 5: Элементы оптимизации прикладных программ для Intel Xeon Phi. Intel C/C++ Compiler
Подходы к оптимизации прикладных программ для Intel Xeon Phi
Сопроцессоры архитектуры Intel Many Integrated Core являются мощным средством для ускорения существующих приложений, позволяя достаточно просто выполнить первичный перенос кода на сопроцессор. Однако для получения существенного прироста производительности требуется выполнить ряд шагов по оптимизации вашей параллельной программы, причем эти шаги одинаково применимы при работе как с сопроцессором, так и с обычным многоядерным процессором.
По большей части оптимизация для Intel Xeon Phi заключается в обеспечении эффективной работы с памятью.
Процесс оптимизации следует начать с выявления "узких мест" в вашей программе, для чего лучше всего воспользоваться инструментом Intel ® VTune ™ Amplifier XE.
Существует, однако, еще один инструмент, входящий в состав Intel Compiler и позволяющий профилировать циклы. С его помощью можно выявлять те функции и циклы в них, работа которых занимает большое время. Если эти циклы имеют большое число повторений и сравнительно мало кода, то это хорошие кандидаты на параллелизм по данным или SIMD векторизацию. А если кода в этих циклах много и они отвечают за управляющую часть вашей программы, то стоит задуматься о потоковом или функциональном параллелизме для них.
Заметим, что встроенный в компилятор профилировщик циклов может использоваться только для последовательного кода. Для параллельной программы следует применять более мощные инструменты (например, Intel ® VTune ™ Amplifier XE), или отключать параллелизм.
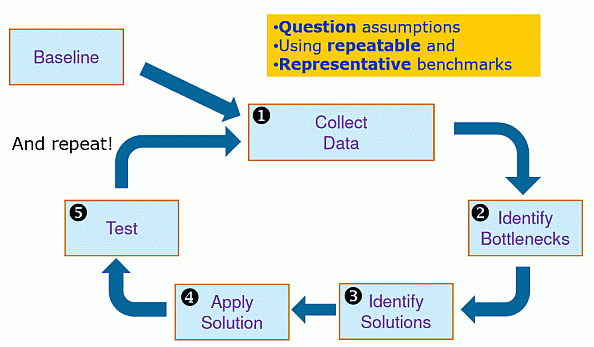
Оптимизация приложений – это итеративный процесс, основные шаги которого представлены на рис. 5.8.
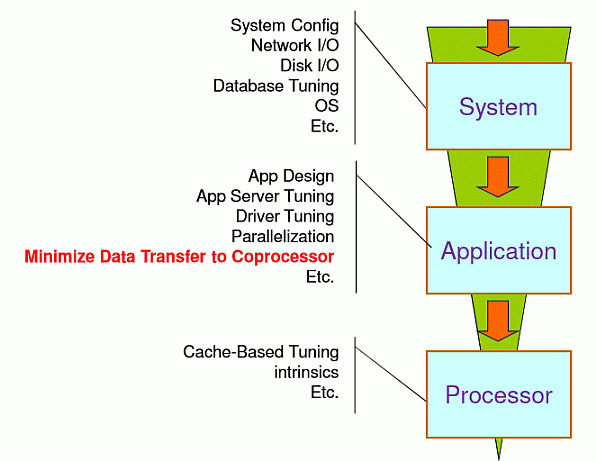
Еще один подход к оптимизации заключается в поиске и устранении "узких мест" сверху вниз: от уровня операционной системы через приложение к уровню процессора ( рис. 5.9).
Использование встроенного профилировщика циклов
Как уже отмечалось выше, использование встроенного профилировщика циклов позволяет определить "узкие места" вашего приложения для их дальнейшей оптимизации.
Для использования этой возможности необходимо включить инструментацию кода в процессе компиляции:
icc -O1 -profile-functions -profile-loops=all \ -profile-loops-report=2 ...
При этом компилятор добавит код для сбора статистики в начало и конец циклов и функций.
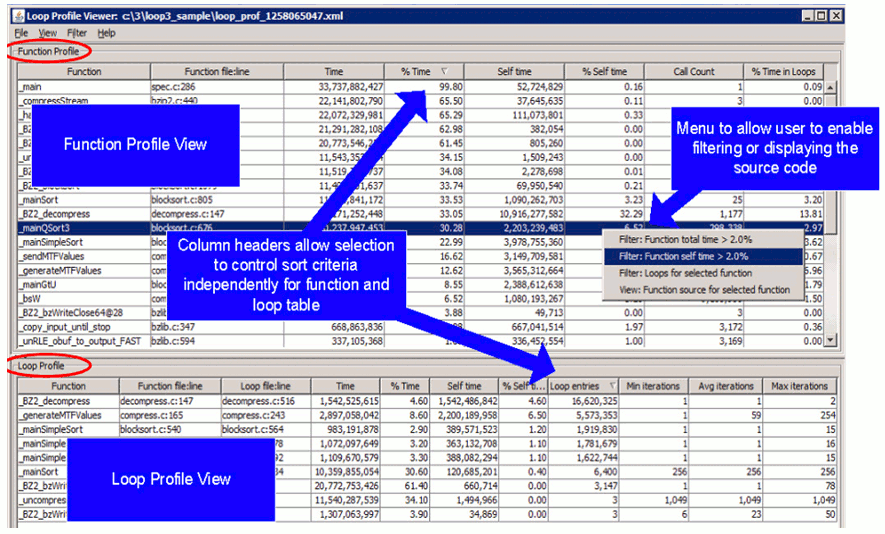
Далее нужно запустить приложение на интересующем вас тесте. Программа соберет статистику о своей работе и запишет ее в формате таблицы (понятном для пользователя) и в формате xml (который можно проанализировать с использованием специального GUI приложения – Loop Profile Viewer).
Файлы содержат такую информацию, как:
- имена и количество вызовов функций, количество циклов в них;
- общее время работы функций и циклов;
- время работы функций и циклов без учета внутренних вызовов;
- среднее, минимальное и максимальное количество итераций циклов.
Пример работы GUI приложения для просмотра статистики приведен на рис. 5.10.
Использование отчетов компилятора
Еще одним инструментом, полезным при оптимизации кода для процессоров и сопроцессоров Intel, являются различные отчеты компилятора.
Рассмотрим наиболее полезные в этом плане опции компиляции:
- Отчет о векторизации: -vec-report[n]
Позволяет получить информацию о том, какой код был векторизован, для какого кода это сделать не удалось и почему. В частности полезно при использовании автоматической векторизации. Подробнее в разделе 2.5.
icc example.c –mmic –O3 –vec-report2
- Руководство по векторизации: -guide-vec[=n]
Данная опция позволяет получить рекомендации по изменению кода, которые позволят компилятору найти больше возможностей для векторизации.
- Руководство по дополнительной оптимизации: -guide
Позволяет получить ряд советов касательно модификации вашего кода с тем, чтобы компилятор мог лучше его оптимизировать.
- Отчет об оптимизации: -opt-report [n]
Данная опция информирует программиста о том, как компилятор модифицирует ваш код, пытаясь сгенерировать наиболее оптимальную его версию.
Опция часто бывает полезной при поиске ответа на вопросы вида "Почему компилятор сказал это?"
Svetlana Svetlana