Лекция 7: Оптимальное программирование в архитектуре управления каждым тактом
Расчет нейросети
Попробуем выработать рекомендации по совместному программированию обработки вариантов счета, обработки элементов массива и др., что позволяет увеличить эффективность использования многофункциональных АЛУ.
Методы вычислений отличаются регулярностью действий. На их основе можно строить эффективные схемы вычислений с использованием многофункциональных АЛУ, в том числе — в архитектурах, сводящихся к "длинным" командным словам.
Рассмотрим пример распараллеливания типичного фрагмента обработки нейросети в режиме распознавания. Он демонстрирует способ оптимальной реализации на процессоре, где АЛУ содержит несколько исполнительных устройств (ИУ) различной специализации, функций нейрокомпьютера. Максимальная загрузка всех устройств возможна тогда, когда в каждом линейном участке программы предусмотрена обработка не одного, а нескольких нейронов сети. Покажем это на фрагменте алгоритма имитации работы нейронов в режиме распознавания, т.е. в режиме, требующем максимальной производительности нейрокомпьютера.
Программирование трехадресных команд
В режиме распознавания в простейшей модели нейрона решается задача суммирования взвешенных, в соответствии с регулируемыми на этапе обучения весами {wi},i = 1, ..., n, синапсов — значений синапсических сигналов {xi} и сравнение полученной суммы с порогом h. Если сумма превышает порог, происходит возбуждение нейрона с величиной y:
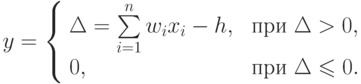
Для n = 3 запишем в трехадресных командах программу одновременной обработки двух нейронов. Это двукратное повторение одной и той же последовательности команд, отличающейся используемыми адресами (табл. 7.1).
| № | КОП | A1 | A2 | A3 |
|---|---|---|---|---|
| 1 | x | <w11> | <x11> | r1 |
| 2 | x | <w12> | <x12> | r2 |
| 3 | x | <w13> | <x13> | r3 |
| 4 | + | r1 | r2 | r4 |
| 5 | + | r3 | r4 | r5 |
| 6 | - | r5 | <h1> | r6 |
| 7 | > | r6 | r7 | |
| 8 | if... | r7 | r6 | <y1> |
| 0 | ||||
| 9 | x | <w21> | <x21> | r8 |
| 10 | x | <w22> | <x22> | r9 |
| 11 | x | <w23> | <x23> | r10 |
| 12 | + | r8 | r9 | r11 |
| 13 | + | r10 | r11 | r12 |
| 14 | - | r12 | <h2> | r13 |
| 15 | > | r13 | r14 | |
| 16 | if... | r14 | r13 | <y2> |
| 0 |
Очевидно, программа совместной обработки трех нейронов будет содержать трехкратное повторение такого же участка и т.д.
Компоновка "длинных" команд
Выше было показано, что при решении задач параллельного программирования для полного задания информации о частичной упорядоченности работ целесообразно использовать квадратные (размер m равен числу трехадресных команд линейного участка) нуль-единичные матрицы следования S, дополненные столбцами весов — времен выполнения работ.
Такая матрица для нашего примера представлена в таблице 7.2, где кроме весов
указаны также поздние сроки  начала выполнения команд (для
суммы всех времен выполнения работ Т = 56 ) и объемы
начала выполнения команд (для
суммы всех времен выполнения работ Т = 56 ) и объемы  последующих работ. Эти
значения найдены по
приведенным выше алгоритмам. Если при совместном анализе двух команд
( i -й и j -й, i>j ) первый или второй адрес "нижней" команды
совпадает с третьим адресом
"верхней" команды, то элемент матрицы S на
пересечении i -й строки и j -го столбца
полагается равным единице
последующих работ. Эти
значения найдены по
приведенным выше алгоритмам. Если при совместном анализе двух команд
( i -й и j -й, i>j ) первый или второй адрес "нижней" команды
совпадает с третьим адресом
"верхней" команды, то элемент матрицы S на
пересечении i -й строки и j -го столбца
полагается равным единице  , в противном случае
он равен нулю.
, в противном случае
он равен нулю.
Этот алгоритм формирования матрицы следования предполагает некоторые ограничения на способ программирования. В общем случае такой совместный анализ команд должен быть дополнен анализом на несовпадение третьего адреса команды со всеми адресами вышеследующих команд.
В приведенной матрице отражены и транзитивные связи.
| T | |
|
|||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 38 | 18 | ||||||||||||||||
| 2 | 5 | 38 | 18 | ||||||||||||||||
| 3 | 5 | 41 | 15 | ||||||||||||||||
| 4 | 1 | 1 | 3 | 43 | 13 | ||||||||||||||
| 5 | 1 | 1 | 1 | 1 | 3 | 46 | 10 | ||||||||||||
| 6 | 1 | 1 | 1 | 1 | 1 | 3 | 49 | 7 | |||||||||||
| 7 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 52 | 4 | ||||||||||
| 8 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 54 | 2 | |||||||||
| 9 | 5 | 38 | 18 | ||||||||||||||||
| 10 | 5 | 38 | 18 | ||||||||||||||||
| 11 | 5 | 41 | 15 | ||||||||||||||||
| 12 | 1 | 1 | 3 | 43 | 13 | ||||||||||||||
| 13 | 1 | 1 | 1 | 1 | 3 | 46 | 10 | ||||||||||||
| 14 | 1 | 1 | 1 | 1 | 1 | 3 | 49 | 7 | |||||||||||
| 15 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 52 | 4 | ||||||||||
| 16 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 54 | 2 |
Выберем структуру АЛУ, содержащую два ИУ сложения, два — умножения, два — логических. Остальные ИУ нам в примере не понадобятся. В командных словах также предположим обязательное присутствие позиций, соответствующих этим ИУ.
В таблице 7.3 отражена временная диаграмма условного назначения (формирования "длинного" командного слова) и имитации выполнения трехадресных команд. Алгоритм формирования, выполнение которого сопровождается исключением из матрицы S строк и столбцов, соответствующих "выполненным" командам, изложен выше.
| Такты | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 4 | 3 | 2 | 1 | 0 | Исключаем строку и столбец из матрицы S | |||||||||||||
| 2 | 5 | 4 | 3 | 2 | 1 | 0 | Исключаем ... | |||||||||||||
| 3 | 5 | 4 | 3 | 2 | 1 | 0 | Исключаем ... | |||||||||||||
| 4 | 3 | 2 | 1 | 0 | Исключаем ... | |||||||||||||||
| 5 | 3 | 2 | 1 | 0 | Исключаем ... | |||||||||||||||
| 6 | 3 | 2 | 1 | 0 | Исключаем ... | |||||||||||||||
| 7 | 2 | 1 | 0 | Исключаем ... | ||||||||||||||||
| 8 | 2 | 1 | 0 | И | ||||||||||||||||
| 9 | 5 | 4 | 3 | 2 | 1 | 0 | Исключаем ... | |||||||||||||
| 10 | 5 | 4 | 3 | 2 | 1 | 0 | Исключаем ... | |||||||||||||
| 11 | 5 | 4 | 3 | 2 | 1 | 0 | Исключаем ... | |||||||||||||
| 12 | 3 | 2 | 1 | 0 | Исключаем ... | |||||||||||||||
| 13 | 3 | 2 | 1 | 0 | Исключаем ... | |||||||||||||||
| 14 | 3 | 2 | 1 | 0 | Исключаем ... | |||||||||||||||
| 15 | 2 | 1 | 0 | Искл. | ||||||||||||||||
| 16 | 2 | 1 | 0 | |||||||||||||||||
"Назначенные" работы (трехадресные команды) и такты, в которые они назначены, соответствуют "длинным" командам. Как видно из таблицы — диаграммы, программа изобилует пропусками тактов, NOP 'ами.
Предположим наличие средств синхронизации, аналогичное использованию битов значимости. Т.е. предположим, что регистры СОЗУ имеют биты значимости, "взводящиеся" в начале выполнения тех команд, в которых предусмотрена запись в эти регистры. Тогда считывание из этих регистров невозможно до окончания выполнения тех операций, по которым в них производится запись. Отсюда следует возможность ликвидации всех NOP 'ов в программе. В данном примере окончательный вид формируемой программы представлен в таблице 7.4.
Несмотря на то, что мы не можем считать рассмотренный в основной части пример характерным, он наводит на мысль о необходимости полного статистического анализа целесообразности оптимизации компоновки "длинных" командных слов. Сложность такой компоновки, возможно, компенсируется простотой получения программы в результате "быстрой" компоновки, если учитывать совокупную стоимость разработки и выполнения программ. Очевидно, что эта проблема требует изучения на основе моделирования.
Архитектура ВС с управляемой в каждом такте работой исполнительных устройств выявляет определенные правила по организации вычислений. На примере показана целесообразность совместной обработки нескольких элементов массива — в обобщенном понятии. Такая обработка обеспечивает максимальную загрузку оборудования, т.е. максимальное значение коэффициента загрузки исполнительных устройств АЛУ.