Семантический веб и микроформаты
20.2. Применение микроформатов
20.2.1. Общие сведения
Микроформаты (microformats, иногда сокращенно  F или uF) – это способ семантически размечать сведения о разнообразных сущностях (событиях, организациях, людях, товарах и так далее) на веб-страницах, используя стандартные элементы языка HTML (или XHTML) [18]. Пользователь может воспринимать страницу с размеченным микроформатом как обычную веб-страницу (через браузер); в то же время программы-обработчики способны извлечь из такой страницы структурированную информацию, следуя определенным соглашениям.
F или uF) – это способ семантически размечать сведения о разнообразных сущностях (событиях, организациях, людях, товарах и так далее) на веб-страницах, используя стандартные элементы языка HTML (или XHTML) [18]. Пользователь может воспринимать страницу с размеченным микроформатом как обычную веб-страницу (через браузер); в то же время программы-обработчики способны извлечь из такой страницы структурированную информацию, следуя определенным соглашениям.
Поскольку микроформаты основаны на уже существующих стандартах (таких, как HTML и XHTML), их легко добавлять на существующие страницы в паутине [19].
При использовании микроформатов к существующей HTML-разметке добавляются новые составляющие, наполненные особым, заранее определенным смыслом. Например, с помощью атрибута class можно обозначить смысл того или иного HTML-элемента на странице (этот атрибут определен для всех элементов). Таким образом, люди приходят к соглашению об использовании определенных значений атрибутов (в том числе class ) для разметки определенных фрагментов информации. В дальнейшем такую разметку можно обрабатывать машинными средствами.
Для разметки микроформатами подходят любые элементы HTML, но особое значение придается элементам, которые не имеют собственного, стандартного семантического значения – div и span. Из атрибутов в настоящее время используются в основном следующие:
- class
- rel
- rev
- title
Каждый микроформат решает определенную, отдельную задачу. Вот наиболее известные из них [20]:
- hCard (сокращение для HTML vCard) – микроформат для публикации контактной информации людей, компаний, организаций и мест в (X)HTML, Atom, RSS или произвольном XML ;
- hCalendar (сокращенно от HTML iCalendar) – микроформат для представления семантической информации о событиях в формате календаря iCalendar на (X)HTML-страницах;
- hAtom – ленты новостей (как аналог RSS и Atom) в обычном HTML или XHTML;
- XFN – социальные взаимоотношения;
- rel-tag – метки (теги) и образование фолксономии;
- xFolk – помеченные ссылки;
- adr – почтовые адреса;
- geo – географические координаты (широта и долгота);
- hReview – отзывы (о товарах, услугах, событиях и тому подобном);
- nofollow – для предотвращения индексации поисковыми системами определенных документов.
Разработка новых микроформатов происходит в открытом режиме.
Среди множества предлагаемых микроформатов наиболее близки к завершению микроформаты для разметки цитат и валют.
Рассмотрим пример применения микроформата hCard:
Будем считать, что у нас есть HTML, описывающий контактную информацию о человеке:
<div> <div>Иванов Иван Иванович</div> <div>21.12.1988</div> <div>ООО "Example"</div> <div>604-55-14</div> <a href="http://example.com/">http://example.com/</a> <a href="mailto:info@example.com">info@example.com</a> </div>
С добавлением микроформатов выглядит так:
<div class="vcard"> <div class="fn">Иванов Иван Иванович</div> <div class="bday">21.12.1988</div> <div class="org">ООО "Example"</div> <div class="tel">604-55-14</div> <a class="url" href="http://example.com/">http://example.com/</a> <a class="email" href="mailto:info@example.com">info@example.com</a> </div>
Содержимое самих элементов не изменилось; к ним только были добавлены атрибуты, указывающие, где именно в блоке находится та или иная информация (имя, телефон и так далее). Весь блок при этом имеет атрибут class="vcard", который является родительским для микроформата hCard. Это означает, что данный элемент и все вложенные в него элементы вместе составляют микроформат hCard .
Обычно используемые атрибуты hCard включают [20]:
- fn – имя в виде форматированной строки;
- PHOTO – изображение или фотография;
- org – название организации;
- tel – телефонный номер;
- url – URL (адрес сайта);
- adr – структурированное представление адреса;
- bday – дата рождения;
- email – адрес электронной почты;
- logo – логотип организации;
- note – дополнительная информация или комментарий;
- и др.
Несколько сайтов, принадлежащих Yahoo!, среди них Tech, Local, Flickr, и Upcoming, используют в своих публикациях различные микроформаты. И Yahoo! Tech, и Yahoo! Local используют микроформат hReview в своих обзорах ( reviews ), в то время, как Yahoo! Local так же использует hCalendar для описания событий, и hCard – для описания контактной информации. Flickr использует hCard в профайлах пользователей, равно как и микроформат XFN. Upcoming.org содержит более миллиона записей о событиях по всему миру, размеченных с использованием hCalendar. Также в Last.fm внедрены hCard на страницах профилей пользователей [21 ].
На Technorati.com есть поиск по микроформатам, в числе которых hCard , hCalendar, hReview.
Одним из способов использования такой информации являются плагины к браузерам, способные находить ее на странице, извлекать и передавать другим приложениям (адресной книге, календарям).
Так, например, микроформаты используются в новом Internet Explorer 8 [22]: с помощью технологии веб-фрагментов пользователи могут просматривать наиболее часто используемую информацию без перехода с текущей страницы, а разработчики могут помечать части веб-страниц как веб-фрагменты и облегчать пользователям отслеживание часто просматриваемой информации во время навигации по интернету. В панели "Избранное" обновленные веб-фрагменты выделяются полужирным шрифтом. Пользователи могут просмотреть обновленный веб-фрагмент или открыть его исходную веб-страницу.
Веб-фрагменты определяются разработчиком заранее [23]. В самую первую очередь, необходимо пометить элемент HTML div как контейнер, содержащий веб-фрагмент. Для этого используется имя класса hslice. В элементе hslice будут находиться все остальные определения, необходимые для веб-фрагмента. Каждый веб-фрагмент должен иметь уникальный идентификатор, поскольку именно с его помощью Internet Explorer различает веб-фрагменты на странице.
В каждом веб-фрагменте должен быть элемент для определения заголовка фрагмента. Это название определяется по классу CSS entry-title. Именно такой заголовок будет показан на панели "Избранное" и в меню командной панели поиска каналов. Если потребуется, то текст entry-title можно изменить; он обновится вместе с обновлением веб-фрагмента.
В качестве примера веб-фрагмента можно привести следующий:
<div class="hslice" id="ProductID1"> <h1 class="entry-title">Brand New Product!</h1> <div class="entry-content"><p>This is the product definition.</p></div> </div>
В примере добавлен еще один элемент: класса содержимого записи ( entry-content ), в который помещено содержание, которое должно отображаться пользователю (рис. 20.6).
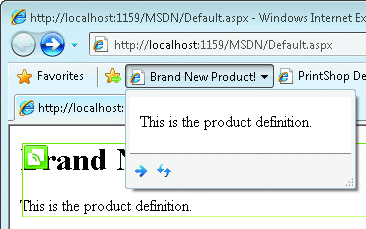
Источник: Новые функции для веб-фрагментов, хранения и повышения производительности веб-приложений [23]
Обогатить пользовательское взаимодействие с веб-фрагментом можно при помощи визуальных элементов и встроенных (или глобальных) стилей CSS.
20.2.2. Ключевые термины
Микроформаты, hCard , Веб-фрагменты.
20.3. Поиск в Веб
20.3.1. Общие сведения
Поисковая система – веб-сайт, предоставляющий возможность поиска информации в Интернете [24]. Большинство поисковых систем ищут информацию на сайтах Всемирной паутины, но существуют также системы, способные искать файлы на ftp-серверах, товары в интернет-магазинах, а также другую информацию.
Как правило, основной частью поисковой системы является поисковая машина (поисковый движок) – комплекс программ, обеспечивающий функциональность поисковой системы [25]. Основными критериями качества работы поисковой машины являются релевантность (степень соответствия запроса и найденного, то есть уместность результата), полнота базы, учет морфологии языка. Индексация информации осуществляется специальными поисковыми роботами. В последнее время появился новый тип поисковых движков, основанных на технологии RSS, а также среди XML -данных разного типа.
Первой поисковой системой для Всемирной паутины был "Wandex", уже не существующий индекс, который создавал "World Wide Web Wanderer" – бот, разработанный Мэтью Грэем (англ. Matthew Gray) из Массачусетского технологического института в 1993. Также в 1993 году появилась поисковая система "Aliweb", работающая до сих пор. Первой полнотекстовой (т. н. "crawler-based", то есть индексирующей ресурсы при помощи робота) поисковой системой стала "WebCrawler", запущенная в 1994. В отличие от своих предшественников, она позволяла пользователям искать по любым ключевым словам на любой веб-странице – с тех пор это стало стандартом во всех основных поисковых системах. Кроме того, это был первый поисковик, о котором было известно в широких кругах. В 1994 был запущен "Lycos", разработанный в университете Карнеги Мелона.
Вскоре появилось множество других конкурирующих поисковых машин, таких как "Excite", "Infoseek", "Inktomi", "Northern Light" и "AltaVista". В некотором смысле они конкурировали с популярными интернет-каталогами, такими, как "Yahoo!". Позже каталоги соединились или добавили к себе поисковые машины, чтобы увеличить функциональность. В 1996 году русскоязычным пользователям интернета стало доступно морфологическое расширение к поисковой машине Altavista и оригинальные российские поисковые машины Rambler и Aport. 23 сентября 1997 была открыта поисковая машина Яндекс. В этот же год была основана компания Google.
В последнее время завоевывает все большую популярность практика применения методов кластерного анализа и метапоиска. Из международных машин такого плана наибольшую известность получила "Clusty" компании Vivisimo. В 2005 году на российских просторах при поддержке МГУ запущен поисковик Nigma, поддерживающий автоматическую кластеризацию. В 2006 году открылась российская метамашина Quintura, предлагающая визуальную кластеризацию в виде облака ключевых слов.
Поисковые cистемы обычно состоят из трех компонент [26]:
- агент (паук или кроулер), который перемещается по Сети и собирает информацию;
- база данных, которая содержит всю информацию, собираемую пауками;
- поисковый механизм, который люди используют как интерфейс для взаимодействия с базой данных.
Cредства поиска типа агентов, пауков, кроулеров и роботов используются для сбора информации о документах, находящихся в Сети Интернет. Это специальные программы, которые занимаются поиском страниц в Сети, извлекают гипертекстовые ссылки на этих страницах и автоматически индексируют информацию, которую они находят для построения базы данных. Каждый поисковый механизм имеет собственный набор правил, определяющих, как cобирать документы. Некоторые следуют за каждой ссылкой на каждой найденной странице и затем, в свою очередь, исследуют каждую ссылку на каждой из новых страниц, и так далее. Некоторые игнорируют ссылки, которые ведут к графическим и звуковым файлам, файлам мультипликации; другие игнорируют ссылки к ресурсам типа баз данных WAIS.
- Агенты – самые "интеллектуальные" из поисковых средств. Они могут делать больше, чем просто искать: они могут выполнять даже транзакции от Вашего имени. Уже сейчас они могут искать сайты специфической тематики и возвращать списки сайтов, отсортированных по их посещаемости. Агенты могут обрабатывать содержание документов, находить и индексировать другие виды ресурсов, не только страницы. Они могут также быть запрограммированы для извлечения информации из уже существующих баз данных. Независимо от информации, которую агенты индексируют, они передают ее обратно базе данных поискового механизма.
- Общий поиск информации в Сети осуществляют программы, известные как пауки. Пауки сообщают о содержании найденного документа, индексируют его и извлекают итоговую информацию. Также они просматривают заголовки, некоторые ссылки и посылают проиндексированную информацию базе данных поискового механизма.
- Кроулеры просматривают заголовки и возвращают только первую ссылку.
- Роботы могут быть запрограммированы так, чтобы переходить по различным ссылкам различной глубины вложенности, выполнять индексацию и даже проверять ссылки в документе. Из-за их природы они могут застревать в циклах, поэтому, проходя по ссылкам, им нужны значительные ресурсы Сети. Однако имеются методы, предназначенные для того, чтобы запретить роботам поиск по сайтам, владельцы которых не желают, чтобы они были проиндексированы.
Как правило, схема работы робота следующая [27]:
- робот ищет файл robots.txt ;
- робот читает страницу, для индексирования которой он был послан (глубина индексирования, то есть чтения страницы зависит от конкретного робота. Некоторые останавливаются только на чтении заглавия страницы и содержимого мета-тегов, другие могут прочитать, скажем, первые 6000 символов на странице, а некоторые индексируют все содержание веб-страницы);
- затем робот может либо удалиться, либо продолжить индексирование сайта;
- через какое-то время робот снова может посетить эту страничку, если существует тег "revisit" или в соответствии с политикой, проводимой поисковой системой.
Когда кто-либо хочет найти информацию, доступную в Интернет, он посещает страницу поисковой системы и заполняет форму, детализирующую информацию, которая ему необходима. Здесь могут использоваться ключевые слова, даты и другие критерии. Критерии в форме поиска должны соответствовать критериям, используемым агентами при индексации информации, которую они нашли при перемещении по Сети.
База данных отыскивает предмет запроса, основанный на информации, указанной в заполненной форме, и выводит соответствующие документы, подготовленные базой данных. Чтобы определить порядок, в котором список документов будет показан, база данных применяет алгоритм ранжирования. В идеальном случае, документы, наиболее релевантные пользовательскому запросу будут помещены первыми в списке. Различные поисковые системы используют различные алгоритмы ранжирования, однако, основные принципы определения релевантности следующие:
- количество слов запроса в текстовом содержимом документа (т.е. в html-коде);
- тэги, в которых эти слова располагаются;
- местоположение искомых слов в документе;
- удельный вес слов, относительно которых определяется релевантность, в общем количестве слов документа;
- время – как долго страница находится в базе поискового сервера;
- индекс цитируемости – как много ссылок на данную страницу ведет с других страниц, зарегистрированных в базе поисковика.
База данных выводит ранжированный подобным образом список документов с HTML и возвращает его человеку, сделавшему запрос. Различные поисковые механизмы также выбирают различные способы показа полученного списка – некоторые показывают только ссылки; другие выводят ссылки с первыми несколькими предложениями, содержащимися в документе или заголовок документа вместе с ссылкой.
Основополагающими характеристиками информационно- поисковых систем является полнота и релевантность результатов поиска [28]. Полнота поиска тесно связано с оперативностью охвата информации системой. Созданная однажды база данных Интернет-ресурсов является "слепком" состояния Сети в конкретный момент. Если эта база не будет обновляться постоянно и оперативно, присутствующие в ней ссылки на документы станут мертвыми. Кроме того, отсутствие оперативности, обновления баз данных не позволит пользователю отслеживать последние изменения в его предметной области.
Полнота охвата ресурсов Сети – это один из двух главных аспектов характеристики полноты сетевой информационно- поисковой системы. Второй аспект связан с полнотой информации, предъявляемой пользователю по его запросу (рис. 20.7).

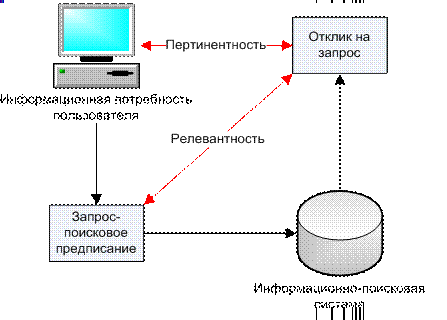
Под релевантностью понимается формальное соответствие информации, выдаваемой системой, запросу [28]. Это не характерно для формальной релевантности, однако, на практике используется другое, неформальное понятие – пертинентность.
Для пользователя пертинетность, соотношение объема полезной для него информации к общему объему полученной информации, имеет решающее значение (рис. 20.8) [28]. Достижение высокой пертинентности – основное поле конкурентной борьбы современных поисковых систем. Именно для максимального удовлетворения информационных потребностей пользователей информационно- поисковые системы сегодня максимально интеллектуализируются – получили широкое практическое применение теории и методы семантических сетей, контент-анализа и глубинного анализа текстов (Text Mining).
Отдельного рассмотрения заслуживает возможность поиска по параметрам документов, которая позволяет ограничивать диапазон поиска значениями URL, датам, заглавий и т.п. Чаще всего выйти на возможность поиска по параметрам можно из режима расширенного поиска. В режиме расширенного поиска для ввода значений отдельных параметров предлагается весь диапазон возможностей Веб-интерфейса.
Средства повышения пертинентности в современных системах, помимо возможностей уточнения формулировки запросов, включает и весовые критерии, позволяющие ранжировать найденные документы и выдавать пользователю для просмотра наиболее весомые документы, либо вообще ограничиваться выдачей не более заданного числа наиболее весомых документов. В последнем случае, естественно, страдает полнота выдачи. Т.е. при этом полнота и релевантность являются антагонистическими характеристиками – чем выше релевантность, тем ниже полнота и наоборот. Проблеме релевантности, а особенно пертинентности уделяется большое внимание в современных системах. Так, например, служба Google реализовала алгоритмы достижения неформальной релевантности, и именно благодаря этому в свое время стала самой популярной системой в Интернет.
Ранжирование выдаваемых документов может выполняться по дате создания/обновления документа, по степени важности (многие системы оценивают важность документов по весовым критериям или по количеству ссылок на них, т.е. по цитированию). Ранжирование по дате имеет особое значение при поиске новостных сообщений средств массовой информации и информационных агентств. Ранжирование по индексу цитируемости, аналогичное оценке значимости научных публикаций в традиционной научной среде впервые ввела Google, продемонстрировавшая эффективность такого подхода для Веб-пространства.
В последнее время получили развитие такие направления контент-анализа, как "Data Mining" и "Text Mining", которые предполагают автоматическое выявление нового смысла из текстовых массивов, новых данных, феноменов, фактов – знаний. Все чаще возникают попытки привлечения методов контент-анализа, а точнее Text Mining в реальные поисковые системы. И эти попытки не умозрительны – они обусловлены объемами и темпами роста Сети. Во многие современные сетевые поисковые системы внедрены такие компоненты, как:
- автоматическая группировка документов, по определенному заранее классификатору;
- автоматическое определение новых, не заданных заранее классов, на основе неструктурированных или слабо структурированных документов;
- ранжирование документов по смысловой релевантности;
- выявление семантически подобных документов – поиск подобных документов на основе эталона;
- автоматический анализ и смысловое преобразование запросов пользователей.
Рейтинг поисковых систем в целом по миру в 2009 (по данным Nielsen NetRatings) [29].
-
Основные поисковые системы
- http://www.google.com/ – 46.2%
- http://www.yahoo.com/ – 22.5%
- http://search.msn.com/ – 12.6%
- http://www.aol.com/ – 5.4%
- http://www.myway.com/ – 2.2%
- http://www.ask.com/ – 1.6%
- http://search.netscape.com/ – 1.6%
- Прочие поисковые системы (7.9%)
Рейтинг поисковых систем в России в 2009 (по данным SpyLog).
- Основные поисковые системы
- http://www.yandex.ru/ – 54.8267%
- http://www.rambler.ru/ – 21.7645%
- http://www.google.com/ – 15.6207%
- http://www.mail.ru/ – 4.5466%
- http://www.aport.ru/ – 1.5788%
- Прочие поисковые системы (1,6627%)
Из перечисленных поисковых систем не все имеют собственный поисковый алгоритм – так, например, Mail.ru использует поисковый механизм Яндекса.
OpenSearch – набор технологий, позволяющих веб-сайтам и поисковым системам публиковать результаты поиска в форматах, удобных для распространения и сбора [30].
OpenSearch был разработан A9, дочерней компанией Amazon.com. Первая версия, OpenSearch 1.0, была представлена на конференции, посвященной Web 2.0 в марте 2005 года. Черновые версии OpenSearch 1.1 были опубликованы в сентябре и декабре 2005 года. Спецификация OpenSearch лицензирована компанией A9 по Creative Commons Attribution-ShareAlike 2.5 License.
- XML -файлы с описанием поисковой системы ;
- стандартизованный синтаксис запросов, описывающий, где и как получать результаты поиска;
- RSS (в OpenSearch 1.0) или более общий OpenSearch -ответ (в OpenSearch 1.1) – форматы, предоставляющие поисковые результаты;
- OpenSearch -агрегаторы – сайты, позволяющие отображать OpenSearch -результаты;
- элементы на веб-странице для автоматического обнаружения пользовательским клиентом возможности использования OpenSearch на данном сайте.
Версия 1.0 спецификации позволяла предоставлять результаты поисковых запросов только в формате RSS, в то время как версия 1.1 позволяет использовать. RSS и Atom – единственные форматы, формально поддерживаемые OpenSearch -агрегаторами, но и другие типы вполне допустимы, например, HTML.
Поисковые системы и ПО, поддерживающие OpenSearch:
- Википедия предлагает статьи, соответствующие введенной строке;
- Mozilla Firefox версии 2 и выше позволяет интегрировать поисковые системы, поддерживающие OpenSearch, со своей панелью поиска;
- Internet Explorer версии 7 и выше так же позволяет добавлять OpenSearch -системы;
- Google Chrome;
- Windows 7 и Microsoft Search Server. чтобы дать пользователям возможность общего поиска через единое место.
20.3.2. Ключевые термины
Поисковая система, поисковая машина, Агент, Поисковый робот, Полнота результатов поиска, Релевантность результатов поиска, Пертинентность, OpenSearch.