Семантический веб и микроформаты
Презентацию к данной лекции Вы можете скачать ![]() здесь.
здесь.
20.1. Семантический веб
20.1.1. Введение
Семантическая паутина ( Semantic Web ) – часть глобальной концепции развития сети Интернет, целью которой является реализация возможности машинной обработки информации, доступной во Всемирной паутине. Основной акцент концепции делается на работе с метаданными, однозначно характеризующими свойства и содержание ресурсов Всемирной паутины, вместо используемого в настоящее время текстового анализа документов. Термин впервые введен сэром Тимом Бернерсом-Ли в мае 2001 года в журнале "Scientific American" [1], и называется им "следующим шагом в развитии Всемирной паутины". В семантической паутине предполагается повсеместное использование, во-первых, универсальных идентификаторов ресурсов ( URI ), а во-вторых – онтологий и яз ыков описания метаданных.
Эта концепция была принята и продвигается Консорциумом W3 [2]. Для ее внедрения предполагается создание сети документов, содержащих метаданные о ресурсах Всемирной паутины и существующей параллельно с ними. Тогда как сами ресурсы предназначены для восприятия человеком, метаданные используются машинами ( поисковыми роботами и другими интеллектуальными агентами) для проведения однозначных логических заключений о свойствах этих ресурсов.
20.1.2. История
Semantic Web был задуман консорциумом W3 достаточно давно. С середины 90-х писались разные статьи и заметки, которые не привлекали особого внимания широкой общественности. Переломным моментом стала статья, опубликованная 17 мая 2001 г. в журнале Scientific American Тимом Бернерса-Ли, Джеймсом Хэндлером и Орой Лассила "The Semantic Web "
У этой статьи было одно назначение – привлечь внимание к Semantic Web всех, кого только можно было. Интерес к Semantic Web в 2001 году, конечно, появился, но профессиональные разработчики после прочтения этой статьи поняли, что до прихода Semantic Web еще должно пройти много времени, т.к. W3C не разработал к тому времени совершенно никаких технологий (кроме языка RDF ), которые могли бы хоть как-то помочь осуществить задуманное.
10 февраля 2004 г. на сайте W3C появляется описание языка " OWL " (язык описания онтологий ).
Через полгода новый язык описания онтологий OWL стал поддерживать редактор онтологий Protege – разработка Стенфордского Университета. В это же время Semantic Web начало активно интересоваться международное научное сообщество. В разных изданиях появляется вал статей по Semantic Web. Председатель Консорциума W3 Тим Бернерс-Ли получает орден Сера из рук Королевы Соединенного Королевства.
В 2005 г. на сайте W3 появляется описание RDF /A – синтаксиса, который уже сейчас позволяет встраивать метаданные RDF в документы XHTML.
10 марта 2006 г. выходит RDF /A Primer. Таким образом, уходя по цепочке XML - RDF -RDFS- OWL все дальше и дальше от существующей в сети HTML разметки Semantic Web был "привязан" к XHTML.
В 2006 г. также завершилась разработка языка запросов к RDF документам с SQL-подобным синтаксисом, его окончательное название – SPARQL.
20.1.3. Основные идеи
Semantic Web – это эволюция World Wide Web, информация в которой машинно-обрабатываемая (а не только ориентированная на обработку человеком), таким образом, позволяя браузерам или другим программным агентам производить поиск, распределять и комбинировать информацию намного проще [3]. Semantic Web предусматривает объединение этих разных видов информации в единую структуру, где каждому элементу "человеческой" информации будет соответствовать машинный код – специальный смысловой тэг.
Semantic Web в математической форме представляет собой разновидность графа – набора вершин, соединенных дугами. В Semantic Web роль вершин выполняют понятия базы знаний, а дуги (причем направленные) задают отношения между ними. Таким образом, семантическая сеть отражает семантику предметной области в виде понятий и отношений. Идея состоит в том, чтобы глобальной семантической сетью было подмножество систем, которые замкнуты на специфичных путях достижения достаточного удобства для машин. Таким образом, Семантическая Сеть сама собой не будет задавать выводящую машину. Она будет задавать валидность операции и требовать связей между ними.
Рассмотрим состояние современной глобальной сети и принципы работы современных поисковых систем [4].
Представление информации в сети:
- теги в HTML не несут семантической нагрузки;
- процент полезной информации меньше процента разметки;
- разметка, в том числе, из-за большой сложности и вложенности (например, проблема табличной верстки) содержит много ошибок.
Информация предназначена только для просмотра человеком, из чего вытекают следующие принципы работы поисковых систем сегодня:
- весовые коэффициенты на основе расположения слов;
- важность слова в зависимости от тега;
- релевантность (т.е. сколько раз встречается данное слово в данном документе по отношению другим);
- анализ "веса" ссылок в зависимости от количества ссылок указывающих на данную страницу.
Из-за этого возникают следующие проблемы:
- машины не понимают и, следовательно, не анализируют смысл информации
- поиск неудобен и сложен, часто результаты неудовлетворительные и не релевантные;
- оптимизаторы ( SEO – Search Engine Optimizations) "играют" на несовершенстве алгоритмов поисковых систем, умышленно нарушая правильность разметки для кратковременного эффекта высоких позиций в поисковых запросах.
Но есть и ряд положительных тенденций, которые позволяют практически приблизиться к Semantic Web:
- появилась возможность эффективно отделять разметку от оформления путем применения CSS;
- на смену HTML пришла на замену разновидность XML языка описания документов – XHTML.
Для того чтобы решить все вышеперечисленные проблемы Консорциумом W3 рекомендовал решение – применение Semantic Web.
Семантическая паутина – это надстройка над существующей Всемирной паутиной, которая призвана сделать размещенную в ней информацию более понятной для компьютеров. Машинная обработка возможна в семантической паутине благодаря двум ее важнейшим характеристикам [7]:
- Повсеместное использование универсальных идентификаторов ресурсов ( URI ). Традиционная схема использования таких идентификаторов в современном Интернете сводится к установке ссылок, ведущих на объект, им адресуемый. Очевидным свойством такой ссылки является возможность "загрузки" объекта, на который она указывает. Таким объектом может быть Веб-страница, файл произвольного содержания, фрагмент Веб-страницы, а также неявное указание на обращение к реально существующему физическому ресурсу по протоколу, отличному от HTTP (например, ссылки mailto:). Концепция семантической паутины расширяет это понятие, включая в него ресурсы, недоступные для скачивания. Адресуемыми с помощью URI ресурсами могут быть, например, отдельные люди, города и другие географические сущности, художественные артефакты и т. д. К идентификатору предъявляются несколько простых требований: он должен быть стр окой определенного формата, уникальной, а также адресующей реально существующий объект.
- Повсеместное использование онтологий и языков описания метаданных. Современные методы автоматической обработки данных, доступных в Интернете, как правило, основаны на частотном и лексическом анализе текстового содержимого (хотя есть и исключения: Swoogle или Intellidimension Semantic Web Search Engine, например), которое прежде всего предназначено для восприятия человеком. В семантической паутине предлагается использовать форматы описания, доступные для машинной обработки (например, семейство форматов, часто упоминаемое в литературе как " Semantic Web family": RDF, RDF Schema или RDF -S и OWL ), в свою очередь, использующие URI для адресации описываемых и описывающих объектов, а также онтологии и дескриптивные логики в качестве базовых математических формализмов.
Пользователи получат массу вполне ощутимых преимуществ от реализации Семантической Сети. Когда все программы, будь то браузер, почтовый клиент или Веб-сайт, смогут понимать смысл той информации, с которой работает пользователь. Они смогут предоставлять ему дополнительные сервисы. Работа человека станет более эффективной, серфинг более осмысленным, а поиск в Интернете – более точным.
Здесь стоит отметить, что поисковые агенты получат возможность взаимодействовать не только с информацией, хранимой в сети и доступной ей для обработки, но еще и между собой. Это дает возможность, как проверять результат, полученный одним агентом, так и находить более качественное решение, а также уточнять полученные результаты. Это напоминает модель взаимодействия двух людей, обладающих определенными знаниями и ведущих диалог. Нельзя не заметить, что в данном случае у людей вероятно возникновение нового знания в результате этого диалога. То же самое можно сказать об агентах – в результате взаимодействия двух агентов может появиться новое для агента знание.
Однако при всей очевидной важности Semantic Web существует множество трудностей и неразрешимостей в его реализации.
Мечта логиков последнего столетия – найти язык, в котором все предложения были бы ложны или истины и, по возможности, без других вариантов. Эта попытка ограничить язык, чтобы избежать возможность внутренних противоречивых утверждений, которые не могут быть разделены только на истину и ее отсутствие.
В Semantic Web это выглядит как сугубо академическая проблема: когда на самом деле нечто оперирует с массой недостоверной информации с любой точки зрения и ограничивается тем, что использует для ограничения подсистемы Веб. Очевидно, оно не должно иметь возможность выводить внутренне-противоречивые утверждения, но это не страшно, когда язык достаточно мощный, чтобы описать это. Действительно, достоверные системы должны дать нам мощность сказать "Утверждение ложно" и цикл, который, если верить замкнутому противоречию будет разрешен сам по себе или преднамеренно. Типичный ответ системы, которая ищет утверждения, приводящие к внутреннему противоречию, возможно, будет похож на результат поиска противоречия из того же источника [5].
Проблема ложности не только в возможности выразить парадокс, но и в возможности, учитывая парадокс вывода иметь возможность вывести ложность.
Очень важным моментом является то, как информация будет представлена в сети. Тут есть определенные требования.
Системы представления знаний должны обладать следующими свойствами [4]:
- они должны иметь по возможности компактный синтаксис;
- в них должна быть четко определенная семантика такая, чтобы любой мог сказать, что это означает;
- она должна обладать достаточными описательными возможностями, чтобы представлять знания человека;
- она должна иметь эффективный, мощный и понимаемый механизм вывода;
- она должна иметь возможность работать с большими базами данных.
Доказана сложность достижения третьего и четвертого пункта одновременно [4]. Бинарные модели позволяют снизить сложность достижения этих пунктов. Когда отношения простые, их легче описать и произвести вывод на них. Отметим, что любую n -арную модель можно привести к бинарной, упростив вычисления и сложность создания агента, который будет с ней работать.
Все это позволяет расширить возможности поиска, поиск в сети становится не просто сбором документов и оценки связи слов, например, стоящих друг от друга на определенном расстоянии, которым при формировании результатов запроса расставляются веса, влияющие на их порядок при выдаче
Таким образом, достигается один из главных эффектов Semantic Web – получение нового, "синтетического" смысла, выводимого на связях документов, содержавших этот смысл только потенциально. Такой результат, очевидно, следует понимать как первый этап извлечения "глубинной" семантики первого уровня.
С другой стороны, это уже означает, что, получив отношения между документами, можно шагнуть гораздо дальше простой выдачи текстовой информации. Можно не только выдать результаты, можно их, как минимум, проанализировать и подготовить, а на следующем шаге – создать автоматизированные системы обработки этой информации, тем самым, решив целый ряд практических проблем.
Технологии Semantic Web могут быть использованы в разных прикладных областях. Например, в области интеграции данных, в результате чего данные из разных источников и в разных форматах могут быть интегрированы в одном приложении; в области описания и классификации ресурсов для обеспечения более качественных, учитывающих предметную область, средств поиска информации; в области каталогизации, для описания содержимого и взаимосвязей между Веб-сайтами, страницами, или цифровыми библиотеками; в области программных агентов с развитой логикой, для облегчения распространения информации; в области рейтинговых систем; при описании коллекций страниц которые логически составляют один документ; для описания прав интеллектуальной собственности Веб-страниц и во многих других.
Для того чтобы достичь целей описанных выше, важнее всего иметь возможность определить и описать взаимоотношения между данными (т.е. ресурсами) в Сети. Это не слишком сильно отличается от использования гиперссылок в современном Интернете, которые связывают текущую Веб-страницу с другой: гиперссылки определяют связь между текущей страницей и целевой. Одним из главных отличий является то, что в Семантической сети такие связи могут быть установлены между любыми двумя ресурсами – отсутствует само понятие: "текущая страница". Другое важное отличие это то, что связь (т.е. ссылка) сама – поименована, в то время как ссылки используемые людьми в (традиционном) Интернете не именуются, и их роль выводится читателем. Определение таких связей позволяет организовать более качественный и автоматический обмен данными. RDF, который является одним из фундаментальных строительных блоков, из которых состоит Семантическая Паутина, предоставляет формальные средства для такого обмена.
На эту основу, опираются дополнительные строительные блоки. Приведем несколько примеров.
- Инструменты для формирования более точной и детальной классификации и описания характеристик таких отношений. Это гарантирует способность к взаимодействию и более сложные виды автоматической обработки. Например, сообщество может договориться о том, какое имя использовать для описания ссылки связывающей страницу с календарем. Это имя затем может быть использовано множеством разных пользователей и приложений без необходимости каждый раз переопределять такие имена (например, RDF Schemas, OWL, SKOS).
- Инструменты для запроса информации, описанной с помощью таких отношений (например, SPARQL ).
- В более сложных случаях существуют специальные инструменты для определения логических взаимосвязей между ресурсами и связями. Например, если ссылка связывает человека с его/ее e-mail адресом, то вполне оправданно провозгласить, что e-mail адрес – уникален, т.е. адрес не разделяется среди нескольких человек (например, OWL, Rules).
- Инструменты для извлечения из и для связывания с традиционными источниками данных, для того, чтобы гарантировать их способность обмениваться информацией с другими источниками (например, GRDDL, RDF ).
Как и все инновационные технологии, Semantic Web претерпевает эволюцию: сначала развивается в исследовательских лабораториях, затем получает поддержку Open Source сообщества, потом появляются небольшие специализированные "стартапы", и, наконец, технология начинает получать широкую поддержку со стороны бизнеса. Так же, классическая Всемирная Паутина изначально была разработана в центре Физики Высоких Энергий.
В настоящее время, Semantic Web все чаще и чаще используется маленькими и большими компаниями. Oracle, IBM, Adobe, Software AG, или Northrop Grumman – только некоторые, из больших корпораций, которые уже воспользовались этой технологией, и продают как инструменты, так и целостные бизнес решения. Крупные прикладные области, такие как медицина, заинтересованы в тех средствах интеграции данных, которые предоставляет Semantic Web.
20.1.4. Технологии и инструменты
20.1.4.1. Стек стандартов Semantic Web
Десятилетиями создатели информационных технологий упускали из виду предмет своей деятельности – информацию. Точнее, информация присутствовала, но как-то неявно, обычно ее отождествляли с данными. Semantic Web – одно из тех явлений в мире ИТ, которые заставляют всерьез задуматься о различии между данными и информацией [6].
Но еще в начале 90-х годов Бернерс-Ли и Калио предполагали возможность включения метаданных в гиперсвязи, задумываясь о том, как дополнить их сведениями, относящимися к передаваемым данным. Практика показывает, что для общения между людьми метаданные критического значения не имеют: люди сами являются носителями контекста, в большинстве случаев им достаточного для понимания смысла сообщения, описывать переданное сообщение не требуется; правда, нередко неверное понимание контекста приводит к ошибкам. Иное дело машины. Здесь контекст должен быть зашит жестко, чтобы полученное сообщение однозначно интерпретировалось (например, если данные поступают в систему от датчика). Если же это невозможно, то нужны дополнительные сведения о том, как следует интерпретировать полученное сообщение; такие дополнительные данные и называют метаданными. Эти метаданные могут интерпр етироваться машинными средствами, а потому открывают возможность установить взаимоотношения не только между людьми, но и между сайтами, и между устр ойствами, включенными в Сеть. Встраивание метаданных в гиперсвязи – главное отличие пропагандируемого Бернерсом-Ли второго поколения Всемирной Паутины, которое он называет Semantic Web, или Веб для машин.
Предшествующий опыт подсказывает, что для создания Semantic Web следует построить информационную коммуникационную модель, аналогичную семиуровневой модели OSI (но в приложении к Веб) и ориентированную на обмен информацией, а не данными. Именно так и поступил Бернерс-Ли. Начиная с 1998 года, он популяризирует разработанную им многоуровневую модель Semantic Web. В наиболее наглядном виде она может быть оформлена в форме стека уже существующих и проектируемых стандартов. На рис. 20.1 и рис. 20.2 представлена редакция стека, датируемая 2000-м и 2005 годом. Используемые для построения модели понятия и конструкции достаточно сложны и специфичны, поэтому опишем эти модели на самом поверхностном уровне.

Источник: О стеке стандартов Semantic Web [6]
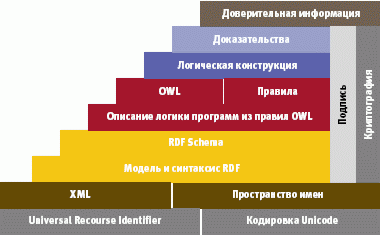
Источник: О стеке стандартов Semantic Web [6]
Если проводить аналогию с моделью OSI, то нижние уровни URI, кодировка Unicode, XML и XML Schema соответствуют нижним уровням семиуровневой модели, они обеспечивают представление, но не налагают никаких семантических ограничений на содержание этих документов. Основу модели составляют RDF (Resource Description Framework). Модель RDF представляет собой структуру метаданных, предназначенную для описания ресурсов в форме триады. Эту триаду называют субъектно-предикативно-объектным выражением на языке XML. В 1999 году работы по созданию RDF были инициированы компаниями Apple и Netscape, в 2004 году была опубликована совершенно новая редакция RDF 2.0. Уровнем выше стоит RDF Schema, она служит ср едством для описания свойств и классов RDF -ресурсов, а также задает семантику для иерархий-обобщений таких свойств и классов.
Для представления модели данных, отражающей свойства реального мира, используется еще одно довольно непростое понятие – " онтология ". Оно заимствовано из теории систем, в данном случае его можно интерпретировать как некоторый объем знаний. Для описания онтологий служит специальный язык OWL.
Развивая аналогию между моделью OSI и стеком стандартов Semantic Web, отметим, что в обеих моделях на нижнем уровне располагается "физическое представление", но в первом случае – представление данных, а во втором – информации. А на верхнем уровне – "очищенное" представление, готовое для использования. Различие состоит в том, что в модели OSI – это данные, а в модели Semantic Web – информация. Работа и той, и другой модели сводится к установлению соответствия между нижним и верхним уровнями.
Стек стандартов Semantic Web описывает интерфейсы между уровнями, не более того. Но кроме стандартов нужны еще и средства для реализации, поэтому кроме самого стека активно развиваются сервисы, обеспечивающие работу Semantic Web ( Semantic Web Services). К сожалению, архитектура Semantic Web Services Architecture еще меньше проработана, чем Semantic Web, известны лишь отдельные исследования, выполненные в университетских лабораториях.
С практической точки зрения наибольший интерес представляет не собственно Semantic Web, а процесс сближения идей Semantic Web и Веб-сервисов. Развитие в этом направлении может привести к созданию нового поколения сервисов, которые пока условно называют "интеллектуальными Веб-сервисами".