Нормализация
5.4 Определение первой нормальной формы. Правило приведения
Рассмотрим ненормализованную сущность "Подписка" с полями "Подписчик" и "Издание" (таблица 5.3). Таблица, представляющая это отношение, может быть создана вручную, если необходимо узнать, на какие издания вы подписываетесь. Ключевой столбец - "Подписчик". Понятно, если я напишу в первом столбце "Иванов", то во втором можно будет перечислить все издания, разделив их, например, запятой. Такая форма понятна человеку. Можно считать, что это ненормализованная таблица. На самом деле, она находится в, так называемой, непервой нормальной форме. Англоязычные исследователи любят такие "несерьезные" термины. Раз, кроме первой нормальной формы, существует что-то еще, пусть будет называться непервой формой.
| ПОДПИСЧИК | ИЗДАНИЕ |
|---|---|
| Иванов |
Правда, Известия, Коммерсант |
| Петров | ДАН |
| ПОДПИСЧИК | ИЗДАНИЕ |
| Иванов | Правда |
| Иванов | Известия |
| Иванов | Коммерсант |
| Петров |
Почему ненормализованные отношения неудобны? Вспомните, что значения атрибутов считаются атомарными. Это означает, что их нельзя препарировать, разделяя на составные части. Например, невозможно определить, что Иванов подписывается на Известия, но можно найти тех, кто подписывается сразу на Правду, Известия и Коммерсант (но не на Известия, Правду, и Коммерсант).
Для получения первой нормальной формы (сокращенно, 1НФ или 1NF) необходимо преобразование, обеспечивающее атомарность атрибутов. Выписываем по одной строке для каждого издания и каждого подписчика (таблица 5.4). Естественно, мы вынуждены повторять фамилии лиц, подписавшихся более чем на одно издание. Иванов у нас повторен трижды. Но теперь ключом становятся оба столбца. То есть все столбцы отношения ключевые. Получена первая нормальная форма.
Использованный способ нормализации до 1НФ называется выравниванием таблицы.
Иногда говорят, что нормализация необходима для минимизации объема базы. Но при переходе к 1НФ мы увеличили избыточность. На самом деле, нормализация нужна для устранения аномалий.
Остается дать определения. Их будет два: 1НФ через атрибуты, 1НФ через ключи.
Определение (1НФа (через атрибуты)). Сущность (отношение) находится в 1НФ, если значения всех ее атрибутов атомарны.
Определение (1НФк (через ключи)). Сущность (отношение) находится в 1НФ, если она имеет ключ.
На самом деле, из определения через атрибуты следует определение через ключи.
Утверждение. Из определения 1НФа следует определение 1НФк.
Доказательство. В самом деле, по определению реляционного отношения кортежи в отношении не повторяются, а если еще атрибуты атомарны, то ключ в крайнем случае образуют все атрибуты, то есть ключ всегда существует.
Замечание. Обратное утверждение не верно, из-за существования непервой нормальной формы.
Для того, чтобы получить правила приведения к 1НФ рассмотрим пример (рисунок 5.5). Кстати, почему я все время отсылаю вас к примерам? Потому что для человека мышление по образцам более естественно, чем мышление с помощью логики.
Итак, у нас с вами некоторая сущность "Сотрудник". Название отношения или сущности всегда задается в единственном числе, хотя экземпляров сущности может быть много. "Табельный номер" - ключ. Имеются атрибуты: "Фамилия, Имя, Отчество", "Должность", "Специальность1", "Специ-альность2", "Оклад", "Телефон1", "Телефон2", "Телефон3", "Дата зачисления или увольнения". Что в этом отношении не хорошо? А кто сказал, что специальностей не больше двух? А, если их три, что делать? А если телефонов четыре?
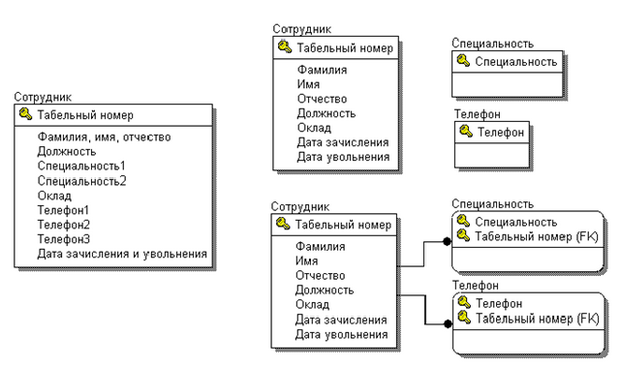
Есть еще атрибут "Дата зачисления или увольнения". Как узнать какая дата записана, если она одна? Понятно, можно написать: "1 марта 2010 уволен". Но, наверное, такие вольности приведут к неоправданному усложнению процедурной части программы из-за неатомарных значений.
Давайте сделаем несколько оправданных предположений. Разумнее атрибут "Дата зачисления и увольнения" заменить на два атрибута: "Дата зачисления" и "Дата увольнения" Раз специальностей и телефонов у человека может быть много, давайте считать, что это отдельные сущности. Выделим их, как показано на рисунке 5.2 вверху справа. Число экземпляров у сущностей "Специальность" и "Телефон" может быть любым.
А теперь обратим внимание на один важный нюанс: нас интересуют не специальности и телефоны вообще, а только имеющиеся у данного человека. Значит новые сущности следует привязать к табельному номеру сотрудника с помощью идентифицирующих связей (рисунок 5.2 внизу справа).
Описанный способ приведения к 1НФ называется выделением в отдельные отношения.
Теперь будут понятны следующие правила.
5.4.1 Правила приведения к первой нормальной форме
Для многозначных атрибутов возможны два пути:
- Выделить многозначные атрибуты (в примере в таблицах 5.3 и 5.4 это "Издание").
- Выбрать путь решения - выравнивание таблицы или выделение в отдельное отношение.
- В варианте с выравниванием таблицы каждый кортеж с многозначным столбцом разбивается на столько строк, сколько повторов имеется.
- В варианте с выделением в отдельное решение к многозначному столбцу присоединяется ключ и, с использованием теоремы Хиса, образуется новая сущность. Ключ образованной сущности может состоять из неключевых и ключевых столбцов исходной сущности. Связь идентифицирующая.
Для составных и повторяющихся атрибутов:
- Разделить составные атрибуты (в последнем примере это "Фамилия, Имя, Отчество" и "Дата зачисления и увольнения") на простые (атомарные) "Дата зачисления" и "Дата увольнения".
- Выделить "повторяющиеся" (однотипные, близкие) атрибуты (в последнем примере это "Специальностью и "Телефон"). Термины, обозначающие близкие атрибуты, могут существенно различаться, но их смыслы должны допускать объединение понятий в одну группу.
- Для каждой такой группы атрибутов создать новую справочную сущность с одним атрибутом для повторяющейся группы.
- Перенести в нее все значения повторяющихся атрибутов
- Установить идентифицирующую связь типа
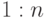 от исходной сущности к каждой созданной справочной сущности.
от исходной сущности к каждой созданной справочной сущности.
Почему связь должна быть идентифицирующей? Потому что выделенные справочные сущности только уточняют свойства основной сущности, и без привязки к экземпляру основной сущности их смысл теряется. Например, на рисунке 5.5 справочная сущность "Специальность" имеет смысл "Специальность данного сотрудника", а без привязки ее смысл определялся как "Специальность вообще", что не соответствует семантике исходной сущности.
Для соединения преобразованной основной сущности со справочными в ERwin подхватываем инструмент "Идентифицирующая связь" ("Identifying relationship") и щелкаем сначала по основной сущности, а затем по вспомогательной. В получившейся диаграмме выделим два важных обстоятельства:
- основная сущность осталась сильной, а обе вспомогательные сущности отмечены скруглением углов как слабые;
- идентифицирующие связи вызвали миграцию ключа сильной сущности в ключевую область слабых сущностей в двойном качестве - как внешнего ключа и как части первичного ключа.
Заметим, что приведенные правила приведения, как и все другие, содержат нечеткости. Поэтому в их применении следует соблюдать меру. Так, попытка выделить дополнительную сущность "Издание" в примере в таблице 5.3 приведет в лучшем случае к введению суррогатного ключ, не очень оправданного в этой ситуации.
5.5 Замечание о непервой нормальной форме (Н1НФ, NFNF, NF)
Определим непервую нормальную форму как первую нормальную форму (1НФ) удовлетворяющую условию 1НФк, но не удовлетворяющую условию 1НФа. Для обозначения непервой нормальной формы используют аббревиатуры Н1НФ, NFNF, и даже NF2.
Основное преимущество модели, развиваемой на основе Н1НФ, в том, что хранить в базе можно значения не только атомарных, но и конструируемых, в том числе, реляционно-значных типов. В частности, отношения могут содержать вложенные отношения. Тем самым устраняется один из основных недостатков реляционного подхода - отсутствие агрегатов. В современных базах практически всегда используется непервая нормальная форма. Это позволяет, в частности, применять языки регулярных выражений. Хранить в запросах можно элементы со сложной структурой и с помощью регулярных выражений выделить то, что нужно, или поменять какую-то часть или что-нибудь еще. Например, номера счетов очень часто конструируются как набор значащих и контрольных полей. Мы еще вспомним Н1НФ при изучении моделей данных со сложными значениями и объектных баз данных в "Объектные модели данных" .