Моделирование с Maxima
6.2.3 Проверка статистических гипотез
Для проверки статистических гипотез в Maxima включён пакет stats. Он позволяет, в частности, проводить сопоставление средних или дисперсий двух выборок. Предусмотрена и проверка нормальности распределения, а также ряд других стандартных тестов. для использования stats пакет необходимо загрузить командой load("stats"); необходимые пакеты descriptive и distrib загружаются автоматически.
Функции пакета stats возвращают данные типа  . Объекты этого типа содержат необходимые результаты для анализа статистических распределений и проверки гипотез.
. Объекты этого типа содержат необходимые результаты для анализа статистических распределений и проверки гипотез.
Функция  позволяет оценить среднее значение и доверительный интервал по выборке. Синтаксис вызова: test_mean (
позволяет оценить среднее значение и доверительный интервал по выборке. Синтаксис вызова: test_mean ( ) или test_mean (
) или test_mean ( ).
).
Функция использует проверку по критерию Стьюдента. Аргумент — список или одномерная матрица с тестируемой выборкой. Возможно также использование центральной предельной теоремы (опция  ). Опции :
). Опции :
- 'mean, по умолчанию 0, ожидаемое среднее значение;
- 'alternative, по умолчанию 'twosided, вид проверяемой гипотезы (возможные значения 'twosided, 'greater и 'less);
- 'dev, по умолчанию 'unknown, величина среднеквадратичного отклонения, если оно известно ('unknown или положительное выражение);
- 'conflevel, по умолчанию 95/100, уровень значимости для доверительного интервала (величина в пределах от 0 до 1);
-
'asymptotic, по умолчанию
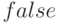 , указывает какой критерий использовать (
, указывает какой критерий использовать (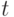 -критерий или центральную предельную теорему).
-критерий или центральную предельную теорему).
Результаты, которые возвращает функция:
- 'mean_estimate — среднее по выборке;
- 'conf_level — уровень значимости, выбранный пользователем;
- 'conf_interval — оценка доверительного интервала;
- 'method — использованная процедура;
-
'hypotheses — проверяемые статистические гипотезы (нулевая
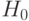 и альтернативная
и альтернативная 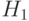 );
); - 'statistic — число степеней свободы для проверки нулевой гипотезы;
- 'distribution — оценка распределения распределения выборки;
-
'p_value — вероятность ошибочного выбора гипотезы , если выполняется .
Примеры использования :
Выполняется -тест с неизвестной дисперсией. Нулевая гипотеза : среднее равно 50 против альтернативной гипотезы : среднее меньше 50; в соответствии с результатами расчёта, величина вероятности  слишком велика, чтобы отвергнуть .
слишком велика, чтобы отвергнуть .
(%i1) load("stats")$
(%i2) data: [78,64,35,45,45,75,43,74,42,42]$
(%i3) test_mean(data,'conflevel=0.9,'alternative='less,'mean=50);![(\%o3)\
\begin{pmatrix}
MEAN\ TEST\cr
mean\_estimate=54.3\cr
conf\_level=0.9\cr
conf\_interval=[-\infty ,61.51314273502714]\cr
method=Exact\ t-test.\ Unknown\ variance.\cr
hypotheses=H0:\ mean = 50 ,\ H1:\ mean < 50\cr
statistic=.8244705235071678\cr
distribution=[student\_t,9]\cr
p\_value=.7845100411786887
\end{pmatrix}](/sites/default/files/tex_cache/5ce55259377e6abf10f59592b131052b.png)
Следующий тест — проверка гипотезы (среднее равно 50) против альтернативной гипотезы среднее по выборке отлично от 50. В соответствии с величиной  нулевая гипотеза. Данный тест применяется для больших выборок.
нулевая гипотеза. Данный тест применяется для больших выборок.
(%i1) load("stats")$
(%i2) test_mean([36,118,52,87,35,256,56,178,57,57,89,34,25,98,35,
98,41,45,198,54,79,63,35,45,44,75,42,75,45,45,
45,51,123,54,151],'asymptotic=true,'mean=50);![(\%o2)\
\begin{pmatrix}
MEAN\ TEST\cr
mean\_estimate=74.88571428571429\cr
conf\_level=0.95\cr
conf\_interval=[57.72848600856193,92.04294256286664]\cr
method=Large\ sample\ z-test.\ Unknown\ variance.\cr
hypotheses=H0:\ mean = 50 ,\ H1:\ mean\ \#\ 50\cr
statistic=2.842831192874313\cr
distribution=[normal,0,1]\cr
p\_value=.004471474652002261
\end{pmatrix}](/sites/default/files/tex_cache/3fa1e8048a14c43d1cd1bd3c705fe1a9.png)
Функция  позволяет проверить, принадлежат ли выборки
позволяет проверить, принадлежат ли выборки  и
и 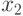 к одной генеральной совокупности.
к одной генеральной совокупности.
Синтаксис вызова:  или t
или t .
.
Данная функция выполняет t-тест для сравнения средних по выборкам и (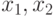 — списки или одномерные матрицы). Сравнение выборок может проводиться также на основании центральной предельной теоремы (для больших выборок). Опции функции такие же, как и для , кроме оценок среднеквадратичных отклонений выборок (если они известны) Список опций:
— списки или одномерные матрицы). Сравнение выборок может проводиться также на основании центральной предельной теоремы (для больших выборок). Опции функции такие же, как и для , кроме оценок среднеквадратичных отклонений выборок (если они известны) Список опций:
- 'alternative, по умолчанию 'twosided, вид проверяемой гипотезы (возможные значения 'twosided, 'greater и 'less);
-
'dev1, 'dev2, по умолчанию 'unknown, величины среднеквадратичных отклонений для выборок и , если они известны ('unknown или положительное выражение);
- 'conflevel, по умолчанию 95/100, уровень значимости для доверительного интервала (величина в пределах от 0 до 1);
-
'asymptotic, по умолчанию , указывает какой критерий использовать (-критерий или центральную предельную теорему).
Вывод результатов не отличается от вывода результатов .
Примеры использования : Для двух малых выборок проверяется гипотеза от равенстве средних против альтернативной гипотезы : различие математических ожиданий статистически значимо, т.е. выборки принадлежат к разным генеральным совокупностям.
(%i1) load("stats")$
(%i2) x: [20.4,62.5,61.3,44.2,11.1,23.7]$
(%i3) y: [1.2,6.9,38.7,20.4,17.2]$
(%i4) test_means_difference(x,y,'alternative='greater);![(\%o4)\
\begin{pmatrix}
DIFFERENCE\ OF\ MEANS\ TEST\cr
diff\_estimate=20.31999999999999\cr
conf\_level=0.95\cr
conf\_interval=[-.04597417812881588,\infty ]\cr
method=Exact\ t-test.\ Welch\ approx.\cr
hypotheses=H0:\ mean1 = mean2 ,\ H1:\ mean1 > mean2\cr
statistic=1.838004300728477\cr
distribution=[student\_t,8.62758740184604]\cr
p\_value=.05032746527991905
\end{pmatrix}](/sites/default/files/tex_cache/1ddf85f3f8ba18afd709decfad1570b9.png)
Оценка доверительного интервала для дисперсии выборки проводится при помощи функции  .
.
Синтаксис вызова:  или
или 
Данная функция использует тест 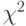 . Предполагается, что распределение выборки нормальное. Опции функции :
. Предполагается, что распределение выборки нормальное. Опции функции :
- 'mean, по умолчанию 'unknown, оценка математического ожидания (среднее по выборке), если оно известно;
- 'alternative, по умолчанию 'twosided, вид проверяемой гипотезы (возможные значения 'twosided, 'greater и 'less);
- 'variance, по умолчанию 1, это оценка дисперсии выборки для сравнения с фактической дисперсией;
- 'conflevel, по умолчанию 95/100, уровень значимости для доверительного интервала (величина в пределах от 0 до 1).
Основной результат, возвращаемый функцией — оценка дисперсии выборки  и доверительный интервал для неё.
и доверительный интервал для неё.
Пример: Проверка, отличается ли дисперсия выборки с неизвестным математическим ожиданием от значения 200.
(%i1) load("stats")$
(%i2) x: [203,229,215,220,223,233,208,228,209]$
(%i3) test_variance(x,'alternative='greater,'variance=200);![(\%o3)\
\begin{pmatrix}
VARIANCE\ TEST\cr
var\_estimate=110.75\cr
conf\_level=0.95\cr
conf\_interval=[57.13433376937479,\infty ]\cr
method=Variance\ Chi-square\ test.\ Unknown\ mean.\cr
hypotheses=H0:\ var\ =\ 200 ,\ H1:\ var\ >\ 200\cr
statistic=4.430000000000001\cr
distribution=[chi2,8]\cr
p\_value=.8163948512777688
\end{pmatrix}](/sites/default/files/tex_cache/d8af5b062af23603fffa66f4f232be4f.png)
Сравнение дисперсий двух выборок проводится при помощи функции (синтаксис вызова  или
или  .
.
Данная функция предназначена для сопоставления дисперсий двух выборок с нормальным распределением по критерию Фишера (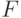 -тест). Аргументы и — списки или одномерные матрицы, содержащие независимые выборки.
-тест). Аргументы и — списки или одномерные матрицы, содержащие независимые выборки.
Опции функции  :
:
-
'mean1, 'mean2, по умолчанию 'unknown, оценки математических ожиданий выборок и , если они известны;
- 'alternative, по умолчанию 'twosided, вид проверяемой гипотезы (возможные значения 'twosided, 'greater и 'less);
- 'conflevel, по умолчанию 95/100, уровень значимости для доверительного интервала (величина в пределах от 0 до 1).
Основной результат, возвращаемый функцией — отношение дисперсий выборок  .
.
Пример: проверяется гипотеза о равенстве дисперсий двух выборок по сравнению с альтернативной гипотезой о том, что дисперсия первой больше, чем дисперсия второй.
(%i1) load("stats")$
(%i2) x: [20.4,62.5,61.3,44.2,11.1,23.7]$
(%i3) y: [1.2,6.9,38.7,20.4,17.2]$
(%i4) test_variance_ratio(x,y,'alternative='greater);![(\%o4)\
\begin{pmatrix}
VARIANCE\ RATIO\ TEST\cr
ratio\_estimate=2.316933391522034\cr
conf\_level=0.95\cr
conf\_interval=[.3703504689507263,\infty ]\cr
method=Variance\ ratio\ F-test.\ Unknown\ means.\cr
hypotheses=H0:\ var1\ =\ var2 ,\ H1:\ var1\ >\ var2\cr
statistic=2.316933391522034\cr
distribution=[f,5,4]\cr
p\_value=.2179269692254463
\end{pmatrix}](/sites/default/files/tex_cache/0d12cfffdfd3c92ca8c24327a0ba90aa.png)
При отсутствии представлений о распределении выборки может использоваться непараметрический тест для сравнения средних. Оценка медианы непрерывной выборки проводится при помощи функции  . Синтаксис вызова
. Синтаксис вызова  или
или  .
.
Функция допускает две опции:  (аналогично ) и
(аналогично ) и  (по умолчанию 0, или оценка значения медианы для проверки статистической значимости).
(по умолчанию 0, или оценка значения медианы для проверки статистической значимости).
Результаты, которые возвращает функция:
- 'med_estimate: медиана выборки;
- 'method: использованная процедура;
-
'hypotheses: проверяемые статистические гипотезы (нулевая и альтернативная );
- 'statistic: число степеней свободы для проверки нулевой гипотезы;
- 'distribution: оценка распределения распределения выборки;
-
'p_value: вероятность ошибочного выбора гипотезы , если выполняется .
Пример: проверка гипотезы о равенстве медианы выборки 6, против альтернативной гипотезы : медиана больше 6.
(%i1) load("stats")$
(%i2) x: [2,0.1,7,1.8,4,2.3,5.6,7.4,5.1,6.1,6]$
(%i3) test_sign(x,'median=6,'alternative='greater);![(\%o3)\
\begin{pmatrix}
SIGN\ TEST\cr
med\_estimate=5.1\cr
method=Non\ parametric\ sign\ test.\cr
hypotheses=H0:\ median\ =\ 6 ,\ H1:\ median\ >\ 6\cr
statistic=7\cr
distribution=[binomial,10,0.5]\cr
p\_value=.05468749999999989
\end{pmatrix}](/sites/default/files/tex_cache/e2d579d092abd0ef078eba31decc8773.png)
Аналогичная функция —  (либо с указанием опций
(либо с указанием опций  ), которая использует тест правила знаков Вилкоксона для оценки гипотезы о медиане непрерывной выборки. Опции и результаты функции
), которая использует тест правила знаков Вилкоксона для оценки гипотезы о медиане непрерывной выборки. Опции и результаты функции  такие же, как и для функции .
такие же, как и для функции .
Пример: проверка гипотезы : медиана равна 15 против альтернативной гипотезы : медиана больше 15.
(%i1) load("stats")$
(%i2) x: [17.1,15.9,13.7,13.4,15.5,17.6]$
(%i3) test_signed_rank(x,median=15,alternative=greater);![(\%o3)\
\begin{pmatrix}
SIGNED\ RANK\ TEST\cr
med\_estimate=15.7\cr
method=Exact test\cr
hypotheses=H0:\ med\ =\ 15 ,\ H1:\ med\ >\ 15\cr
statistic=14\cr
distribution=[signed\_rank,6]\cr
p\_value=0.28125
\end{pmatrix}](/sites/default/files/tex_cache/8080a637d982e1343287f1d697b6a105.png)
Непараметрическое сравнение медиан двух выборок реализовано в одной функции —  . В данной функции используется тест Вилкоксона-Манна-Уитни.
. В данной функции используется тест Вилкоксона-Манна-Уитни. 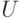 -критерий Манна-Уитни — непараметрический метод проверки гипотез, часто использующийся в качестве альтернативы -тесту Стьюдента. Обычно этот тест используется для сравнения медиан двух распределений и , не являющихся нормальными (отсутствие нормальности не позволяет применить - тест).
-критерий Манна-Уитни — непараметрический метод проверки гипотез, часто использующийся в качестве альтернативы -тесту Стьюдента. Обычно этот тест используется для сравнения медиан двух распределений и , не являющихся нормальными (отсутствие нормальности не позволяет применить - тест).
Синтаксис вызова:  или
или  .
.
Функция допускает лишь одну опцию: (аналогично ).
Результаты, которые возвращает функция:
- 'method: использованная процедура;
-
'hypotheses: проверяемые статистические гипотезы (нулевая и альтернативная );
- 'statistic: число степеней свободы для проверки нулевой гипотезы;
- 'distribution: оценка распределения распределения выборки;
-
'p_value: вероятность ошибочного выбора гипотезы , если выполняется .
Пример: проверка, одинаковы ли медианы выборок и .
(%i1) load("stats")$
(%i2) x:[12,15,17,38,42,10,23,35,28]$
(%i3) y:[21,18,25,14,52,65,40,43]$
(%i4) test_rank_sum(x,y);![(\%o4)\
\begin{pmatrix}
RANK\ SUM\ TEST\cr
method=Exact\ test\cr
hypotheses=H0:\ med1 = med2 ,\ H1:\ med1\ \#\ med2\cr
statistic=22\cr
distribution=[rank\_sum,9,8]\cr
p\_value=.1995886466474702
\end{pmatrix}](/sites/default/files/tex_cache/2034b1d1954c6083549acf7adb4aeae4.png)
Для выборок большего объёма распределение выборок приблизительно нормальное. Сравниваем гипотезы : медиана 1 = медиана 2 и : медиана 1 < медиана 2.
(%i1) load("stats")$
(%i2) x: [39,42,35,13,10,23,15,20,17,27]$
(%i3) y: [20,52,66,19,41,32,44,25,14,39,43,35,19,56,27,15]$
(%i4) test_rank_sum(x,y,'alternative='less);![(\%o4)\
\begin{pmatrix}
RANK\ SUM\ TEST\cr
method=Asymptotic\ test.\ Ties\cr
hypotheses=H0:\ med1 = med2 ,\ H1:\ med1\ <\ med2\cr
statistic=48.5\cr
distribution=[normal,79.5,18.95419580097078]\cr
p\_value=.05096985666598441
\end{pmatrix}](/sites/default/files/tex_cache/37166b62087d74c1ea088850fa25a0b7.png)
Проверка нормальности распределения осуществляется функцией  . В этой функции реализован тест Шапиро-Уилка. Выборка (список или одномерная матрица) должна быть размером не менее 2, но не более 5000 элементов (иначе выдаётся сообщение об ошибке). Функция возвращает два значения: statistic — величина
. В этой функции реализован тест Шапиро-Уилка. Выборка (список или одномерная матрица) должна быть размером не менее 2, но не более 5000 элементов (иначе выдаётся сообщение об ошибке). Функция возвращает два значения: statistic — величина 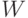 -статистики и величина вероятности (если больше принятого уровня значимости, нулевая гипотеза о нормальности распределения выборки не отвергается). Статистика характеризует близость выборочного распределения к нормальному (чем ближе к 1, тем меньше вероятность ошибочно принять гипотезу о нормальности распределения).
-статистики и величина вероятности (если больше принятого уровня значимости, нулевая гипотеза о нормальности распределения выборки не отвергается). Статистика характеризует близость выборочного распределения к нормальному (чем ближе к 1, тем меньше вероятность ошибочно принять гипотезу о нормальности распределения).
Пример: проверка гипотезы о нормальном распределения генеральной совокупности по заданной выборке.
(%i1) load("stats")$
(%i2) x:[12,15,17,38,42,10,23,35,28]$
(%i3) test_normality(x);