|
Добрый день!
Скажите, пожалуйста,планируется ли продолжение курсов по нанотехнологиям? Спасибо, Евгений
|
Опубликован: 01.10.2013 | Доступ: свободный | Студентов: 268 / 26 | Длительность: 24:58:00
ISBN: 978-5-9963-0223-9
Темы: САПР, Аппаратное обеспечение, Нанотехнологии
Специальности: Разработчик аппаратуры
Лекция 6:
Термальный синтез микропрограмм алгоритмически ориентированных МКМД-бит-потоковых субпроцессоров
Все поток-инструкции 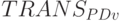 с PD -ассоциативными слов-инструкциями
с PD -ассоциативными слов-инструкциями  по определению используются однократно.
Поэтому в них оказываются эффективными порты вывода типа
по определению используются однократно.
Поэтому в них оказываются эффективными порты вывода типа  (см. рис. 5.5), на которые расходуется минимальный объем оборудования.
(см. рис. 5.5), на которые расходуется минимальный объем оборудования.
В поток-инструкциях 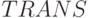 синтезированных в порядке "чтения" (рис. 5.12-а), каждая
синтезированных в порядке "чтения" (рис. 5.12-а), каждая  -я линейная цепочка содержит всего две слов-инструкции
-я линейная цепочка содержит всего две слов-инструкции 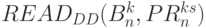 и
и 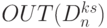 , которые работают по правилу:
, которые работают по правилу:
-
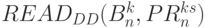 - выходы схем "И" 6-го столбца бит-процессоров (см. рис. 5.12-а):
- выходы схем "И" 6-го столбца бит-процессоров (см. рис. 5.12-а):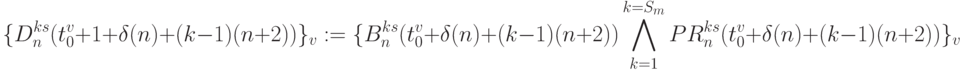
( 5.17) -
 - выход вертикального канала транзита бит-процессоров 6-го столбца рис. 5.11-а:
- выход вертикального канала транзита бит-процессоров 6-го столбца рис. 5.11-а:
( 5.18) где:
-
 - целочисленное время синтеза супрамолекулярных слов-инструкций
- целочисленное время синтеза супрамолекулярных слов-инструкций 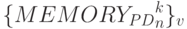 ;
; -
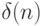 - время задержки, расходуемое на возбуждение каждой -й слов-инструкции
- время задержки, расходуемое на возбуждение каждой -й слов-инструкции  потоком циклических констант
потоком циклических констант  .
.
-
В поток-инструкциях , синтезированных в порядке "записи" (рис. 5.12-б), каждая -я линейная цепочка содержит 3 слов-инструкции: 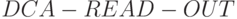 , первая из которых работает либо согласно (5.15), либо согласно (5.16).
, первая из которых работает либо согласно (5.15), либо согласно (5.16).
В первом случае (совокупность рисунков 5.9 и 5.12-б):
- для выполнения каждой
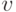 -й перестановки необходимо предварительно синтезировать специфическую, полностью PD -ассоциативную структуру, которая доопределяется потоком псевдослучайных адресов
-й перестановки необходимо предварительно синтезировать специфическую, полностью PD -ассоциативную структуру, которая доопределяется потоком псевдослучайных адресов  ;
; - слов-инструкции (выходы нечетных строк бит-процессоров 4-го столбца рис. 5.12-б) работают по правилу:

( 5.19) где:
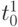 и
и  соответствуют (5.5), а
соответствуют (5.5), а 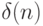 - это задержка на возбуждение
- это задержка на возбуждение 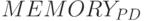 , которая зависит как от содержимого всех
, которая зависит как от содержимого всех  , так и от их разрядности
, так и от их разрядности  (в данном случае
(в данном случае 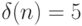 тактов);
тактов); - слов-инструкции (выход вертикального канала транзита бит-процессоров 4-го столбца рис. 5.12-б) работают по правилу:
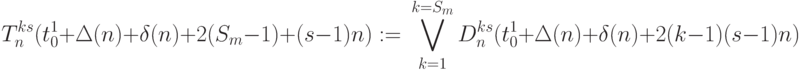
( 5.20)
Во втором случае (совокупность рисунков 5.10 и 5.12-б):
- неспецифическая, DD -ассоциативная структура
 доопределяется на каждом -м цикле как потоком псевдослучайных адресов
доопределяется на каждом -м цикле как потоком псевдослучайных адресов 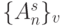 , так и специфической, PD -ассоциативной структурой
, так и специфической, PD -ассоциативной структурой  ;
; - слов-инструкции
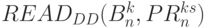 работают по правилу:
работают по правилу: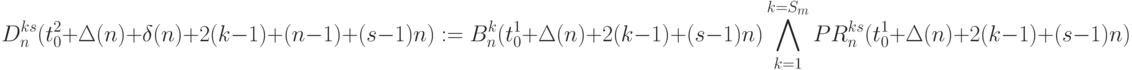
( 5.21) - слов-инструкции
 работают по правилу:
работают по правилу: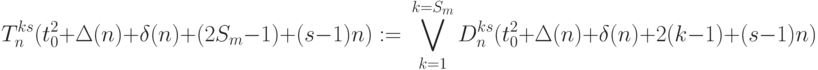
( 5.22)
Здесь ,  и соответствуют (5.16), где
и соответствуют (5.16), где 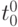 соответствует моменту окончания синтеза
соответствует моменту окончания синтеза  .
.
В зависимости от типа используемой PD -ассоциативной конструкции:
- Поток псевдослучайных адресов может использоваться:
- только на этапе синтеза, как это имеет место в
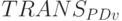 , синтези-руемой в порядке "чтения" (см. рис. 5.12-а), где этот поток управляет порядком размещения в пространстве (то есть по индексу
, синтези-руемой в порядке "чтения" (см. рис. 5.12-а), где этот поток управляет порядком размещения в пространстве (то есть по индексу 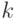 ) слов-инструкций
) слов-инструкций  ;
; - только на этапе использования, как это имеет место в
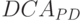 рис. 5.11-а,
где PD -ассоциативные слов-инструкции "хранят" натуральный ряд чисел
рис. 5.11-а,
где PD -ассоциативные слов-инструкции "хранят" натуральный ряд чисел  , и поэтому управляет только порядком срабатывания
, и поэтому управляет только порядком срабатывания 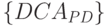 ;
; - и на этапе синтеза, и на этапе использования, как это имеет место в рисунков 5.12-а и 5.12-б, где поток управляет и поряд-ком размещения в пространстве слов-инструкций (то есть по индексу ), и порядком их возмущения во времени (то есть по индексу
 ).
).Очевидно, что в последнем случае требуются дополнительные аппаратные средства "хранения" или "регенерации" потока псевдослучай-ных адресов
, обеспечивающие их двукратное использование.
- только на этапе синтеза, как это имеет место в
- Синтез PD -ассоциативных поток-инструкций
 может осуществляться в пространстве либо фрагментарным, либо хронологическим наращиванием составляющих слов-инструкций. Первое типично для TRANS синтезируемой в порядке "чтения" (см. рис. 5.12-а), второе - для , синтезируемой в порядке "записи" (см. рис. 5.12-б).
может осуществляться в пространстве либо фрагментарным, либо хронологическим наращиванием составляющих слов-инструкций. Первое типично для TRANS синтезируемой в порядке "чтения" (см. рис. 5.12-а), второе - для , синтезируемой в порядке "записи" (см. рис. 5.12-б).Синтез составляющих слов-инструкций
по индексу  также можно осуществить как в линейном порядке, так и фрагментарно, например, одновременным включением в одну и ту же слов-инструкцию однотипных термов, занимающих в ней разное положение по
также можно осуществить как в линейном порядке, так и фрагментарно, например, одновременным включением в одну и ту же слов-инструкцию однотипных термов, занимающих в ней разное положение по  .
.Возможен и комбинированный синтез PD -ассоциативных поток-инструкций типа: "фрагментарный по
 - линейный по ", "фрагментарный по и " и.т. п.
- линейный по ", "фрагментарный по и " и.т. п.Поэтому линейный порядок возбуждения PD -ассоциативных слов-инструкций, используемых в режиме
 , фактически соответствует порядку их размещения в пространстве, а не порядку их синтеза.
, фактически соответствует порядку их размещения в пространстве, а не порядку их синтеза. - Цикл возбуждения всех рассмотренных
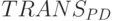 составляет
составляет 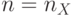 тактов, а фронт возбуждающей волны распространяется в пространстве линейно с задержкой на 2 такта в каждой -й линейной цепочке слов-инструкций. Поэтому отклик поток-инструкций рисунков 5.9, 5.11-а и поток-инструкций рис. 5.12-а составляет
тактов, а фронт возбуждающей волны распространяется в пространстве линейно с задержкой на 2 такта в каждой -й линейной цепочке слов-инструкций. Поэтому отклик поток-инструкций рисунков 5.9, 5.11-а и поток-инструкций рис. 5.12-а составляет  . Но в схеме рис. 5.12-а он носит линейный по характер, а в схеме рис. 5.12-б составляющие слов-инструкции возбуждаются уже фрагментарно.
. Но в схеме рис. 5.12-а он носит линейный по характер, а в схеме рис. 5.12-б составляющие слов-инструкции возбуждаются уже фрагментарно.
Системотехнические выводы по лекции 5
- Рекуррентные процедуры синтеза ассоциативных слов- и поток-инструкций определяются термальным составом, который в свою очередь зависит от процедуры декомпозиции реализуемого поток-оператора (см. рис. 5.1). В частности, один и тот же оператор подстановки
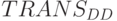 можно реализовать и на основе трех термов
можно реализовать и на основе трех термов 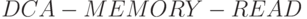 и на основе пяти термов
и на основе пяти термов  .
. - Рекуррентные процедуры синтеза ассоциативных слов- и поток-инструкций сводятся к наращиванию количества термов и/или их размеров в зависимости от разрядности и/или размерности преобразуемых потоков данных, что делает такой синтез сходным с процессом полимеризации сложных (био)молекулярных соединений.
- DD-ассоциативные конструкции по определению инвариантны содержимому потоков преобразуемых данных. Поэтому поиск их термального состава сводится:
- к выбору базовой топологии и настройке линейных цепочек составляющих слов-инструкций на разрядность обрабатываемых операндов
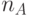 ,
, 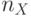 или ;
или ; - к рекуррентной по процедуре наращивания линейных цепочек слов-инструкций в до размера "скользящего окна" . При этом благодаря фиксированному составу используемых термов и известной разрядности преобразуемых операндов все фазовые сдвиги в слов-инструкциях оказываются вычисляемыми. В результате термальный синтез топологии DD-ассоциативных поток-операторов становится формализованным.
- к выбору базовой топологии и настройке линейных цепочек составляющих слов-инструкций на разрядность обрабатываемых операндов
- Из всех рассмотренных DD - и PD -ассоциативных конструкций минимальные аппаратные затраты требует поток-инструкция , синтезируемая в порядке "чтения", так как основная "сложность" преобразований реализуемой перестановки в этом случае ложится на этап синтеза PD -ассоциативных слов-инструкций
 . При этом следует учитывать, что топология PD -ассоциативных слов-инструкций по определению зависит от содержимого преобразуемых потоков данных. Но и в этом случае, ограничив состав используемых термов и введя в качестве ограничения фиксированное и зависящее от время задержки в каждой PD -ассоциативной конструкции, можно формализовать процедуру синтеза как отдельных слов-инструкций, так и их линейных цепочек.
. При этом следует учитывать, что топология PD -ассоциативных слов-инструкций по определению зависит от содержимого преобразуемых потоков данных. Но и в этом случае, ограничив состав используемых термов и введя в качестве ограничения фиксированное и зависящее от время задержки в каждой PD -ассоциативной конструкции, можно формализовать процедуру синтеза как отдельных слов-инструкций, так и их линейных цепочек. - Для перспективных супрамолекулярных вычислителей выбор между DD - и PD -ассоциативными конструкциями фактически сводится к выбору метода адаптации, который зависит от "времени жизни" гете-роструктуры:
- если "время жизни" велико, то предпочтение следует отдавать DD-ассоциативным конструкциям, конформационные преобразования которых позволяют настроить их на реализацию требуемой функции;
- если "время жизни" мало, то предпочтение следует отдавать PD-ассоциативным конструкциям, настройка которых на реализуемую функцию и содержимое одного из преобразуемых операндов требует структурной адаптации.
- Интерактивный характер выбора топологии термов, а с ней и топологии слов- и поток-инструкций предопределен линейными размерами матриц, априори выделяемых на их реализацию. При этом, как и в молекулярной биологии, следует отличать функционально значимые и промежуточные (вставочные) термы, первые из которых задают правила и циклы взаимодействия между слов-инструкциями, а вторые обеспечивают рекуррентное наращивание по какому-либо параметру однородной функции. Характерно также, что в "активных зонах" DD - и PD -ассоциативные конструкции взаимодействуют не только между собой, но и с потоками управляющих данных, которые задают циклы (по или ) такого взаимодействия.
- Технологические задержки в соотношениях (5.1)-(5.22) типа
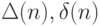 и т. п. носят неаналитический характер и существенно зависят от топологической схемы используемой ассоциативной конструкции. Поэтому достичь их априорного знания можно только задав ограничения на допустимый состав элементарных термов, а с ними по возрастающей на топологические схемы слов- и поток-инструкций. В этом и только в этом случае можно формализовать процедуры микропрограммного конструирования ассоциативных поток-процессоров. Последнее говорит о (полу)эмпирическом характере синтеза ассоциативных гетероструктур, что свойственно и реальным молекулярно-биологическим процессам.
и т. п. носят неаналитический характер и существенно зависят от топологической схемы используемой ассоциативной конструкции. Поэтому достичь их априорного знания можно только задав ограничения на допустимый состав элементарных термов, а с ними по возрастающей на топологические схемы слов- и поток-инструкций. В этом и только в этом случае можно формализовать процедуры микропрограммного конструирования ассоциативных поток-процессоров. Последнее говорит о (полу)эмпирическом характере синтеза ассоциативных гетероструктур, что свойственно и реальным молекулярно-биологическим процессам. - В МКМД-бит-потоковых матрицах "фронт вычислительной волны" распространяется по бит-матрице с помощью механизмов, сходных "пробоям" в реальных аксонно-коллатеральных связях, что наиболее четко проявляется в интерфейсах рис. 5.12-а. Это указывает на то, что в реальных нейросетях преобразование информации может осуществляться не только в соме нейрона, но и в процессе распространения возбуждения по аксонно-коллатеральным связям, реализующим функции алгоритмически ориентированных PD -ассоциативных субпроцессоров.
Евгений Акимов