



 46,7<50%
46,7<50%|
Добрый день!
Скажите, пожалуйста,планируется ли продолжение курсов по нанотехнологиям? Спасибо, Евгений
|
Опубликован: 01.10.2013 | Доступ: свободный | Студентов: 268 / 26 | Длительность: 24:58:00
ISBN: 978-5-9963-0223-9
Темы: САПР, Аппаратное обеспечение, Нанотехнологии
Специальности: Разработчик аппаратуры
Лекция 5:
МКМД-БИТ-потоковые субпроцессоры с (микро)программируемой архитектурой
Аннотация: В лекции раскрыты особенности микропрограммного конструирования МКМД-бит-потоковых субпроцессоров или, что одно и то же, особенности перехода с микрокомандного на ассемблерный уровень
организации вычислений в (Б)ВС с микрокомандным уровнем доступа.
Ключевые слова: бит, поток, инструкция, время задержки, фиксированная запятая, мантисса, неравенство, операнд, индекс, пользователь, разрядность, прямой, константы, формализуемая задача, топология связи, знаковый бит, DCC, класс, процессор, шина, цикл работы, ОЗУ данных, реконфигурация, шина управления, обмен данными, FIFO, многопроцессорная конфигурация, гиперкуб, устойчивость к отказам, центральный процессор, пропускная способность, ядро, скалярное произведение, свертка, функциональная схема, умножение, множитель, цикла, затраты, регистровая память, регистр, размерность, алгоритм, терм, программирование, ложная тревога, ОКМД, класс решаемых, доступ, ОЗУ, ВС, память, АЛУ, ячейка, матрица, триггер, избыточность, логический уровень, логический вентиль, противоречивость требований, погрешности вычислений, ресурс, работ, операторы, потоки данных, распараллеливание вычислений, производительность, скользящее окно, значение, композиция, вычисление, операции, диапазон, дополнительный код, инверсия
4.1. Ассоциативные конструкции на уровне слов-инструкций
В МКМД-бит-потоковых вычислительных технологиях переход с микропрограммного на ассемблерный уровень организации вычислений осуществляется методами и средствами "восходящего" микропрограммного конструирования, которому всегда предшествует фаза "нисходящей" декомпозиции поток-оператора пользователя в граф-поток реализующих его слов-инструкций (см. раздел 6.1 курса "Задачи и модели вычислительных наноструктур").
Главная специфика микропрограммного конструирования:
- В фазе декомпозиции, с одной стороны, снимаются какие-либо языковые ограничения на состав слов-инструкций и на их параметры, а с другой стороны, ужесточаются требования к микропрограммным алгоритмам их реализации, которые должны:
- быть представлены в последовательной конвейерной форме, и все циклы должны завершаться "по счетчику", а не "по условию";
- иметь явное описание управляющих процедур, с помощью которых задаются параметры преобразуемых операндов и потоков.
- В фазе конструирования наиболее общими являются бит-инструкции, которые определены над "бесконечными" потоками данных, и поэтому их включение в состав слов-потоковых требует как минимум явного задания ограничений на разрядность и формат операндов, а также вытекающих из них параметров циклической обработки "бесконечных" бит-потоков данных.
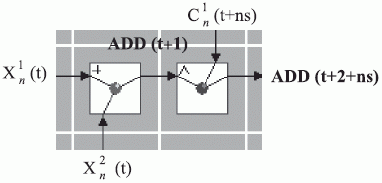
В частности, бит-потоковая инструкция  отличается от слов-потоковой
отличается от слов-потоковой  тем, что в ней циклически обнуляется старший (буферный) разряд каждого операнда-приемника (рис. 4.1 - в условных обозначениях
табл. 4.1):
тем, что в ней циклически обнуляется старший (буферный) разряд каждого операнда-приемника (рис. 4.1 - в условных обозначениях
табл. 4.1):
![ADD(t+2+n*s) = AND[ADD(t+l), \overline{C^l_n(t + n*s) }],](/sites/default/files/tex_cache/f4bac464a4626d603eb65a9ac04d0a92.png) |
( 4.1) |
где:
-
 - определенная в (3.1) потоковая бит-инструкция "непрерывного" сложения двух "бесконечных" бит-потоков операндов-источников;
- определенная в (3.1) потоковая бит-инструкция "непрерывного" сложения двух "бесконечных" бит-потоков операндов-источников; -
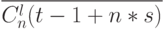 - DD -ассоциативная "маскирующая" переменная, полученная инверсией (IC) циклической константы
- DD -ассоциативная "маскирующая" переменная, полученная инверсией (IC) циклической константы 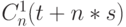 вида: младший бит - "1", а
вида: младший бит - "1", а  старших бит - "0";
старших бит - "0"; -
 - "алгоритмический" фазовый сдвиг
- "алгоритмический" фазовый сдвиг  -го слов-операнда, заданного в последовательном коде, причем на уровне слов-инструкций целочисленный индекс изменяется от
-го слов-операнда, заданного в последовательном коде, причем на уровне слов-инструкций целочисленный индекс изменяется от  до
до  и доопределяется до конечной величины
и доопределяется до конечной величины 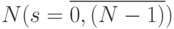 только в поток-операторе.
только в поток-операторе.
Алгоритмическим сдвигом будем считать целочисленное время задержки, определяемое граф-потоком, реализуемым на уровне слов- или поток-инструкции. Технологический сдвиг определяется топологией размещения бит-инструкций на бит-матрице, в нашем случае он минимален и составляет 2 такта задержки, расходуемых на прохождение потоков бит-данных через 2 последовательно соединенных бит-процессора.
Здесь и далее принят традиционный для конвейерной арифметики формат данных фиксированной запятой: старший  -й бит - "буферный" разряд,
-й бит - "буферный" разряд, 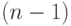 -й бит - знаковый разряд
-й бит - знаковый разряд  и
и 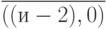 -е биты - мантисса, причем операнды подаются на входы операционных устройств младшим разрядом вперед, а "буферный" разряд препятствует распространению по потоку "паразитной" "единицы переноса" и поэтому принудительно обнуляется после каждого алгебраического сложения.
-е биты - мантисса, причем операнды подаются на входы операционных устройств младшим разрядом вперед, а "буферный" разряд препятствует распространению по потоку "паразитной" "единицы переноса" и поэтому принудительно обнуляется после каждого алгебраического сложения.
Из (4.1) и рис. 4.1 видно, что в МКМД-бит-потоковых вычислительных технологиях:
- основное назначение ассоциативных конструкций - это сверхоперативное управление взаимодействием пространственно-временных и изначально "бесконечных" бит-потоков данных с пространственно фиксированным на бит-матрице потоком бит-инструкций;
- включение потоковых слов-инструкций в состав поток-операторов, так же как и включение бит-потоковых инструкций в состав слов-потоковых, требует явного задания циклов обработки, зависящих как минимум от
 и ;
и ;Таблица 4.1. Условное графическое изображение бит-инструкций Ус ловное изображение Комментарий В канале АЛУ бит-процессора выполняется операция 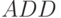 над операндами, поступающими на первом такте слева и снизу. Результирующий операнд выдается на 3 такте вправо. В канале транзита входной операнд поступает снизу на 1 такте и подается с задержкой на один такт вверх, а с задержкой на 3 такта - вниз
над операндами, поступающими на первом такте слева и снизу. Результирующий операнд выдается на 3 такте вправо. В канале транзита входной операнд поступает снизу на 1 такте и подается с задержкой на один такт вверх, а с задержкой на 3 такта - внизВ канале АЛУ бит-процессора выполняется операция над операндами, поступающими на первом такте слева и снизу. Результирующий операнд выдается на 3 такте вправо. В канале транзита входной операнд поступает снизу на 1 такте и подается с задержкой на один такт вверх, а с задержкой на 3 такта - внизВ канале АЛУ выполняется операция "запоминание единицей", в которой информационный операнд подается на 0 такте слева, а управляющий операнд - на 2 такте справа и, если он имеет вид циклической константы 00…01, то на выходе с дополнительной задержкой на 2 такта по отношению к управляющему входу запоминается содержимое ( 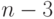 )-го бита информационного операнда. Канал транзита не используется
)-го бита информационного операнда. Канал транзита не используетсяВ каналах АЛУ и транзита выполняется слияние потоков по "ИЛИ" по правилу: 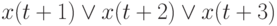 , где
, где 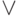 - операция "ИЛИ", а результирующий операнд поступает на правый выход бит-процессора с задержкой на 1, 2 и 3 такта
- операция "ИЛИ", а результирующий операнд поступает на правый выход бит-процессора с задержкой на 1, 2 и 3 тактаВ канале АЛУ реализуется операция  , то есть он не используется, а в канале транзита входной операнд поступает слева и передается вправо с дополнительной задержкой на 2 такта, а вниз - с дополнительной задержкой на 1 такт
, то есть он не используется, а в канале транзита входной операнд поступает слева и передается вправо с дополнительной задержкой на 2 такта, а вниз - с дополнительной задержкой на 1 такт - как и в нанометровых или супрамолекулярных вычислителях, управление в реальном времени сводится к блокаде "паразитных" взаимодействий, в данном случае - по циклически обрабатываемым операндам и потокам данных.
На уровне слов-инструкций, как правило, используется смесь PD -или DD -ассоциативных конструкций бит-процессорного уровня, что обусловлено природой МКМД-бит-потоковой организации вычислений, где неделимой единицей инициализации и обработки являются не отдельные слов-инструкции и операнды, а соответственно пространственно фиксированные потоки бит-инструкций и преобразуемые ими пространственно-временные потоки бит-данных (см. системообразующее неравенство (6.1) раздела 6.5 курса "Задачи и модели вычислительных наноструктур").
Типичным представителем комплексного использования различных ассоциативных конструкций бит-процессорного уровня является потоковая слов-инструкция  , циклически преобразующая потоковый операнд-источник
, циклически преобразующая потоковый операнд-источник 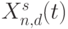 , заданный в прямом коде ( DC ), в соответствующий ему потоковый операнд-приемник
, заданный в прямом коде ( DC ), в соответствующий ему потоковый операнд-приемник 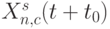 , заданный в дополнительном коде ( CC ).
, заданный в дополнительном коде ( CC ).
Потоковая слов-инструкция DCC выполняет PD -ассоциативное преобразование:
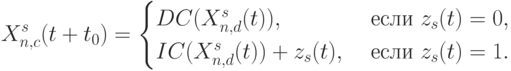 |
( 4.2) |
но над "непрерывным" потоком бит-данных, и делает это циклически по с фиксированной задержкой 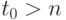 . Здесь
. Здесь 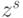 - знаковый разряд -го опе-ранда потока, причем целочисленный индекс
- знаковый разряд -го опе-ранда потока, причем целочисленный индекс 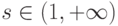 .
.
Реализующие эту слов-инструкцию циклические по МКМД-бит-потоковые процедуры имеют вид:
Шаг 1.1. Выделить и запомнить на тактов содержимое знакового разряда операнда-источника:
![Z^s_{n} [t_{1}+2 + n*(s +1)] := ST1[X^{s}_{n,d} (t_{l}+2 + n*s),C^{1}_n(t_{l}+n*(s +1))].](/sites/default/files/tex_cache/09c01c2a4127fe2daacf94c57f09b62b.png) |
( s +1))]) |
Шаг 1.2. Инвертировать (  ) циклическую константу
) циклическую константу 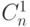 , с помощью которой пользователь (суб)процессора задает требуемую и, в общем случае, некратную 2 разрядность слов-операндов:
, с помощью которой пользователь (суб)процессора задает требуемую и, в общем случае, некратную 2 разрядность слов-операндов:
![IC[C^1_n(t_0+1+n*(s+1)]:=\overline{C^1_n(t_0+n*s)}](/sites/default/files/tex_cache/a7071c17e40a351fd1a5baabe3300fe7.png)
Шаг 2.1. "Обнулить" старший разряд -битного знакового вектора 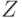 :
:
![Z_{n-1}^s[t_2+2+n*(s+1)]:=Z_{n}^{s}[t_2+1+n*s)]\land\overline{C^1_n(t_2+n*s)}](/sites/default/files/tex_cache/c087ccb021b42680abb44f028aea67f9.png)
Шаг 2.2. "Обнулить" знаковый разряд операнда-источника:
![X_{n,d}^{\sim s}[t_3+3+n*s)]:=X_{n,d}^{s}[t_3+2+n*s)]\land\overline{C^1_n(t_3+n*s)}](/sites/default/files/tex_cache/59e4aed17db31db1be7e930203442bff.png)
Шаг 2 3. Восстановить прямой код циклической константы :
![DC[C^1_n(t_4+1+n*s)]:=IC[\overline{C^1_n(t_4+n*s)}]](/sites/default/files/tex_cache/b1eb2b2a583dcb82a7248f2650e7ec65.png)
Шаг 3.1. Выполнить "условную инверсию" ( 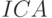 ) над модифицированным операндом-источником:
) над модифицированным операндом-источником:
![ICA[X_{n,d}^{s}(t_5+1+n*s))]:=X_{n,d}^{\sim s}[t_5+n*(s+1)]\oplus Z_{n-1}^{s}[t_5+n*(s+1)]](/sites/default/files/tex_cache/1c3531ab9d3200a9526a36bbfd3ebad7.png)
Шаг 3.2. Восстановить содержимое знакового разряда операнда-источника:
![z^s[t_6+1+n*(s+1)]:=Z_{n-1}^s[t_6+n(s+1)]\land C^1_n[t_6+n*(s+1)]](/sites/default/files/tex_cache/4e1b804574aed761919ee7720845c2c1.png)
Шаг 4.1. Сложить содержимое знакового разряда с "условной инверсией" операнда-источника:
![CC^{\sim}[X^{s}_{n,c}(t_{7}+l + n(s + l))] := z^{s}[t_{7}+n*(s + l)] + ICA[X^{s}_{n,d}(t_{7}+n*(s + l))]](/sites/default/files/tex_cache/901c2febf9f562e34f2d11526899cd70.png)
Шаг 4.2. Инвертировать содержимое знакового разряда операнда-источника:
![IC[z^{s} (t_{8} +1 + n * (s +1))] := \overline{z^{s}[t_{8} + n * (s +1)]}.](/sites/default/files/tex_cache/a7c765ed32485ad6b6594f9d8e7efc1b.png)
Шаг 5.1. "Обнулить" содержимое буферного разряда операнда-приемника:
![CC[X^{s}_{n,c}(t_{9} + 2 + n * (s +1)] := CC^{\sim}[X^{s}_{n,c}(t_{9} +1 + n * (s + l))]\land\overline{z^{s}[t_{9} + n * (s +1)]}.](/sites/default/files/tex_cache/23bb4494fc99950842957081ee880f6c.png)
Здесь 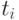 - целочисленное время начала исполнения соответствующей МКМД-бит-потоковой процедуры.
- целочисленное время начала исполнения соответствующей МКМД-бит-потоковой процедуры.
С позиций перспективной нано- и супрамолекулярной вычислительной техники из приведенных данных следует:
- В отличие от фон-неймановских ЭВМ, где под одним управляющим оператором, задающим параметры потоков данных (в данном случае это разрядность слов-операндов), по максимуму объединяются все слов-инструкции (под)программы, потоковые слов-инструкции являются вырожденными поток-операторами, в каждом из которых "глубина" информационного взаимодействия потоков данных принудительно ограничена задаваемой извне разрядностью операндов, а требования "непрерывной" обработки бит-потоков учтены фазовыми сдвигами типа или
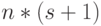 . Сами фазовые сдвиги поддерживаются и строго контролируются локальными управляющими DD - и PD -ассоциативными конструкциями как внутри, так и между слов-инструкциями, входящими в поток-оператор, реализуемый проблемно-ориентированным МКМД-бит-потоковым (суб)процессором. Поэтому ассоциативные управляющие конструкции в таких вычислительных технологиях распределены по всем потоковым слов-инструкциям , представлены в явном виде в структуре их микропрограмм и существенно избыточны по сравнению с классическими фон-неймановскими технологиями, что видно из сравнения (4.2) и процедур "1.1"-"5.1".
. Сами фазовые сдвиги поддерживаются и строго контролируются локальными управляющими DD - и PD -ассоциативными конструкциями как внутри, так и между слов-инструкциями, входящими в поток-оператор, реализуемый проблемно-ориентированным МКМД-бит-потоковым (суб)процессором. Поэтому ассоциативные управляющие конструкции в таких вычислительных технологиях распределены по всем потоковым слов-инструкциям , представлены в явном виде в структуре их микропрограмм и существенно избыточны по сравнению с классическими фон-неймановскими технологиями, что видно из сравнения (4.2) и процедур "1.1"-"5.1". - Главная особенность потоковой обработки данных связана с необходимостью многократного использования однажды введенных в бит-матрицу или сформированных в ней данных, что с системотехнических позиций призвано снизить интенсивность обмена данными МКМД-бит-потокового (суб)процессора с внешней памятью. В результате приходится многократно восстанавливать управляющие циклические константы, что приводит к росту аппаратно-временных затрат на управление операционными модулями, в каждом из которых в явном виде задается разрядность преобразуемых операндов и/или цикл суммирования. Поэтому МКМД-бит-потоковые (суб)процессо-ры работают не в режиме трансляции поток-операторов пользователя, а в режиме интерпретации их микропрограммных модулей, каждый из которых содержит один или несколько блоков управления.
-
PD -ассоциативная конструкция шага "1.1" формирует циклически по ( ) -битный вектор знака
 , который управляет такой же конструкцией в " условной инверсии " (бит-инструкция
, который управляет такой же конструкцией в " условной инверсии " (бит-инструкция  ) шага "3.1", заменяющей оператор условного перехода в (4.2). В результате образуются линейные цепочки PD -ассоциативных преобразований, которые в нанометровых и супрамолекулярных вычислителях можно реализовать в совмещенном (во времени и пространстве) с вычислениями синтезе "рабочего тела" за счет высокодинамичных операций замещения (подстановки), управляемых в данном случае:
) шага "3.1", заменяющей оператор условного перехода в (4.2). В результате образуются линейные цепочки PD -ассоциативных преобразований, которые в нанометровых и супрамолекулярных вычислителях можно реализовать в совмещенном (во времени и пространстве) с вычислениями синтезе "рабочего тела" за счет высокодинамичных операций замещения (подстановки), управляемых в данном случае:- в процедуре "1.1" - циклической константой
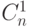 , которая выделяет (стробирует, селектирует), а затем фиксирует на тактов выход бит-процессора (квантового субстрата), который отвечает за потоковое "хранение" содержимому знакового разряда операнда-источника;
, которая выделяет (стробирует, селектирует), а затем фиксирует на тактов выход бит-процессора (квантового субстрата), который отвечает за потоковое "хранение" содержимому знакового разряда операнда-источника; - в процедуре "3.1" - знаковым вектором
 , который в соответствии со своим содержимым выделяет и фиксирует на тактов квантовый субстрат, обеспечивающий прохождение (отражение) операнда-источника либо прямым транзитом, либо транзитом с инверсией.
, который в соответствии со своим содержимым выделяет и фиксирует на тактов квантовый субстрат, обеспечивающий прохождение (отражение) операнда-источника либо прямым транзитом, либо транзитом с инверсией.
- в процедуре "1.1" - циклической константой
-
DD -ассоциативные конструкции процедур "2.1", "2.2", "3.2" и "5.1" являются "маскирующими" и поддерживают предельный темп потоковой обработки в процедурах "3.1" и "4.1", который отвечает условию:
 , где
, где  - период дискретизации потоков входных данных по Котельникову (см. раздел 1.5 курса "Задачи и модели вычислительных наноструктур").
- период дискретизации потоков входных данных по Котельникову (см. раздел 1.5 курса "Задачи и модели вычислительных наноструктур").Если эти DD -ассоциативные конструкции привести к PD -ассоциа-тивному виду (см. соотношение (8.12) раздела 8.4 курса "Задачи и модели вычислительных наноструктур"), то и отвечающие им вычислительные процедуры можно совместить во времени и пространстве с синтезом или регенерацией квантового "рабочего тела" нанометровых или супрамолекулярных вычислителей.
- Переход от бит-потоковых к слов-потоковым инструкциям представляет собой не столько (микро)программирование, сколько (микро) программное конструирование, где на используемые бит-потоковые инструкции накладываются ограничения циклической обработки, а пространственно-временное согласование всех составляющих бит-потоковых процедур представляет собой плохо формализуемую задачу поиска оптимальной топологической схемы размещения бит-инструкций на бит-матрице, отвечающей как минимуму "технологической" (неалгоритмической) задержки, так и минимуму расходуемой "площади" бит-матрицы.
В идеале это предполагает поиск такой топологии связей между бит-инструкциями, в которой:
- время "технологической" задержки между любыми попарно связанными процедурами из "1.1"-"5.1" равно 1 такту, то есть
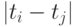 выполняется для всех информационно связанных пар
выполняется для всех информационно связанных пар 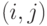 бит-инструкций;
бит-инструкций; - допустимое время задержки (
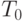 ) в (суб)процессоре максимально расходуется на "усложнение" реализуемого поток-оператора, что, хотя бы и косвенно, можно оценить:
) в (суб)процессоре максимально расходуется на "усложнение" реализуемого поток-оператора, что, хотя бы и косвенно, можно оценить: 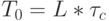 , где
, где 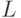 - критический путь в микропрограмме поток-оператора, исчисляемый количеством тактов, затраченных на прохождение данных от самого "раннего" входа до самого "позднего" выхода.
- критический путь в микропрограмме поток-оператора, исчисляемый количеством тактов, затраченных на прохождение данных от самого "раннего" входа до самого "позднего" выхода.
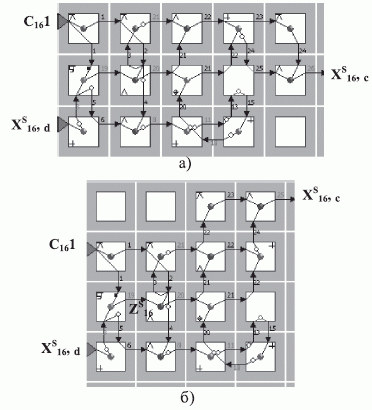
Для иллюстрации сказанного на рис. 4.2 (в условных обозначениях табл. 4.1) приведены две топологические схемы потоковой слов-инструкции DCC для
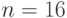 бит. Из этого рисунка видно, что в схеме а расходуется 3x5 бит-процессоров c временем задержки 26 тактов, а в схеме б соответственно 4x4 бит-процессора и 25 тактов, из которых только 14 являются алгоритмическими, так как компенсируют объективную для последовательной арифметики задержку между "нулевым" и знаковым битами операнда.
бит. Из этого рисунка видно, что в схеме а расходуется 3x5 бит-процессоров c временем задержки 26 тактов, а в схеме б соответственно 4x4 бит-процессора и 25 тактов, из которых только 14 являются алгоритмическими, так как компенсируют объективную для последовательной арифметики задержку между "нулевым" и знаковым битами операнда.В потоковой слов-инструкции DCC коэффициент использования структурно-функциональных возможностей заранее изготовленной бит-матрицы не превышает 50 % (см. рис. 4.2-а и табл. 4.2), причем ее коммутационные возможности использованы на 58 %, а операционные - на 38,3 %. Подобное соотношение между используемыми и предоставляе мыми в СБИС Н1841 ВФ1 структурно-функциональными возможностями достаточно типично для известных потоковых слов-инструкций.
Из сравнения (4.2) и процедур "1.1"-"5.1" видно, что только 3 бит-процессора принимают непосредственное участие в преобразовании
"прямой код - дополнительный", и реализуют они процедуры "1.1", "3.1" и "4.1", из которых только первые две являются PD -ассоциативными. Отсюда можно заключить, что в МКМД-бит-потоковых вычислительных технологиях аппаратно-временные затраты на DD - и PD -ассоциативное управление потоками данных в темпе реального времени, а вместе с ними и всем вычислительным процессом превосходят не менее чем в 2-5 раз затраты на функционально значимые для пользователя преобразования, часть из которых также представима в ассоциативном виде.
Таким образом, в нанометровых и супрамолекулярных вычислителях переход к PD -ассоциативным конструкциям открывает качественно новые возможности в организации вычислительного процесса, где часть формально-логических преобразований можно заложить в процесс синтеза или регенерации квантового "рабочего тела".
Поэтому в таких условиях эффективность работы нанометровых и супрамолекулярных вычислителей придется оценивать энергетическими и временными затратами не только на собственно преобразования потоков данных, но и на деструкцию вычислителя-предка и на синтез вычислителя-потомка с учетом ограничений на обмен зарядами и/или энергией с "внешней" (буферной) средой. При этом деструкция вычислителя-предка и синтез вычислителя-потомка могут быть как планомерными (при переходе от одного поток-оператора пользователя к другому), так и вынужденными (при регенерации вычислителя-предка), и осуществляться они должны в темпе реального времени.
- время "технологической" задержки между любыми попарно связанными процедурами из "1.1"-"5.1" равно 1 такту, то есть
Евгений Акимов