
|
Добрый день!
Скажите, пожалуйста,планируется ли продолжение курсов по нанотехнологиям? Спасибо, Евгений
|
Опубликован: 01.10.2013 | Доступ: свободный | Студентов: 267 / 26 | Длительность: 24:58:00
ISBN: 978-5-9963-0223-9
Темы: САПР, Аппаратное обеспечение, Нанотехнологии
Специальности: Разработчик аппаратуры
Лекция 5:
МКМД-БИТ-потоковые субпроцессоры с (микро)программируемой архитектурой
4.3. Ассоциативные конструкции в базовой системе команд МКМД-бит-потокового (суб)процессора векторно-матричной обработки
В современных задачах цифровой обработки сигналов и изображений темпа реального времени [70] доминируют векторно-матричные преобразования, операционное ядро которых образует скалярное произведение (свертка)

двух векторов 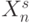 и
и 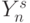 размерности
размерности  и разрядности
и разрядности  . В результате упрощенная функциональная схема операционного устройства цифровых процессоров обработки сигналов принимает вид
рис. 4.6, где все блоки реализованы аппаратно.
. В результате упрощенная функциональная схема операционного устройства цифровых процессоров обработки сигналов принимает вид
рис. 4.6, где все блоки реализованы аппаратно.
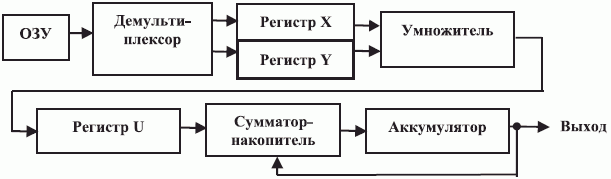
Рис. 4.6. Упрощенная функциональная схема операционного устройства цифровых процессоров обработки сигналов
В векторно-конвейерной арифметике умножение можно выполнить в прямом коде над абсолютными значениями входных векторов  с последующим присвоением знака
с последующим присвоением знака  результату
результату  , где все операнды имеют традиционный для МКМД-бит-потоковой организации вычислений формат фиксированной запятой с "нулевым" старшим разрядом и следующим за ним знаковым разрядом. В этом случае:
, где все операнды имеют традиционный для МКМД-бит-потоковой организации вычислений формат фиксированной запятой с "нулевым" старшим разрядом и следующим за ним знаковым разрядом. В этом случае:
 |
( 4.3) |
где  ,
,  i,j = \overline{1,n-2} - содержимое бит (
i,j = \overline{1,n-2} - содержимое бит (  )-разрядных модулей множимого
)-разрядных модулей множимого  и множителя
и множителя 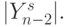
Отвечающая (4.3) схема МКМД-бит-потокового (по  конвейерного умножителя (рис. 4.7) работает в соответствии с ассоциативным алгоритмом: для всех
конвейерного умножителя (рис. 4.7) работает в соответствии с ассоциативным алгоритмом: для всех 
 |
( 4.4) |
где  ,
а множитель
,
а множитель  реализуется пошаговым наращиванием временного сдвига на
реализуется пошаговым наращиванием временного сдвига на  тактов по отношению к накапливаемой сумме частных произведений.
тактов по отношению к накапливаемой сумме частных произведений.
Здесь:  , а
, а  - целочисленное время начальной задержки поступления потоков и
- целочисленное время начальной задержки поступления потоков и  на входы умножителя.
на входы умножителя.
Отвечающая (4.4) топологическая схема DD -ассоциативного МКМД-бит-потокового умножителя приведена на рис. 4.7, и в ней:
-
 -й цикл работы продолжительностью
-й цикл работы продолжительностью 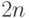 тактов задается циклической константой
тактов задается циклической константой  вида: первый справа (младший) бит - "единица", а остальные
вида: первый справа (младший) бит - "единица", а остальные  бита - "нули", которая распространяется по каналам транзита первой строки бит-процессоров с задержкой на 2 такта в каждом и передается вниз с задержкой на 1 такт в каждом столбце бит-матрицы;
бита - "нули", которая распространяется по каналам транзита первой строки бит-процессоров с задержкой на 2 такта в каждом и передается вниз с задержкой на 1 такт в каждом столбце бит-матрицы; - поток множителей
 (в каждом из которых
(в каждом из которых 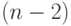 младших бита - значащие, а остальные - "нули") распространяется по каналам транзита бит-процессоров 2-й строки (с задержкой на 1 такт в каждом);
младших бита - значащие, а остальные - "нули") распространяется по каналам транзита бит-процессоров 2-й строки (с задержкой на 1 такт в каждом); - содержимое
 -го бита
-го бита  запоминается циклически (по ) на тактов и с выхода бит-инструкции ST1 передается вниз с задержкой на 2 такта (см.
табл. 5.8 курса "Задачи и модели вычислительных наноструктур") в соответствующем -м столбце бит-матрицы;
запоминается циклически (по ) на тактов и с выхода бит-инструкции ST1 передается вниз с задержкой на 2 такта (см.
табл. 5.8 курса "Задачи и модели вычислительных наноструктур") в соответствующем -м столбце бит-матрицы;
- поток множимых ?
 формата: (
формата: (  ) бит - значащие, а остальные - "нули", распространяется по каналам транзита бит-процессоров 3-й строки с задержкой на 2 такта в каждом и через бит-инструкцию
) бит - значащие, а остальные - "нули", распространяется по каналам транзита бит-процессоров 3-й строки с задержкой на 2 такта в каждом и через бит-инструкцию 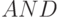 ответвляется вниз в каждом столбце бит-матрицы;
ответвляется вниз в каждом столбце бит-матрицы; - операция "сдвиг - сложение" -го множимого с самим собой (в зависимости от содержимого -го бита соответствующего -го множителя) реализуется в бит-процессорах 4-й строки бит-матрицы, причем операция сдвига на 1 разряд в каждом столбце осуществляется за счет дополнительной задержки множимого на 1 такт по отношению к моменту поступления соответствующей суммы частных произведений.
В этой схеме время начальной задержки равно ( ) цикла изменения индекса  , а аппаратные затраты на FIFO -регистровую память зависят от линейно: 1-я строка -
, а аппаратные затраты на FIFO -регистровую память зависят от линейно: 1-я строка -  бит, 2-я строка -
бит, 2-я строка -  бит, 3-я строка -
бит, 3-я строка - 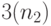 бит, 4-я строка - бит, что в сумме дает
бит, 4-я строка - бит, что в сумме дает  бит.
бит.
Однако скорость приращения индекса равна циклам изменения индекса .
Из приведенных алгоритмов и схем видно, что содержимое бит множителя определяет структуру "сдвигов-сложений", что является необходимой предпосылкой эффективного использования PD -ассоциативных конструкций при построении операционных устройств самого разнообразного функционального назначения.
В схеме конвейерного умножителя рис. 4.7:
- регистр
 является виртуальным и соответствует времени задержки -го бита, множимого на соответствующем входе (первый бит-процессор 3-й строки бит-матрицы);
является виртуальным и соответствует времени задержки -го бита, множимого на соответствующем входе (первый бит-процессор 3-й строки бит-матрицы); - регистр
 формируется бит-процессорами 2-й строки бит-матрицы (выходы бит-операций ST1);
формируется бит-процессорами 2-й строки бит-матрицы (выходы бит-операций ST1); - регистр
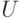 также является виртуальным и соответствует времени задержки -го бита произведения на выходе последнего бит-процессора 4-й строки бит-матрицы.
также является виртуальным и соответствует времени задержки -го бита произведения на выходе последнего бит-процессора 4-й строки бит-матрицы.
Входящий в состав операционного устройства рис. 4.6 МКМД-бит-потоковый DD -ассоциативный сумматор-накопитель реализуется совместно с аккумулятором (рис. 4.8), и в нем:
- входной операнд
 имеет разрядность
имеет разрядность  бит, а размерность результирующей матрицы равна
бит, а размерность результирующей матрицы равна  элемента;
элемента; - входной операнд
 является управляющим, задает период накопления частных произведений и имеет вид циклической константы, в которой
является управляющим, задает период накопления частных произведений и имеет вид циклической константы, в которой  бит - "единица", а остальные
бит - "единица", а остальные  бит - "нули";
бит - "нули"; - входной операнд
 является циклической константой вида: младший бит - "ноль", а остальные 15 бит - "единица", которая используется для обнуления буферных разрядов в 3-х накапливаемых частных суммах.
является циклической константой вида: младший бит - "ноль", а остальные 15 бит - "единица", которая используется для обнуления буферных разрядов в 3-х накапливаемых частных суммах.

Рис. 4.8. Топологическая схема DD-ассоциативного сумматора-накопителя для умножения матриц 3*3 (n = 16 бит) (ADDA(DD))
В отличие от обычных алгоритмов поэлементного формирования результирующей матрицы, в МКМД-бит-потоковых субпроцессорах цифровой обработки сигналов используются алгоритмы формирования по строкам или по столбцам, в которых регистр-аккумулятор имеет размерность , где  - соответственно размер результирующей матрицы по числу строк или столбцов. В этом случае поточный алгоритм построчного формирования матрицы
- соответственно размер результирующей матрицы по числу строк или столбцов. В этом случае поточный алгоритм построчного формирования матрицы 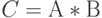 имеет вид:
имеет вид:

В МКМД-бит-потоковых сопроцессорах цифровой обработки сигналов алгоритм (4.5) реализуется следующим образом:
- "быстрые" переменные
 образуют бит-поток множимых
образуют бит-поток множимых  , в котором индекс изменяется с циклом
, в котором индекс изменяется с циклом  ; "медленные" переменные
; "медленные" переменные  образуют бит-поток множителей
образуют бит-поток множителей  , в котором индекс изменяется с циклом
, в котором индекс изменяется с циклом  , а каждая
, а каждая  "хранится" в теле микропрограммы такое же время;
"хранится" в теле микропрограммы такое же время; - суммирование ведется по столбцам соотношения (4.5), в которых находятся частные произведения
 , причем накопление суммы значения
, причем накопление суммы значения  осуществляется с помощью одного сумматора с FIFO-регистровым аккумулятором разрядности
осуществляется с помощью одного сумматора с FIFO-регистровым аккумулятором разрядности  .
.
Одно из главных преимуществ МКМД-бит-потоковых вычислительных технологий - это возможность варьировать разрядностью, а значит, и точностью непосредственно во время вычислений. Достигается это за счет высокой скорости генерацией микропрограмм соответствующих операционных устройств, что обеспечивается очень простыми алгоритмами рекуррентного наращивания микропрограмм, зависящих в данном случае от параметров результирующих потоков данных и 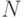 .
.
Действительно, при увеличении разрядности множимого в умножителе (см.
рис. 4.7) необходимо соответственно изменить только вид циклической константы  , а при увеличении разрядности множителя умножитель необходимо нарастить соответствующим числом столбцов, которые называются термами. Такой термальный синтез применим и к сумматору-накопителю, в котором варьируемым является только размер аккумулятора, а схемы суммирования и управления периодом накопления остаются неизменными (см.
рис. 4.8). В этом случае достаточно использовать ограниченное число термов расширения разрядности аккумулятора и, в частности, терм
рис. 4.8-б, если шаг наращивания составляет 18 бит. Этот терм пристраивается справа как столбец бит-матрицы
рис. 4.8. Его также можно использовать и при увеличении разрядности данных в слов-инструкции DCC
рис. 4.2, которая используется в схеме
рис. 4.6 при сопряжении умножителя, работающего в прямом коде, с сумматором-накопителем, работающем в дополнительном коде.
, а при увеличении разрядности множителя умножитель необходимо нарастить соответствующим числом столбцов, которые называются термами. Такой термальный синтез применим и к сумматору-накопителю, в котором варьируемым является только размер аккумулятора, а схемы суммирования и управления периодом накопления остаются неизменными (см.
рис. 4.8). В этом случае достаточно использовать ограниченное число термов расширения разрядности аккумулятора и, в частности, терм
рис. 4.8-б, если шаг наращивания составляет 18 бит. Этот терм пристраивается справа как столбец бит-матрицы
рис. 4.8. Его также можно использовать и при увеличении разрядности данных в слов-инструкции DCC
рис. 4.2, которая используется в схеме
рис. 4.6 при сопряжении умножителя, работающего в прямом коде, с сумматором-накопителем, работающем в дополнительном коде.
Евгений Акимов