|
Добрый день!
Скажите, пожалуйста,планируется ли продолжение курсов по нанотехнологиям? Спасибо, Евгений
|
Опубликован: 01.10.2013 | Доступ: свободный | Студентов: 267 / 26 | Длительность: 24:58:00
ISBN: 978-5-9963-0223-9
Темы: САПР, Аппаратное обеспечение, Нанотехнологии
Специальности: Разработчик аппаратуры
Лекция 4:
Специфика построения аппаратных платформ высокопроизводительных вычислительных систем с микропрограммным уровнем доступа
Наиболее просто оцениваются удельные аппаратные затраты на одну арифметико-логическую функцию табл. 3.11, и они минимальны у 2-й версии бит-процессора по всем показателям: на объект (ОУ), средства управления (СУ) и весь бит-процессор (БП).
| Тип бит-процессора | Количество функций | ОУ/функция | СУ/функция | БП/функция |
|---|---|---|---|---|
| Н1841 ВФ1 | 11 | 194/11=17.6 | 196/11=17.8 | 390/11=35.4 |
| Версия 1 (рис. 3.14) | 16 | 260/16=16.2 | 228/16=14.3 | 488/16=30.5 |
| Версия 2 (рис. 3.15) | 22 | 260/22=11.8 | 306/22=13.9 | 566/22=25.7 |
Если перейти к эквивалентному структурному базису и считать, что на один двухвходовой универсальный модуль (УЛМ 2) расходуется 40 КМОП-транзисторов, то в Н1841 ВФ1 удельные структурные затраты составляют почти 2,2 УЛМ 2 на 1 арифметико-логическую функцию, и они почти в 1,4 раза выше, чем у 2-й версии бит-процессора (1,56 УЛМ 2 на 1 арифметико-логическую функцию).
При оценке удельных структурных затрат на реализацию средств управления бит-процессором за структурный базис удобнее взять D -триггер (22 КМОП-транзистора). По этому показателю система управления операционным модулем бит-процессора 2-й версии в 1,3 раза эффективнее аналогичной системы Н1841 ВФ1, так как абсолютные значения составляют соответственно 1,65 бита и 2,2 бита.
При оценке разнообразия реализуемых бит-процессором коммутационных структур можно исходить из информационной емкости коммутационного поля регистра бит-инструкции. Однако такая оценка не учитывает скрытую избыточность (по управлению), так как практическая польза коммутационной структуры определяется видом и свойствами функций, реализуемых в операционном канале и канале транзита. В частности, если в канале АЛУ реализуется функция "арифметическая сумма", то в терминах
табл. 3.3 коммутационные структуры 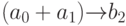 и
и 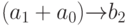 эквивалентны, так как эта функция симметрична по отно-шению к переименованию входов. Если же реализуемая бит-процессором функция асимметрична ("запоминание единицей" имеет первый информационный вход, а второй - управляющий), то приведенные выше коммутационные структуры - различны. Аналогичная ситуация складывается с асимметричными по времени задержки выходами канала транзита. Поэтому подсчет разнообразия коммутационных структур, реализуемых бит-процессором, фактически сводится к оценке кодовой избыточности по управлению входными и выходными коммутаторами, исходя из требований арифметико-логических и коммутационных функций, выполняемых в каналах АЛУ и транзита.
эквивалентны, так как эта функция симметрична по отно-шению к переименованию входов. Если же реализуемая бит-процессором функция асимметрична ("запоминание единицей" имеет первый информационный вход, а второй - управляющий), то приведенные выше коммутационные структуры - различны. Аналогичная ситуация складывается с асимметричными по времени задержки выходами канала транзита. Поэтому подсчет разнообразия коммутационных структур, реализуемых бит-процессором, фактически сводится к оценке кодовой избыточности по управлению входными и выходными коммутаторами, исходя из требований арифметико-логических и коммутационных функций, выполняемых в каналах АЛУ и транзита.
Оценку разнообразия коммутационных структур всего бит-процессора можно представить как произведение оценок возможных схем соединения входов-выходов, закрепленных за операционным каналом и каналами транзита. Объясняется это тем, что в бит-процессорах информационные потоки реализуются и адресуются независимо по этим каналам. Обозначим через  и
и  операторы размещений и сочетаний с соответствующими параметрами. Тогда для Н1841 ВФ1 коммутационные возможности выражаются:
операторы размещений и сочетаний с соответствующими параметрами. Тогда для Н1841 ВФ1 коммутационные возможности выражаются:
- канала АЛУ при реализации асимметричных функций двух переменных
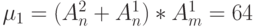 , где
, где  и
и  - число входов и выходов бит-процессора (
- число входов и выходов бит-процессора (  ), а верхние индексы - количество входных и выходных операндов реализуемой функции;
), а верхние индексы - количество входных и выходных операндов реализуемой функции; - канала транзита
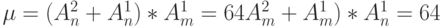 ;
; - бит-процессора
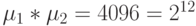 ,
,где показатель степени равен разрядности коммутационного поля бит-инструкции, что говорит о полном использовании информационной емкости этого поля.
Тем не менее:
- даже при реализации асимметричных функций коммутационное поле регистра инструкции избыточно, так как в операционном канале (канале транзита) в каждой фиксированной бит-инструкции реализуется либо
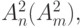 либо
либо 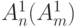 ;
; - при выполнении бит-процессором симметричных арифметико-логических функций "дифференциальная" кодовая избыточность возрастает почти в 2 раза, так как в этом случае
 .
.
Для извлечения подобного рода кодовой избыточности по управлению коммутационными ресурсами Н1841 ВФ1 необходимо использовать теперь уже обратное ассоциативное влияние кода операции на коммутационное поле бит-инструкции, что приводит к усложнению дешифрации последнего поля и нарушает эквивалентность объектных и абсолютных кодов микропрограмм.
Для 2-й версии бит-процессора (рис. 3.15) с системой бит-инструкций табл. 3.9 коммутационные возможности выражаются:
- канала АЛУ при реализации асимметричных по всем трем операндам функций (7-я функция
табл. 3.9 для
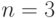 ):
):![\mu_{1} = [(A^{3}_n (C ^{1}_3 +1) + C^{2}_{4})]* A^1_m = 448,](/sites/default/files/tex_cache/953fe876a6edfe07ca007d76ed744661.png)
( 3.2) где
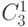 учитывает дополнительные коммутационные структуры за счет переименования входов-выходов
(
учитывает дополнительные коммутационные структуры за счет переименования входов-выходов
( 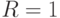 - см.
рис. 3.11),
- см.
рис. 3.11), 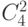 - различные варианты отождествления двух переменных при выполнении функций 1-й переменной;
- различные варианты отождествления двух переменных при выполнении функций 1-й переменной; - двух каналов транзита:
![\mu_{2} = [(A^{2}_m + A^1_m )( C ^{2}_{3} +1)+ A^1_m )]* A^1_n = 272,](/sites/default/files/tex_cache/7b03da1d20193982f35b8598a2b783b2.png)
( 3.3) где первое
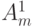 учитывает возможности отождествления выходов, второе
учитывает возможности отождествления выходов, второе  - возможности выходной коммутации 2-го канала транзита;
- возможности выходной коммутации 2-го канала транзита; - бит-процессорам
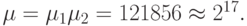
Отсюда следует, что информационные возможности коммутационного поля бит-процессора 2-й версии используются не более чем на 96 %, но и они превосходят аналогичные возможности Н1841 ВФ1 почти в 28 раз.
Из данных табл. 3.11 и табл. 3.12 видно, что удельные аппаратные затраты на коммутацию на 2-3 порядка ниже аналогичных затрат на арифметико-логические функции, что предопределяет дешевизну и высокую струк-
турную гибкость системы пересылки данных в МКМД-бит-матрицах. Если к этому добавить, что в задачах цифровой обработки сигналов и изображений реального времени операции пересылки данных увеличивают требуемую производительность на 1-2 порядка [70], то можно сказать, что именно FIFO -регистровые коммутационные структуры в сочетании с бит-процессорной обработкой вносят решающий вклад в повышение производительности МКМД-бит-потоковых субпроцессоров.
| Тип бит-процессора (БП) | Количество функций | ОУ/функция | СУ/функция | БП/функция |
|---|---|---|---|---|
| Н1841 ВФ1 | 212 | 0.075 | О064 | 0.14 |
| Версия 2 (рис. 3.15) | 0.96*217 | 0.0034 | 0.0035 | 0.007 |
Синтез (П)ПЗУ-программируемых бит-процессоров включает все перечисленные в разделе 3.2 этапы, и его основная особенность состоит в том, что на систему управления такими бит-процессорами расходуется меньше вентилей и меньше площади кристалла, чем у репрограмми-руемых бит-процессоров, так как она реализуется "программирующими контактными окнами", на каждое из которых расходуется площадь кристалла, сопоставимая с площадью одной базисной схемы "И - НЕ" или "ИЛИ - НЕ".
Поэтому синтез (П)ПЗУ-бит-процессоров можно проводить без учета ограничений на длину слова инструкции, которая в явном виде присутствует только в инструментальных кросс-средствах (П)ПЗУ-программируемых СБИС. Но при выборе системы бит-инструкций необходимо учитывать, что программист активно использует в своей работе обычно не более 10^{2} инструкций, состав которых в кросс-средствах можно проблемно и алгоритмически ориентировать, если операционные и коммутационные возможности (П)ПЗУ-бит-процессоров полны по отношению к более широкому набору бит-инструкций.
Выбор базовой (пословной) операции производится исходя из возможности использования (П)ПЗУ-бит-процессоров как в совокупности с репрограммируемыми бит-процессорами, так и самостоятельно при синтезе аппаратно емких устройств обработки. В последнем случае (П)ПЗУ-бит-матрицы служат основной полузаказного проектирования устройств цифровой обработки сигналов и изображений реального времени, что требует большей потенциальной структурно-функциональной гибкости, чем у рассмотренных выше репрограммируемых МКМД-бит-потоковых СБИС.
Чтобы удовлетворить последнее требование, достаточно в схеме
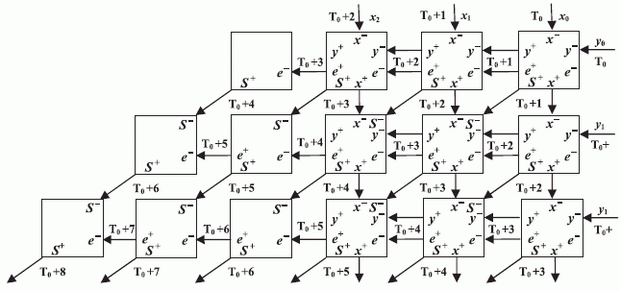
рис. 3.2 за базовую (пословную) операцию взять матрично-конвейерное умножение (МКУ), которое включает рассмотренное конвейерное умножение как частный случай. В МКУ
рис. 3.16 потоки данных должны распространяться по бит-матрице таким образом, чтобы обеспечить пространственно-временную встречу соответствующих 4-х бит-операндов: множимого 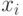 , множителя
, множителя 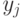 , частных сумм
, частных сумм  и "единицы переноса"
и "единицы переноса" 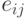 . На этом рисунке цифрами указаны такты поступления соответствующих бит-операндов на входы бит-процессоров матрицы, в которой индексы
. На этом рисунке цифрами указаны такты поступления соответствующих бит-операндов на входы бит-процессоров матрицы, в которой индексы  и
и  связаны с ее пространственными координатами, если за начало координат выбран правый верхний угол матрицы.
связаны с ее пространственными координатами, если за начало координат выбран правый верхний угол матрицы.
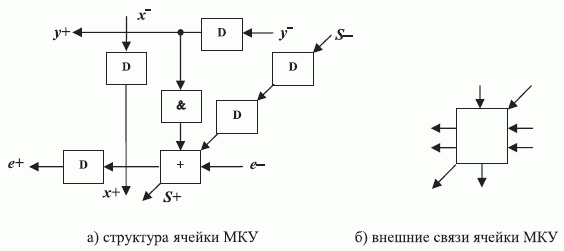
Чтобы выполнить условия "встречи" бит-операндов при реализации алгоритма МКУ, архитектура бит-процессора должна иметь вид рис. 3.17-а, откуда следует:
- систему внешних связей рис. 3.1 необходимо дополнить диагональной связью (рис. 3.17-б), введя в (П)ПЗУ-бит-процессор средства переименования входов-выходов, аналогичные рис. 3.8;
- операционное устройство (П)ПЗУ-бит-процессора должно быть рассчитано на 4 операнда, чтобы реализовать функцию полного сумматора с "внешней" по отношению к бит-процессору "единицей переноса", причем выход частной суммы должен быть задержан на 2 такта;
- (П)ПЗУ-бит-процессор должен иметь не менее двух независимо адресуемых каналов транзита, которые с учетом структуры репрограмми-руемых бит-процессоров допускают последовательно-параллельное соединение.
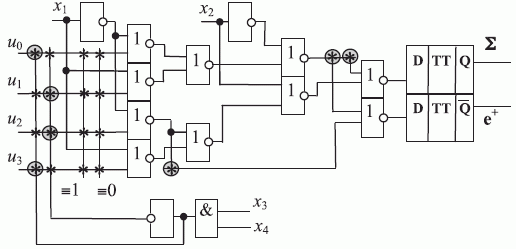
За основу АЛУ выберем нижний УЛМ2
рис. 3.12 и дополним его двухвходовой схемой "И", как того требует МКУ (см.
рис. 3.17). Программирование такого АЛУ ведется "вскрытыми контактными окнами", которые обозначены кружками на
рис. 3.18, где ассоциативная управляющая переменная формируется на выходе схемы "И", на входы которой поступают сомножители и . Поэтому здесь "единица переноса" используется как промежуточная информационная переменная, которая согласно схеме
рис. 3.14 распространяется по строкам бит-матрицы. Такое перераспределение функций между переменными допустимо, так как обе функции полного сумматора ( 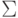 и
и  ) инвариантны переименованию входных переменных (см.
табл. 5.7 раздела 5.5 курса "Задачи и модели вычислительных наноструктур").
) инвариантны переименованию входных переменных (см.
табл. 5.7 раздела 5.5 курса "Задачи и модели вычислительных наноструктур").
В схеме рис. 3.18 вскрытые контактные окна, обеспечивающие гальваническую связь шин в точках пересечения, взятые в кружочки, соответствуют настройке (П)ПЗУ-бит-процессора на функцию "арифметическая сумма", реализуемую в конвейерном режиме без распространения "единицы переноса" за пределы (П)ПЗУ-бит-процессора.
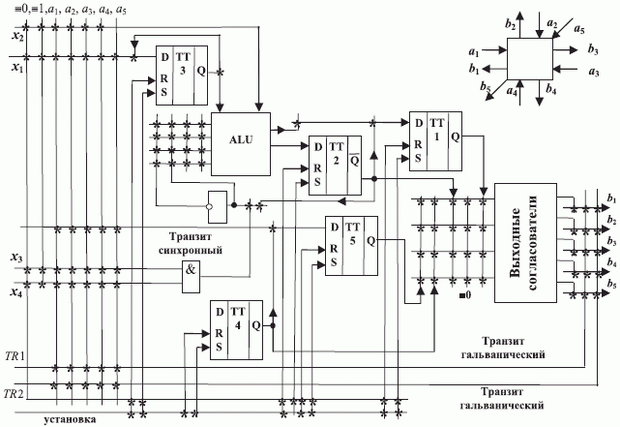
Выполнив остальные требования МКУ, получим схему (П)ПЗУ-бит-процессора рис. 3.19, которая была разработана в СССР в 1985 году и которая соответствует структурно-функциональным схемам современных ПЛИС [291]. В этой схеме переименование направлений приема-передачи данных осуществляется с помощью двух шин "гальванического транзита" ( TR -1 и TR -2), а программирующие контактные окна обозначены крестиками в точках пересечения внутренних гальванических связей (П)ПЗУ-бит-процессора.
Используя разложение Шеннона, можно показать, что УЛМ_{2} рис. 3.18 функционально полон по отношению к классу ЛФ трех переменных, то есть по сути является УЛМ_{3}, у которого одна из трех переменных поступает на его s -входы через схему "И".
Отсюда вытекает задача выбора для (П)ПЗУ-бит-процессора такой системы команд, которая, с одной стороны, была бы наглядной для восприятия программистами, а с другой стороны, была бы либо совместной с системой команд репрограммируемых бит-процессоров, либо в максимальной степени использовала функциональные возможности АЛУ.
В последнем случае произвольная коммутация входных переменных (  ) (П)ПЗУ-бит-процессора и реализация в его АЛУ заданного множества логических функций (ЛФ) и их инверсий реализуют преобразования, именуемые группой переименований [123] порядка
) (П)ПЗУ-бит-процессора и реализация в его АЛУ заданного множества логических функций (ЛФ) и их инверсий реализуют преобразования, именуемые группой переименований [123] порядка 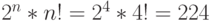 , по отношению к которой все множество ЛФ трех переменных разбивается на 14 классов смежности [103].
, по отношению к которой все множество ЛФ трех переменных разбивается на 14 классов смежности [103].
Евгений Акимов