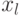


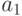

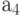
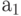
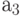
|
Добрый день!
Скажите, пожалуйста,планируется ли продолжение курсов по нанотехнологиям? Спасибо, Евгений
|
Опубликован: 01.10.2013 | Доступ: свободный | Студентов: 268 / 26 | Длительность: 24:58:00
ISBN: 978-5-9963-0223-9
Темы: САПР, Аппаратное обеспечение, Нанотехнологии
Специальности: Разработчик аппаратуры
Лекция 4:
Специфика построения аппаратных платформ высокопроизводительных вычислительных систем с микропрограммным уровнем доступа
3.3. Синтез ассоциативно управляемых МКМД-бит-потоковых матричных СБИС арифметико-логической обработки данных по критерию максимума функциональной интеграции при минимуме аппаратных затрат
Как и в обычных RISC -процессорах, аппаратные ресурсы бит-процессоров, а значит, и площадь кристалла бит-матричной СБИС расходуются на параллельное выполнение операционных, адресных, управляющих, интерфейсных и диагностических функций. Поэтому центральная проблема повышения интенсивности использования степени функциональной интеграции СБИС [276] состоит в оптимизации состава основных и вспомогательных функций бит-процессоров, обеспечивающих минимальные аппаратные затраты на реализацию заданного класса поток-операторов пользователя.
При этом специфика технологии прототипирования в вычислительной технике состоит в том, что необходимо не только повысить потребительские характеристики новой версии бит-матричных СБИС, но и сохранить микропрограммную совместимость новых версий с более ранней версией архитектуры, заложенной в данном случае в Н1841 ВФ1.
Таким образом, снижение топологических норм производства отечественных СБИС должно постоянно сопровождаться взаимосвязанной реконструкцией операционной, коммутационной и управляющей частей бит-процессора в Н1841 ВФ1. Связано это с тем, что в современной микроэлектронике скорость роста степени интеграции на кристаллах почти на порядок опережает скорость роста количества выводов в СБИС,
так как первый показатель пропорционален площади, занимаемой транзистором или вентилем, а второй - линейным размерам контактных площадок, обеспечивающих гальванические переходы от периферии кристалла к выводам матричных корпусов СБИС. В результате с ростом степени интеграции матричных СБИС практически всегда появляется дополнительный аппаратный ресурс, который и необходимо эффективно задействовать во время вычислений.
Поэтому в процессе реконструкции СБИС Н1841 ВФ1 прежде всего необходимо определить направления модификации структурно-функциональной схемы ее бит-процессоров, которая выбиралась исходя из эффективной реализации операций конвейерного умножения, составляющего основу подавляющего числа алгоритмов цифровой обработки сигналов и изображений реального времени. С этой целью рассмотрим алгоритм конвейерного умножения в качестве базовой пословной операции.
Пусть абсолютные значения сомножителей представлены  -разрядными двоичными числами в прямом коде
-разрядными двоичными числами в прямом коде 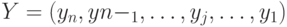
и 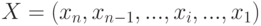 и поступают они на входы умножителя последовательно и младшим разрядом вперед.
и поступают они на входы умножителя последовательно и младшим разрядом вперед.
Тогда их произведение можно представить:
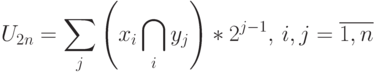 |
( 3.1) |
где  - многоместная операция логического умножения.
- многоместная операция логического умножения.
Если с индексом  связать пространственную координату систолической матрицы, а с индексом
связать пространственную координату систолической матрицы, а с индексом  - целочисленное время
- целочисленное время  , то отвечающий (3.1) алгоритм конвейерного умножения примет вид:
, то отвечающий (3.1) алгоритм конвейерного умножения примет вид:
Шаг 1. Выделить и запомнить на тактов в 1-й ячейке систолической матрицы содержимое 1-го бита множителя 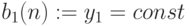 и переслать
и переслать  в следующую ячейку систолической матрицы.
в следующую ячейку систолической матрицы.
Шаг 2. Выполнить последовательно в 1-й ячейке систолической матрицы -местную операцию 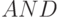 всех бит множимого с
всех бит множимого с 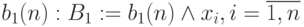 и переслать
и переслать 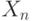 в следующую ячейку систолической матрицы.
в следующую ячейку систолической матрицы.
Шаг 3. Повторить во 2-й ячейке систолической матрицы шаги 1, 2 для 2-го бита множителя 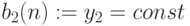 и переслать
и переслать 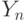 и в следующую ячейку систолической матрицы.
и в следующую ячейку систолической матрицы.
Шаг 4. Сдвинуть во 2-й ячейке систолической матрицы частное произведение  , на один такт по отношению к
, на один такт по отношению к  и сформировать частную сумму
и сформировать частную сумму 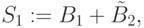 где
где 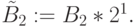
Шаг 5. Повторить в 3-й ячейке систолической матрицы шаги 3 и 4, сформировав частную сумму 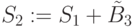 , где
, где 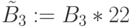 , и т. д. до
, и т. д. до 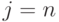 .
.
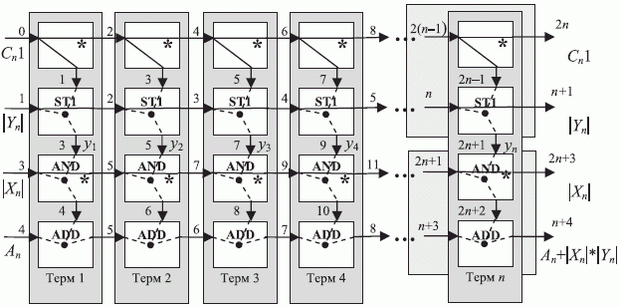
В системе команд Н1841 ВФ1 (см.
табл. 3.1) данному алгоритму соответствует структурная схема конвейерного умножителя рис. 3.8, в которой операционный канал обозначен пунктирными линиями с соответствующей операцией, канал транзита - сплошными линиями, а дополнительная задержка - звездочкой (  ) в соответствующем канале. Цифрами обозначены такты поступления младшего разряда операнда на вход соответствующего бит-процессора, причем прохождение операнда через любой канал обходится не менее чем в 1 такт задержки. Циклическая константа, задающая разрядность ( ) преобразуемых операндов, имеет вид
) в соответствующем канале. Цифрами обозначены такты поступления младшего разряда операнда на вход соответствующего бит-процессора, причем прохождение операнда через любой канал обходится не менее чем в 1 такт задержки. Циклическая константа, задающая разрядность ( ) преобразуемых операндов, имеет вид 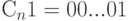 , где младший бит - "1", а остальные
, где младший бит - "1", а остальные 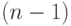 бит - "нули".
бит - "нули".
Если каждый столбец бит-матрицы рис. 3.8 разбить на верхнюю и нижнюю половины, то получим ячейки систолической матрицы с двумя горизонтально расположенными входами-выходами, которые взаимодействуют между собой одним вертикальным входом-выходом, что соответствует приведенному выше алгоритму умножения.
Из приведенных данных следует:
- бит-матрица Н1841 ВФ1 на макроуровне эмулирует линейную систолическую матрицу конвейерного умножителя, то есть работает в режиме "микро-МКМД" - "макро-ОКМД";
- даже при реализации базовой пословной операции дорогой по площади ресурс внешних гальванических связей бит-процессоров Н1841 ВФ1 используется не более чем на
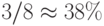 ;
; - даже при реализации базовой пословной операции внутренний операционный и коммутационный ресурс бит-процессоров Н1841 ВФ1 используется в среднем на 50%, если иметь в виду, что в канале АЛУ можно выполнить 18 элементарных арифметико-логических операций, совмещенных по времени и аппаратуре с пересылкой результатов (см. раздел 3.1).
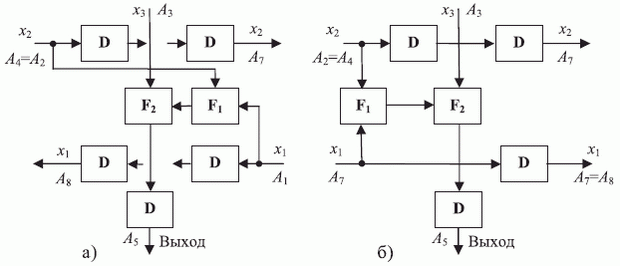
Разобьем систолическую матрицу рис. 3.8 на две части: верхнюю и нижнюю. Тогда для объединения возможностей двух бит-процессоров Н1841 ВФ1 в одном бит-процессоре новой версии необходимо реализовать:
- однонаправленный двумерный поток операндов;
- операционное устройство на 3 операнда, что соответствует типовым требованиям двумерных систолических структур рис. 3.9 [289].
Для перехода от двунаправленных ортогональных связей
рис. 3.9-а к однонаправленным двумерным связям
рис. 3.9-б достаточно в каждом бит-процессоре реализовать двунаправленные перепрограммируемые порты ввода-вывода
рис. 3.10 и два независимых канала транзита с задержкой на 1 и 2 такта. Двунаправленные порты ввода-вывода увеличивают коэффициент использования двунаправленных ортогональных связей в конвейерном умножителе
рис. 3.8 до 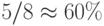 , а в типовых систолических структурах
рис. 3.9 до
, а в типовых систолических структурах
рис. 3.9 до 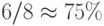 .
.
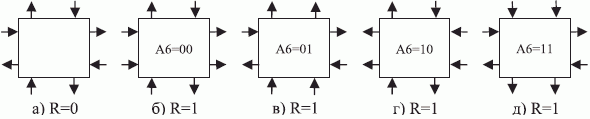
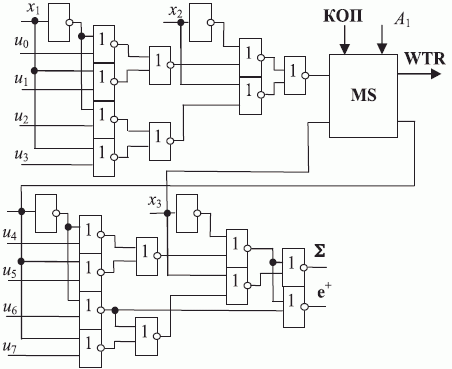
Для кодирования всех типов внешних "систолических" связей рис. 3.3 требуется 2 бита в слове инструкции и признак типа связи ( R ).
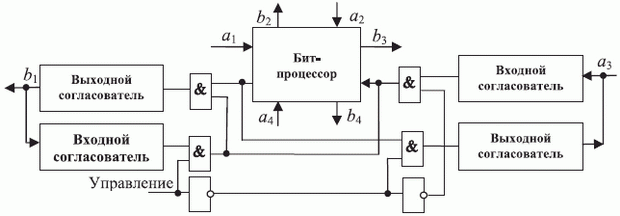
Удовлетворяющая функциональным требованиям
рис. 3.9 схема АЛУ на 3 входа включает (рис. 3.12) два мультиплексора с двумя управляющими входами, которые используются как универсальные логические модули по отношению к двум переменным 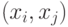 (УЛМ). Первый из этих УЛМ реализует все 16 логических функций 2-х переменных
(УЛМ). Первый из этих УЛМ реализует все 16 логических функций 2-х переменных 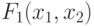 , а второй в дополнение к ним реализует еще и конечно-автоматные функции
, а второй в дополнение к ним реализует еще и конечно-автоматные функции 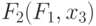 типа "арифметическая сумма" и "запоминание единицей", первая из которых используется как единственная арифметическая, а вторая - как единственная оперативно управляющая потоком данных операция.
типа "арифметическая сумма" и "запоминание единицей", первая из которых используется как единственная арифметическая, а вторая - как единственная оперативно управляющая потоком данных операция.
Независимое управление УЛМ2 рис. 3.12 с двумя информационными входами требует 8-битного кода операции (КОП), что увеличивает разрядность регистра инструкции на 50 %, который является наиболее аппаратно емким блоком бит-процессора (см. табл. 3.3).
Для сохранения преемственности "снизу-вверх" с Н1841 ВФ1 достаточно реализовать четыре функции трех переменных
табл. 3.5. Эти функции, с одной стороны, ориентированы на ассоциативную обработку потоков данных, активно использующую такие пословные операции предварительного "маскирования", как "логическое умножение", "равнозначность", "неравнозначность" [46]. С другой стороны, они обеспечивают настройку на все функции 1-й и 2-х переменных Н1841 ВФ1 за счет "фиксации в ноль" (  ) одной или двух из трех входных переменных, что в КМОП-технологии реализуется настройкой входных коммутаторов на незадействованные входы бит-процессора.
) одной или двух из трех входных переменных, что в КМОП-технологии реализуется настройкой входных коммутаторов на незадействованные входы бит-процессора.
| № п/п | Количество операндов ( 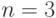 ) ) |
КОП | Условие (1) | Условие (2) | Количество операндов ( 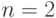 ) ) |
№ п/п |
|---|---|---|---|---|---|---|
| 1 | 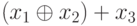 |
00 | - | 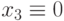 |
 |
1 |
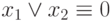 |
 |
2 | ||||
| 2 | Расширенный транзит | 00 |  |
|
- | |
| 3 |  |
01 | - | 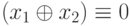 |
 |
3 |
| 2 | Расширенный транзит | 01 | |
 |
4 | |
| 4 | 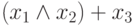 |
10 | - | |
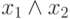 |
5 |
|
|
|||||
| 2 | Расширенный транзит | 10 | |
- | ||
| 5 | 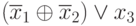 |
11 | - | |
 |
6 |
|
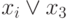 |
7 | ||||
|
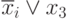 |
8 | ||||
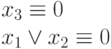 |
 |
9 | ||||
| 11 | |
 |
10 |
В таком бит-процессоре используется интегрированная двухступенчатая схема управления АЛУ: с раздельными информационными и управляющими входами при задании функций трех переменных и со смешанными ( ассоциирующими ) информационными и управляющими входами при выделении функций одной или двух переменных из функций трех переменных, где задействованы ресурсы управления системой внешней коммутации бит-процессора. Благодаря этому на хранение кода операции (КОП) бит-процессора можно затратить 2 бита регистра инструкции, а для функциональной подстройки на функции двух переменных использовать коммутационное поле этой же бит-инструкции.
Все функции двух переменных симметричны по отношению к переименованию переменных  (кроме функции "запоминание единицей" - см.
табл. 5.8 курса "Задачи и модели вычислительных наноструктур"]).
Поэтому для входной коммутации операционного канала на три переменные достаточно использовать взаимозависимое управление с помощью схемы выбора "два из четырех"
(кроме функции "запоминание единицей" - см.
табл. 5.8 курса "Задачи и модели вычислительных наноструктур"]).
Поэтому для входной коммутации операционного канала на три переменные достаточно использовать взаимозависимое управление с помощью схемы выбора "два из четырех"  ) и схемы полного коммутатора "четыре в один", первая из которых выделяет две "симметричные" переменные из четырех возможных (рис. 3.13).
) и схемы полного коммутатора "четыре в один", первая из которых выделяет две "симметричные" переменные из четырех возможных (рис. 3.13).
Благодаря этому на входную коммутацию операционного канала на три переменные можно затратить не три, а два 2-битных поля регистра инструкции ( 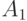 и
и  ), причем в поле в режиме коммутации используется кодовая комбинация "3" (табл. 3.6).
), причем в поле в режиме коммутации используется кодовая комбинация "3" (табл. 3.6).
Евгений Акимов