Вероятностные и компактные генетические алгоритмы
8.2. Пошаговое обучение на основе виртуальной популяции
Следующим рассмотрим подход, предложенный в [2] – PBIL (Population-Based Incremental Learning). На основе представления популяции вектором вероятности 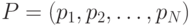 вместо стандартного ГА используется следующий алгоритм поиска оптимального решения:
вместо стандартного ГА используется следующий алгоритм поиска оптимального решения:

Как видно из псевдокода, виртуальная популяция каждый раз случайным образом генерируется согласно текущему вектору вероятностей, который корректируется в сторону лучшей особи. Метод корректировки вектора вероятностей, по сути, взят из конкурирующего метода обучения нейронных сетей без учителя. Таким образом, здесь "эволюционирует" вектор вероятностей. Этот подход развит многими авторами и некоторые его модификации допускают достаточно простую аппаратную реализацию.
8.3. Компактный генетический алгоритм
Компактный ГА (КГА)[3], как и PBIL, модифицирует вектор вероятности, однако помимо фазы кроссинговера здесь также игнорируется и фаза мутации, что позволяет сконцентрировать все внимание на механизме селекции, который основан на турнирном методе отбора особей. Кроме того, компактный ГА моделирует конечную популяцию и требует меньше вычислительных ресурсов. Псевдокод алгоритма представлен ниже:

Критерием остановки работы алгоритма выступает следующее условие:  для всех
для всех 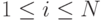 .
.
8.4. Генетический алгоритм SELFISH
Данный алгоритм был разработан в [4] на основании современной интерпретации Дарвиновской теории механизмов естественного отбора, предложенной биологом Ричардом Доукинзом. Ключевым моментом нового подхода стала гипотеза о том, что базовым элементом эволюции является ген, а не особь. В связи с этим рассматриваются хромосомы, гены которых могут принимать различное количество значений в зависимости от своего расположения внутри хромосомы. Поэтому вектор вероятностей трансформируется в более сложную структуру: 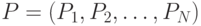 , где
, где 
Отметим, что здесь 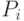 могут иметь различную мощность
могут иметь различную мощность 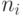 , поскольку разные гены могут принимать различное число значений. Псевдокод предложенного алгоритма SELFISH имеет следующий вид:
, поскольку разные гены могут принимать различное число значений. Псевдокод предложенного алгоритма SELFISH имеет следующий вид:

Здесь функция "поощрение" увеличивает, а функция "наказание" уменьшает текущие вероятности для соответствующих значений всех генов в хромосоме на 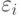 . То есть
. То есть
 ,где
,где 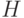 – некоторая хромосома.
– некоторая хромосома.Функция "выбор_особи" выполняется следующим образом:

Как видно из псевдокода она, помимо всего прочего, реализует процесс мутирования генов.
В заключение добавим, что критерий останова работы алгоритма определяется как состояние, в котором для каждого гена (локуса) 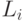 существует аллель (одно из возможных значений гена)
существует аллель (одно из возможных значений гена) 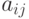 , чья вероятность больше заданного
, чья вероятность больше заданного 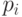 (обычно принимает значение ).
(обычно принимает значение ).