Методы сжатия без потерь
Интервальное кодирование
В отличие от классического алгоритма, интервальное кодирование предполагает, что мы
имеем дело с целыми дискретными величинами, которые могут принимать ограниченное число
значений. Как уже было отмечено, начальный интервал в целочисленной арифметике записывается
в виде  или
или ![[0,N-1]](/sites/default/files/tex_cache/cf5371a543f0bfcb7118859df810f450.png) , где
, где  - число возможных
значений переменной, используемой для хранения границ интервала.
- число возможных
значений переменной, используемой для хранения границ интервала.
Чтобы наиболее эффективно сжать данные, мы должны закодировать каждый символ  посредством
посредством  битов, где
битов, где  - частота
символа . Конечно, на практике такая точность недостижима, но мы можем
для каждого символа отвести в интервале диапазон значений
- частота
символа . Конечно, на практике такая точность недостижима, но мы можем
для каждого символа отвести в интервале диапазон значений 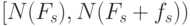 , где
, где 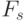 - накопленная частота символов,
предшествующих символу в алфавите,
- накопленная частота символов,
предшествующих символу в алфавите, 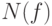 - значение,
соответствующее частоте
- значение,
соответствующее частоте  в интервале из возможных значений.
И, чем больше будет
в интервале из возможных значений.
И, чем больше будет 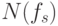 , тем точнее будет представлен символ
в интервале. Следует отметить, что для всех символов алфавита должно соблюдаться неравенство
, тем точнее будет представлен символ
в интервале. Следует отметить, что для всех символов алфавита должно соблюдаться неравенство  .
.
Задачу увеличения размера интервала выполняет процедура, называемая нормализацией. Практика показывает, что можно отложить выполнение нормализации на некоторое время, пока размер интервала обеспечивает приемлемую точность. Микаэль Шиндлер (Michael Schindler) предложил в работе [1.3] рассматривать выходной поток как последовательность байтов, а не битов, что избавило от битовых операций и позволило производить нормализацию заметно реже. И чаще всего нормализация обходится без выполнения переноса, возникающего при сложении значений нижней границы интервала и размера интервала. В результате скорость кодирования возросла в полтора раза при крайне незначительной потери в степени сжатия (размер сжатого файла обычно увеличивается лишь на сотые доли процента).
Выходные данные арифметического кодера можно представить в виде четырех составляющих:
- Составляющая, записанная в выходной файл, которая уже не может измениться.
- Один элемент (бит или байт), который может быть изменен переносом, если последний возникнет при сложении значений нижней границы интервала и размера интервала.
- Блок элементов, имеющих максимальное значение, через которые по цепочке может пройти перенос.
- Текущее состояние кодера, представленное нижней границей интервала.
Пример представлен в табл. 1.4
При выполнении нормализации возможны следующие действия:
- Если интервал имеет приемлемый для обеспечения заданной точности размер, нормализация не нужна.
- Если при сложении значений нижней границы интервала и размера интервала не возникает переноса, составляющие 2 и 3 могут быть записаны в выходной файл без изменений.
- В случае возникновения переноса он выполняется в составляющих 2 и 3, после чего они также записываются в выходной файл.
- Если элемент, претендующий на запись в выходной файл, имеет максимальное значение (в случае бита - 1, в случае байта - 0xFF), то он может повлиять на предыдущий при возникновении переноса. Поэтому этот элемент записывается в блок, соответствующий третьей составляющей.
Ниже приведен исходный текст алгоритма, реализующего нормализацию для интервального кодирования [1.3].
// Максимальное значение, которое может принимать
// переменная. Для 32-разрядной арифметики
// CODEBITS = 31. Один бит отводится для
// определения факта переноса.
#define TOP (1<<CODEBITS)
// Минимальное значение, которое может принимать
// размер интервала. Если значение меньше,
// требуется нормализация
#define BOTTOM (TOP>>8)
// На сколько битов надо сдвинуть значение нижней
// границы интервала, чтобы остался один байт
#define SHIFTBITS (CODEBITS-8)
// Если для хранения значений используется 31 бит,
// каждый символ сдвинут на 1 байт вправо
// в выходном потоке, и при декодировании приходится
// его считывать в 2 этапа.
#define EXTRABITS ((CODEBITS-1)%8+1)
// Используемые глобальные переменные:
// next_char - символ, который может быть изменен
// переносом (составляющая 2).
// carry_counter - число символов, через которые
// может пройти перенос до символа next_char
// (составляющая 3).
// low - значение нижней границы интервала,
// начальное значение равно нулю.
// range - размер интервала,
// начальное значение равно TOP.
void encode_normalize( void ) {
while( range <= BOTTOM ) {
// перенос невозможен, поэтому возможна
// запись в выходной файл (ситуация 2)
if( low < 0xFF << SHIFTBITS ) {
output_byte( next_char );
for(;carry_counter;carry_counter--)
output_byte(0xFF);
next_char = low >> SHIFTBITS;
// возник перенос (ситуация 3)
} else if( low >= TOP ) {
output_byte( next_char+1 );
for(;carry_counter;carry_counter--)
output_byte(0x0);
next_char = low >> SHIFTBITS;
// элемент, который может повлиять на перенос
// (ситуация 4)
} else {
carry_counter++;
}
range <<= 8;
low = (low << 8) & (TOP-1);
}
}
void decode_normalize( void ) {
while( range <= BOTTOM ) {
range <<= 1;
low = low<<8 |
((next_char<<EXTRABITS) & 0xFF);
next_char = input_byte();
low |= next_char >> (8-EXTRABITS);
range <<= 8;
}
}
Пример
1.1.
Для сравнения приведем текст функции, оперирующей с битами, из работы [1.2]:
#define HALF (1<<(CODEBITS-1))
#define QUARTER (HALF>>1)
void bit_plus_follow( int bit ) {
output_bit( bit );
for(;carry_counter;carry_counter--)
output_bit(!bit);
}
void encode_normalize( void ) {
while( range <= QUARTER ) {
if( low >= HALF ) {
bit_plus_follow(1);
low -= HALF;
} else if( low + range <= HALF ) {
bit_plus_follow(0);
} else {
carry_counter++;
low -= QUARTER;
}
low <<= 1;
range <<= 1;
}
}
void decode_normalize( void ) {
while( range <= QUARTER ) {
range <<= 1;
low = low<<1 |input_bit();
}
}Процедура интервального кодирования очередного символа выглядит следующим образом:
void encode(
int symbol_freq, // частота кодируемого символа
int prev_freq, // накопленная частота символов,
// предшествующих кодируемому
// в алфавите
int total_freq // частота всех символов
) {
int r = range / total_freq;
low += r*prev_freq;
range = r*symbol_freq;
encode_normalize();
}Рассмотрим пример интервального кодирования строки "КОВ.КОРОВА". Частоты символов представлены в табл. 1.5
| Индекс | Символ | Symbol_freq | Prev_freq |
| 0 | О | 3 | 0 |
| 1 | К | 2 | 3 |
| 2 | В | 2 | 5 |
| 3 | Р | 1 | 7 |
| 4 | А | 1 | 8 |
| 5 | "" | 1 | 9 |
| Total_freq | 10 |
Для кодирования строки будем использовать функцию compress:
void compress(
DATAFILE *DataFile // файл исходных данных
) {
low = 0;
range = TOP;
next_char = 0;
carry_counter = 0;
while( !DataFile.EOF ()) {
c = DataFile.ReadSymbol() // очередной символ
encode( Symbol_freq[c], Prev_freq[c], 10 );
}
}В табл. 1.6 представлен результаты процесса кодирования функцией compress:
Как уже было отмечено, чаще всего при нормализации не происходит переноса. Исходя из этого, Дмитрий Субботин1Dmitry Subbotin. русский народный rangecoder// Сообщение в эхо-конференции FIDO RU.COMPRESS. 1 мая 1999 предложил отказаться от переноса вовсе. Оказалось, что потери в сжатии совсем незначительны, порядка нескольких байт. Впрочем, выигрыш по скорости тоже оказался не очень заметен. Главное достоинство такого подхода - в простоте и компактности кода. Вот как выглядит функция нормализации для 32-разрядной арифметики:
#define CODEBITS 24
#define TOP (1<<CODEBITS)
#define BOTTOM (TOP>>8)
#define BIGBYTE (0xFF<<(CODEBITS-8))
void encode_normalize( void ) {
while( range < BOTTOM ) {
if( low & BIGBYTE == BIGBYTE &&
range + (low & BOTTOM-1) >= BOTTOM )
range = BOTTOM - (low & BOTTOM-1);
output_byte(low>>24);
range<<=8;
low<<=8;
}
}Можно заметить, что избежать переноса нам позволяет своевременное принудительное уменьшение значение размера интервала. Оно происходит тогда, когда второй по старшинству байт low принимает значение 0xFF, а при добавлении к low значения размера интервала range возникает перенос. Так выглядит оптимизированная процедура нормализации:
void encode_normalize( void ) {
while((low ^ low+range)<TOP ||
range < BOTTOM &&
((range = -low & BOTTOM-1),1)) {
output_byte(low>>24);
range<<=8;
low<<=8;
}
}
void decode_normalize( void ) {
while((low ^ low+range)<TOP ||
range<BOTTOM &&
((range= -low & BOTTOM-1),1)) {
low = low<<8 | input_byte();
range<<=8;
}
}