Методы сжатия без потерь
В основе всех методов сжатия лежит простая идея: если представлять часто используемые элементы короткими кодами, а редко используемые - длинными кодами, то для хранения блока данных требуется меньший объем памяти, чем если бы все элементы представлялись кодами одинаковой длины. Данный факт известен давно: вспомним, например, азбуку Морзе, в которой часто используемым символам поставлены в соответствие короткие последовательности точек и тире, а редко встречающимся - длинные.
Точная связь между вероятностями и кодами установлена в теореме Шеннона о кодировании
источника, которая гласит, что элемент 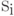 , вероятность
появления которого равняется
, вероятность
появления которого равняется  , выгоднее всего представлять
, выгоднее всего представлять  битами. Если при кодировании размер кодов
всегда в точности получается равным битам,
то в этом случае длина закодированной последовательности будет минимальной для всех
возможных способов кодирования. Если распределение вероятностей
битами. Если при кодировании размер кодов
всегда в точности получается равным битам,
то в этом случае длина закодированной последовательности будет минимальной для всех
возможных способов кодирования. Если распределение вероятностей  неизменно, и вероятности появления элементов независимы, то мы можем найти среднюю длину
кодов как среднее взвешенное
неизменно, и вероятности появления элементов независимы, то мы можем найти среднюю длину
кодов как среднее взвешенное
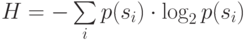 |
( 1а) |
Это значение также называется энтропией распределения вероятностей F или энтропией источника в заданный момент времени.
Обычно вероятность появления элемента является условной, т.е. зависит от какого-то
события. В этом случае при кодировании очередного элемента
распределение вероятностей F принимает одно из возможных значений  , то есть
, то есть  , и, соответственно,
, и, соответственно, 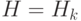 .
Можно сказать, что источник находится в состоянии k, которому соответствует
набор вероятностей
.
Можно сказать, что источник находится в состоянии k, которому соответствует
набор вероятностей  генерации всех возможных элементов
генерации всех возможных элементов 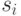 .
Поэтому среднюю длину кодов можно вычислить по формуле
.
Поэтому среднюю длину кодов можно вычислить по формуле
 |
( 1б) |
где 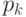 - вероятность того, что F примет k -ое
значение, или, иначе, вероятность нахождения источника в состоянии k.
- вероятность того, что F примет k -ое
значение, или, иначе, вероятность нахождения источника в состоянии k.
Итак, если нам известно распределение вероятностей элементов, генерируемых источником, то мы можем представить данные наиболее компактным образом, при этом средняя длина кодов может быть вычислена по формуле (1).
Но в подавляющем большинстве случаев истинная структура источника нам не известна,
поэтому необходимо строить модель источника, которая позволила бы нам в каждой позиции
входной последовательности оценить вероятность появления каждого
элемента алфавита входной последовательности. В этом
случае мы оперируем оценкой  вероятности элемента .
вероятности элемента .
Методы сжатия могут строить модель источника адаптивно по мере обработки потока данных или использовать фиксированную модель, созданную на основе априорных представлений о природе типовых данных, требующих сжатия.
Процесс моделирования может быть либо явным, либо скрытым. Вероятности элементов могут использоваться в методе как явным, так и неявным образом. Но всегда сжатие достигается за счет устранения статистической избыточности в представлении информации.
Ни один компрессор не может сжать любой файл. После обработки любым компрессором размер части файлов уменьшится, а оставшейся части - увеличится или останется неизменным. Данный факт можно доказать исходя из неравномерности кодирования, т.е. разной длины используемых кодов, но наиболее прост для понимания следующий комбинаторный аргумент.
Существует 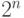 различных файлов длины
различных файлов длины  битов,
где
битов,
где 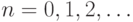 Если размер каждого такого файла в результате обработки
уменьшается хотя бы на 1 бит, то исходным файлам будет соответствовать
самое большее
Если размер каждого такого файла в результате обработки
уменьшается хотя бы на 1 бит, то исходным файлам будет соответствовать
самое большее 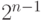 различающихся архивных файлов. Тогда по крайней мере
одному архивному файлу будет соответствовать несколько различающихся исходных, и,
следовательно, его декодирование без потерь информации невозможно в принципе.
различающихся архивных файлов. Тогда по крайней мере
одному архивному файлу будет соответствовать несколько различающихся исходных, и,
следовательно, его декодирование без потерь информации невозможно в принципе.
Вышесказанное предполагает, что файл отображается в один файл, и объем данных указывается в самих данных. Если это не так, то следует учитывать не только суммарный размер архивных файлов, но и объем информации, необходимой для описания нескольких взаимосвязанных архивных файлов и/или размера исходного файла. Общность доказательства при этом сохраняется.
Поэтому невозможен "вечный" архиватор, который способен бесконечное число раз сжимать свои же архивы. "Наилучшим" архиватором является программа копирования, поскольку в этом случае мы можем быть всегда уверены в том, что объем данных в результате обработки не увеличится.
Регулярно появляющиеся заявления о создании алгоритмов сжатия, "обеспечивающих сжатие в десятки раз лучшее, чем у обычных архиваторов", являются либо ложными слухами, порожденными невежеством и погоней за сенсациями, либо рекламой аферистов. В области сжатия без потерь, т.е. собственно сжатия, такие революции невозможны. Безусловно, степень сжатия компрессорами типичных данных будет неуклонно расти, но улучшения составят в среднем десятки или даже единицы процентов, при этом каждый последующий этап эволюции будет обходиться значительно дороже предыдущего. С другой стороны, в сфере сжатия с потерями, в первую очередь компрессии видеоданных, все еще возможно многократное улучшение сжатия при сохранении субъективной полноты получаемой информации.