Методы сжатия без потерь
Канонический алгоритм Хаффмана
Один из классических алгоритмов, известных с 60-х годов. Использует только частоту появления одинаковых байт во входном блоке данных. Сопоставляет символам входного потока, которые встречаются чаще, цепочку битов меньшей длины. И, напротив, встречающимся редко - цепочку большей длины. Для сбора статистики требует двух проходов по входному блоку (также существуют однопроходные адаптивные варианты алгоритма).
Для начала введем несколько определений.
Определение. Пусть задан алфавит  ,
состоящий из конечного числа букв. Конечную последовательность символов из
,
состоящий из конечного числа букв. Конечную последовательность символов из 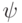

будем называть словом в алфавите , а число  - длиной
слова
- длиной
слова  . Длина слова обозначается как
. Длина слова обозначается как 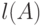
Пусть задан алфавит,  . Через
. Через 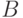 обозначим слово в алфавите
обозначим слово в алфавите  и через
и через  - множество
всех непустых слов в алфавите
- множество
всех непустых слов в алфавите  .
.
Пусть  - множество всех непустых слов в алфавите
- множество всех непустых слов в алфавите  , и
, и  - некоторое подмножество множества
- некоторое подмножество множества  .
Пусть также задано отображение
.
Пусть также задано отображение 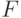 , которое каждому слову ,
, которое каждому слову ,  , ставит в соответствие слово
, ставит в соответствие слово
 ,
,  .
.
Слово 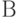 будем назвать кодом сообщения , а переход от слова к его коду - кодированием.
будем назвать кодом сообщения , а переход от слова к его коду - кодированием.
Определение. Рассмотрим соответствие между буквами алфавита
и некоторыми словами алфавита :


 .
.

Это соответствие называют схемой и обозначают через  . Оно
определяет кодирование следующим образом: каждому слову
. Оно
определяет кодирование следующим образом: каждому слову  из
из  ставится в соответствие слово
ставится в соответствие слово  , называемое
кодом слова . Слова
, называемое
кодом слова . Слова  называются элементарными кодами.
Данный вид кодирования называют алфавитным кодированием.
называются элементарными кодами.
Данный вид кодирования называют алфавитным кодированием.
Определение. Пусть слово имеет вид

Тогда слово  называется началом или префиксом слова ,
а
называется началом или префиксом слова ,
а 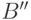 - концом слова . При этом пустое слово
- концом слова . При этом пустое слово  и само слово считаются началами и концами слова .
и само слово считаются началами и концами слова .
Определение. Схема обладает свойством префикса,
если для любых  и
и  (
(  ) слово
) слово  не является
префиксом слова
не является
префиксом слова  .
.
Теорема 1. Если схема обладает свойством префикса,
то алфавитное кодирование будет взаимно однозначным.
Доказательство теоремы можно найти в [1.4].
Предположим, что задан алфавит  и набор вероятностей
и набор вероятностей  появления символов
появления символов 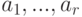 . Пусть, далее, задан алфавит
. Пусть, далее, задан алфавит  ,
,  .
Тогда можно построить целый ряд схем алфавитного кодирования
.
Тогда можно построить целый ряд схем алфавитного кодирования
.
обладающих свойством взаимной однозначности.
Для каждой схемы можно ввести среднюю длину  , определяемую как
математическое ожидание длины элементарного кода:
, определяемую как
математическое ожидание длины элементарного кода:
 - длины
слов.
- длины
слов.
Длина показывает, во сколько раз увеличивается средняя длина слова
при кодировании с помощью схемы .
Можно показать, что достигает величины своего минимума  на некоторой и определяется как
на некоторой и определяется как

Определение. Коды, определяемые схемой с  называются кодами с минимальной избыточностью, или кодами
Хаффмана.
называются кодами с минимальной избыточностью, или кодами
Хаффмана.
Коды с минимальной избыточностью дают в среднем минимальное увеличение длин слов при соответствующем кодировании.
В нашем случае, алфавит  задает символы входного
потока, а алфавит
задает символы входного
потока, а алфавит  т.е. состоит всего из нуля и единицы.
т.е. состоит всего из нуля и единицы.
Алгоритм построения схемы можно представить следующим образом:
Шаг 1. Упорядочиваем все буквы входного алфавита в порядке убывания вероятности.
Считаем все соответствующие слова из алфавита пустыми.
Шаг 2. Объединяем два символа  и
и  с наименьшими вероятностями
с наименьшими вероятностями  и
и  в псевдосимвол
в псевдосимвол  c вероятностью
c вероятностью  . Дописываем 0 в начало слова
. Дописываем 0 в начало слова  , и 1 в начало слова
, и 1 в начало слова  .
.
Шаг 3. Удаляем из списка упорядоченных символов  и , заносим туда псевдосимвол . Проводим шаг 2, добавляя при
необходимости 1 или ноль для всех слов , соответствующих псевдосимволам,
до тех пор, пока в списке не останется 1 псевдосимвол.
и , заносим туда псевдосимвол . Проводим шаг 2, добавляя при
необходимости 1 или ноль для всех слов , соответствующих псевдосимволам,
до тех пор, пока в списке не останется 1 псевдосимвол.
Пример: Пусть у нас есть 4 буквы в алфавите  ,
,  .
Процесс построения схемы представлен на рис 1.1 :
.
Процесс построения схемы представлен на рис 1.1 :
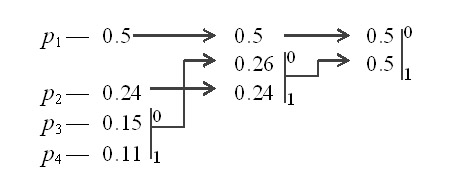
Производя действия, соответствующие 2-му шагу, мы получаем псевдосимвол с вероятностью 0.26 (и приписываем 0 и 1 соответствующим словам). Повторяя же эти действия для измененного списка, мы получаем псевдосимвол с вероятностью 0.5. И, наконец, на последнем этапе мы получаем суммарную вероятность 1.
Для того, чтобы восстановить кодирующие слова, нам надо пройти по стрелкам от начальных
символов к концу получившегося бинарного дерева. Так, для символа с вероятностью 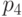 получим
получим  , для
, для  получим
получим  , для
, для  получим
получим  ,
для
,
для  получим
получим  . Что соответствует схеме:
. Что соответствует схеме:

Эта схема представляет собой префиксный код, являющийся кодом Хаффмана.
Самый часто встречающийся в потоке символ 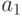 мы будем кодировать самым
коротким словом 0, а самый редко встречающийся
мы будем кодировать самым
коротким словом 0, а самый редко встречающийся  - длинным словом 101.
- длинным словом 101.
Для последовательности из 100 символов, в которой символ
встретится 50 раз, символ  - 24 раза, символ
- 24 раза, символ  - 15 раз, а символ - 11 раз, данный код позволит получить
последовательность из 176 битов
- 15 раз, а символ - 11 раз, данный код позволит получить
последовательность из 176 битов  Т.е. в среднем мы потратим 1.76 бита на символ потока.
Т.е. в среднем мы потратим 1.76 бита на символ потока.
Доказательства теоремы, а также того, что построенная схема действительно задает код Хаффмана, заинтересованный читатель найдет в [1.4].
Как стало понятно из изложенного выше, канонический алгоритм Хаффмана требует помещения в файл со сжатыми данными таблицы соответствия кодируемых символов и кодирующих цепочек.
На практике используются его разновидности. Так, в некоторых случаях резонно либо использовать постоянную таблицу, либо строить ее адаптивно, т.е. в процессе архивации/разархивации. Эти приемы избавляют нас от двух проходов по входному блоку и необходимости хранения таблицы вместе с файлом. Кодирование с фиксированной таблицей применяется в качестве последнего этапа архивации в JPEG и в алгоритме CCITT Group, рассмотренных в разделе "Алгоритмы сжатия изображений".
Степени сжатия: 8, 1.5, 1 (лучшая, средняя, худшая степени).
Симметричность по времени: 2:1 (за счет того, что требует двух проходов по массиву сжимаемых данных).
Характерные особенности: Один из немногих алгоритмов, который не увеличивает размера исходных данных в худшем случае (если не считать необходимости хранить таблицу перекодировки вместе с файлом).