Самостоятельная работа 1: Оптимизация вычислительно трудоемкого программного модуля для архитектуры Intel Xeon Phi. Метод Монте-Карло
Перенос алгоритма на Intel Xeon Phi
Прямой перенос базовой версии
Перед тем, как начать выполнение переноса программы на сопроцессор, необходимо обсудить некоторые ее особенности.
Распараллеливание ведется по фотонам, каждый поток обсчитывает свой набор траекторий (./Base/xmcmlLauncher/launcher_omp.cpp):
void LaunchOMP(InputInfo* input, OutputInfo* output,
MCG59* randomGenerator, int numThreads)
{
omp_set_num_threads(numThreads);
…
#pragma omp parallel
{
int threadId = omp_get_thread_num();
InitOutput(input, &(threadOutputs[threadId]));
threadOutputs[threadId].specularReflectance =
specularReflectance;
uint64* trajectory =
new uint64[threadOutputs[threadId].gridSize];
for (uint64 i = threadId;
i < input->numberOfPhotons; i += numThreads)
{
ComputePhoton(specularReflectance, input,
&(threadOutputs[threadId]),
&(randomGenerator[threadId]), trajectory);
}
delete[] trajectory;
}
…
}
Результаты трассировки сохраняются в структуре OutputInfo (./Base/xmcml/mcml_kernel_types.h):
typedef struct __OutputInfo
{
uint64 numberOfPhotons;
double specularReflectance;
uint64* commonTrajectory;
int gridSize;
double* weightInDetector;
DetectorTrajectory* detectorTrajectory;
int numberOfDetectors;
} OutputInfo;
Сохраняются три типа результатов:
- Величина сигнала на детекторе – массив weightInDetector, количество элементов равно числу детекторов (в примере – 10), размер – 80 Б.
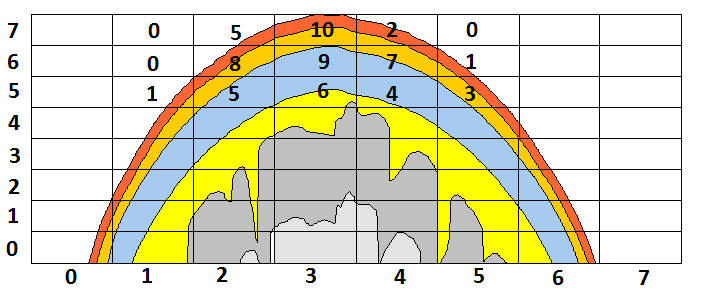
- Общая фотонная карта траекторий – массив commonTrajectory, количество элементов равно числу ячеек сетки ( рис. 3.6) (в примере – 100*100*50=500 000 элементов), размер – 4 МБ.
- Фотонные карты траекторий для каждого детектора – массив detectorTrajectory. Для каждого из детекторов хранится массив, аналогичный commonTrajectory, того же размера. Общий размер данных для 10 детекторов – 40 МБ.
Каждому фотону требуется доступ к массивам результатов для их обновления, а значит необходимо либо использовать синхронный доступ к данным на запись, либо воспользоваться техникой дублирования данных.
В базовой версии программы применяется второй подход: создаются копии результирующих массивов для каждого потока исполнения, а после окончания расчетов данные этих копий суммируются. Применение данной техники позволяет, с одной стороны, избежать затрат на синхронизацию, но, с другой, приводит к дополнительным затратам памяти.
И если для исполнения на центральном процессоре объем дополнительной памяти будет равен 350 МБ при использовании 8 потоков, то для работы на сопроцессоре Intel Xeon Phi с 240 потоками понадобится хранить уже более 10 GB данных.
Еще одна особенность алгоритма состоит в необходимости хранения траектории каждого отдельного фотона в процессе его трассировки. Это связано с тем, что до окончания трассировки фотона узнать, попал ли он в детектор, нельзя. Соответственно, если фотон попал в детектор, траектория его движения суммируется с общей картой траекторий для данного детектора, а если нет – игнорируется.
В базовой версии выделяется массив для хранения траектории для каждого потока. С точки зрения структур данных используется все та же трехмерная сетка, соответственно размер массива равен 4 МБ. Перед началом трассировки каждого отдельного фотона этот массив обнуляется.
Процесс оптимизации программы начнем с выполнения ее прямого переноса на сопроцессор. Для этого скомпилируем программу под Intel Xeon Phi с помощью скрипта mic_make.sh.
Отметим, что для переноса используется режим работы только на сопроцессоре. Выбор этого режима обусловлен отсутствием необходимости модифицировать код для его запуска на Intel MIC. А значит мы можем выполнять оптимизацию и отладку одного и того же кода параллельно на CPU и на сопроцессоре.
Выполнение программы на 8 потоках CPU для моделирования 100 000 фотонов занимает 35 секунды. При запуске в 1 поток это время равно 125 секундам.
Используемый в тестах сопроцессор обладает 8 GB встроенной памяти, поэтому запустить программу в текущей версии в 240 потоков не представляется возможным. Использование же 120 потоков дает время выполнения в 63 секунды. А на 60 потоках Intel Xeon Phi программа работает еще быстрее – 57 секунд.
Таким образом, прямой перенос базовой версии программы позволяет получить производительность на сопроцессоре, вдвое меньшую, чем производительность одного 8-ми ядерного CPU.
Оптимизация 1: обновление структуры данных для хранения траектории фотона в процессе трассировки
Перед началом оптимизации имеет смысл выявить наиболее медленные участки программы. Для этого воспользуемся профилировщиком Intel VTune Amplifier XE. Запустим программу в 4 потока с количеством трассируемых фотонов 20 000. Результаты времени работы функций программы приведены на рис. 3.7.
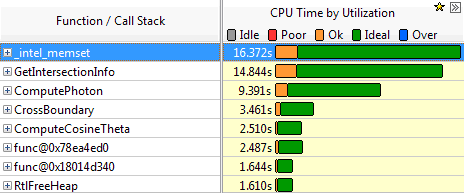
Как видно из графиков, наибольшее время занимает функция memset(). Единственным местом в программе, где она используется, является функция трассировки фотона ComputePhoton() (./Base/xmcml/mcml_kernel.cpp):
void ComputePhoton(double specularReflectance,
InputInfo* input, OutputInfo* output,
MCG59* randomGenerator, uint64* trajectory)
{
PhotonState photon;
int trajectorySize = input->area->partitionNumber.x*
input->area->partitionNumber.y*
input->area->partitionNumber.z;
memset(trajectory, 0, trajectorySize * sizeof(uint64));
…
}
Функция memset() предназначена для того, чтобы обнулять память для хранения текущей траектории фотона перед его трассировкой. Эта память выделяется один раз для каждого потока в начале работы программы. Напомним, что элемент массива trajectory соответствует ячейке трехмерной сетки и хранит количество посещений фотоном данной ячейки. Размер массива для нашего примера равен 100*100*50 элементов или 4 МБ.
Следует отметить, что кроме необходимости обнуления памяти на каждой итерации, данный подход обладает еще несколькими недостатками. А именно, размер массива слишком велик по сравнению с размером L2 кэш памяти, и доступ к элементам массива осуществляется в случайном порядке (в силу случайности траектории фотона).

увеличить изображение
Рис. 3.8. Хранение числа посещений фотоном ячеек сетки в виде списка координат этих ячеек
Для устранения описанных выше недостатков предлагается использовать другую структуру данных для хранения траектории фотона: следует хранить не число посещений данной ячейки для всей сетки, а список координат посещенных ячеек ( рис. 3.8) (./Opt1/xmcml/mcml_kernel_types.h):
#define MAX_TRAJECTORY_SIZE 2048
typedef struct __PhotonTrajectory
{
byte x[MAX_TRAJECTORY_SIZE];
byte y[MAX_TRAJECTORY_SIZE];
byte z[MAX_TRAJECTORY_SIZE];
uint size;
} PhotonTrjectory;
Массивы x, y и z хранят координаты ячеек сетки в трехмерном пространстве, size – текущая длина траектории.
Экспериментальные данные показывают, что максимальная длина траектории фотона в данном примере не превосходит 2048 шагов (эта величина существенно зависит от параметров биотканей и размера сетки). Размер структуры данных в этом случае составляет всего 6 КБ.
Для того чтобы использовать эту новую структуру данных, в программу необходимо внести некоторые изменения.
Во-первых, в функции LaunchOMP() меняем часть, связанную с выделением памяти под траекторию (./Opt1/xmcmlLauncher/launcher_omp.cpp):
void LaunchOMP(InputInfo* input, OutputInfo* output,
MCG59* randomGenerator, int numThreads)
{
…
#pragma omp parallel
{
int threadId = omp_get_thread_num();
InitOutput(input, &(threadOutputs[threadId]));
threadOutputs[threadId].specularReflectance =
specularReflectance;
PhotonTrjectory trajectory;
for (uint64 i = threadId;
i < input->numberOfPhotons; i += numThreads)
{
ComputePhoton(specularReflectance, input,
&(threadOutputs[threadId]),
&(randomGenerator[threadId]), &trajectory);
}
}
…
}
Во-вторых, в функции ComputePhoton() избавляемся от обнуления памяти (./Opt1/xmcml/mcml_kernel.cpp):
void ComputePhoton(double specularReflectance, InputInfo* input, OutputInfo* output,
MCG59* randomGenerator, PhotonTrjectory* trajectory)
{
PhotonState photon;
trajectory->size = 0;
…
}
И в-третьих, необходимо исправить функции работы с траекторией. Исправляем код функции UpdatePhotonTrajectory() (./Opt1/xmcml/mcml_kernel.cpp):
void UpdatePhotonTrajectory(PhotonState* photon, InputInfo* input, OutputInfo* output,
PhotonTrjectory* trajectory, double3 previousPhotonPosition)
{
…
while ((plane <= finishPosition.z) && (plane <
input->area->corner.z + input->area->length.z))
{
double3 intersectionPoint =
GetPlaneSegmentIntersectionPoint(startPosition,
finishPosition, plane);
byte3 areaIndexVector =
GetAreaIndexVector(intersectionPoint,
input->area);
if (areaIndexVector.x == 255 &&
areaIndexVector.y == 255 &&
areaIndexVector.z == 255)
break;
assert(trajectory->size < MAX_TRAJECTORY_SIZE);
trajectory->x[trajectory->size] =
areaIndexVector.x;
trajectory->y[trajectory->size] =
areaIndexVector.y;
trajectory->z[trajectory->size] =
areaIndexVector.z;
++(trajectory->size);
int index = areaIndexVector.x*
input->area->partitionNumber.y*
input->area->partitionNumber.z +
areaIndexVector.y*
input->area->partitionNumber.z +
areaIndexVector.z;
++(output->commonTrajectory[index]);
plane += step;
}
}
Функция assert() используется для генерации ошибки в случае, если реальная длина траектории фотона будет больше, чем размер массива, выделенного под ее хранение. Для использования этой функции следует подключить заголовочный файл "assert.h".
Здесь byte3 – новый тип данных (./Opt1/xmcml/mcml_types.h):
typedef union __byte3
{
struct { int x, y, z; };
struct { int cell[3]; };
} byte3;
Функцию GetAreaIndexVector() также следует добавить (./Opt1/xmcml/mcml_kernel.cpp):
byte3 GetAreaIndexVector(double3 photonPosition,
Area* area)
{
byte3 result;
result.x = 255;
result.y = 255;
result.z = 255;
double indexX = area->partitionNumber.x*
(photonPosition.x - area->corner.x)/area->length.x;
double indexY = area->partitionNumber.y*
(photonPosition.y - area->corner.y)/area->length.y;
double indexZ = area->partitionNumber.z*
(photonPosition.z - area->corner.z)/area->length.z;
bool isPhotonInArea = !((indexX < 0.0 ||
indexX >= area->partitionNumber.x) ||
(indexY < 0.0 || indexY >= area->partitionNumber.y)
|| (indexZ < 0.0 ||
indexZ >= area->partitionNumber.z));
if (isPhotonInArea)
{
result.x = (byte)indexX;
result.y = (byte)indexY;
result.z = (byte)indexZ;
}
return result;
}
И наконец, необходимо полностью обновить функцию UpdateDetectorTrajectory() (./Opt1/xmcml/mcml_kernel.cpp):
void UpdateDetectorTrajectory(OutputInfo* output,
Area* area, PhotonTrjectory* trajectory,
int detectorId)
{
int index;
int ny = area->partitionNumber.y;
int nz = area->partitionNumber.z;
uint64* detectorTrajectory =
output->detectorTrajectory[detectorId].trajectory;
for (int i = 0; i < trajectory->size; ++i)
{
index = trajectory->x[i]*ny*nz +
trajectory->y[i]*nz + trajectory->z[i];
++(detectorTrajectory[index]);
}
++(output->detectorTrajectory[detectorId].
numberOfPhotons);
}Изменение используемой структуры данных позволило сократить время вычислений на CPU в 1 поток до 106 секунд (на 18%). При этом моделирование с использованием 8 потоков CPU стало занимать 32 секунды (ускорение на 9%). Время работы программы на MIC в 60 потоков сократилось до 56, а на 120 – до 48 секунд. Таким образом, описанная выше оптимизация позволила уменьшить время вычислений с использованием сопроцессора на 31%.