Лекция 2: Принципы переноса прикладных программных пакетов на Intel Xeon Phi
Оптимизация 2: улучшение масштабируемости
Помимо векторизации, производительность на Xeon Phi существенно зависит от эффективности масштабируемости приложения. В предыдущих версиях с помощью технологии OpenMP распараллеливался внешний цикл. Количество его итераций слишком мало для эффективного использования Xeon Phi: на рассматриваемом бенчмарке имеется 257 итераций, в зависимости от конфигурации запуска количество потоков составляет от 60 до 240. Таким образом, при некоторых конфигурациях запуска большинство потоков делает лишь одну итерацию внешнего цикла, и малое количество потоков делает две итерации, в то время как остальные простаивают. Параллелизм в данной задаче чрезмерно крупнозернистый (coarse grained) для Xeon Phi. Данная проблема также рассмотрена в [2.3].
Используем стандартную технику уменьшения зернистости параллелизма объединим два внешних цикла в один и будем распараллеливать его. Тогда на рассматриваемом бенчмарке число итераций будет уже достаточно велико. В приводимом ниже коде объединение циклов произведено вручную, его также можно делать автоматически с помощью #pragma omp collapse (2).
void updateE(const Parameters & parameters, double *** bx, double *** by, double *** bz,
double *** ex, double *** ey, double *** ez)
{
const double cx = C * parameters.dt / parameters.dx;
const double cy = C * parameters.dt / parameters.dy;
const double cz = C * parameters.dt / parameters.dz;
const int nz = parameters.nz;
const int numIterations = parameters.nx * parameters.ny;
#pragma omp parallel for
for (int iteration = 0; iteration < numIterations; iteration++)
{
int i = iteration / parameters.ny;
int j = iteration % parameters.ny;
double * ex_ij = ex[i][j];
double * ey_ij = ey[i][j];
double * ez_ij = ez[i][j];
const double * bx_ij = bx[i][j];
const double * bx_ij1 = bx[i][j + 1];
const double * by_ij = by[i][j];
const double * by_i1j = by[i + 1][j];
const double * bz_ij = bz[i][j];
const double * bz_i1j = bz[i + 1][j];
const double * bz_ij1 = bz[i][j + 1];
#pragma simd
for (int k = 0; k < nz; k++)
{
ex_ij[k] += cy * (bz_ij1[k] - bz_ij[k]) -
cz * (by_ij[k + 1] - by_ij[k]);
ey_ij[k] += cz * (bx_ij[k + 1] - bx_ij[k]) -
cx * (bz_i1j[k] - bz_ij[k]);
ez_ij[k] += cx * (by_i1j[k] - by_ij[k]) -
cy * (bx_ij1[k] - bx_ij[k]);
}
}
}
Этот подход позволяет немного увеличить производительность на 8 ядрах CPU и Xeon Phi, данные приведены на рис. 2.4.

Общие результаты оптимизации
В результате проделанных оптимизаций удалось повысить производительность программы для Intel Xeon Phi вдвое, при этом производительность на CPU также увеличилась на 10 30% (в зависимости от количества используемых ядер). При этом лучшая версия на Xeon Phi обгоняет лучшую версию на CPU примерно в 3.3 раза.
Как уже отмечалось, производительность реализации метода FDTD ограничена в первую очередь пропускной способностью памяти. Оценим пропускную способность памяти, достигаемую рассмотренными реализациями. В рассматриваемом бенчмарке используется сетка 256x256x256 и 100 итераций по времени. На каждой итерации выполняется две эквивалентных с точки зрения доступа к памяти операции. Для каждой из операций происходит 15 обращений к памяти (выполнение += приводит к чтению и записи и, поэтому, считается за 2 операции). Таким образом, всего обрабатывается 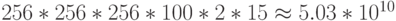 элементов типа double, что составляет 375 ГБ данных. Разделив объем обрабатываемой информации на время выполнения бенчмарка, получаем оценку достигаемой пропускной способности памяти, данные представлены на
рис.
2.5.
элементов типа double, что составляет 375 ГБ данных. Разделив объем обрабатываемой информации на время выполнения бенчмарка, получаем оценку достигаемой пропускной способности памяти, данные представлены на
рис.
2.5.
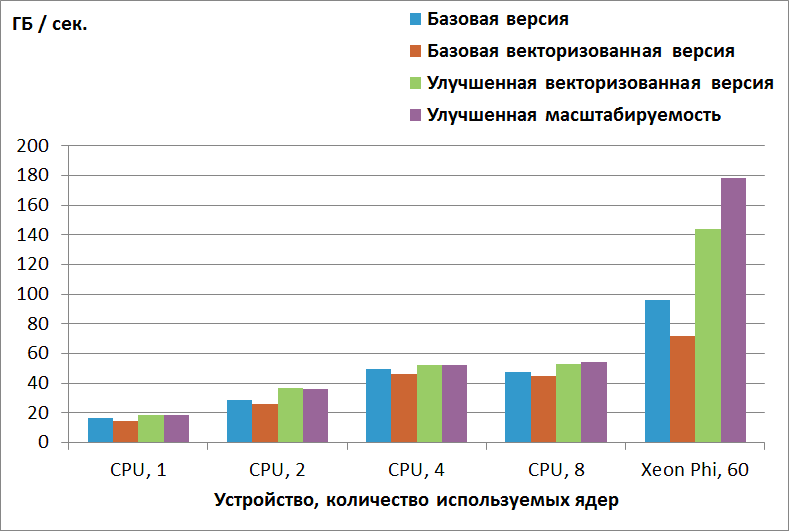
При этом пиковая пропускная способность памяти используемой модели Xeon Phi составляет 352 ГБ / сек., а на каждом из используемых CPU – 53 ГБ / сек. Таким образом, на обоих устройствах достигается примерно половина от пиковой пропускной способности памяти (в запусках на CPU половина потоков работает на одном CPU, а половина – на втором). Большое преимущество Xeon Phi в пропускной способности памяти является основной причиной значительного превосходства Xeon Phi над CPU в данной задаче. Достигнутый результат в 178 ГБ / сек. на Xeon Phi очень близок к результату на бенчмарке для измерения пропускной способности памяти STREAM, представленному в статье http://software.intel.com/en-us/articles/optimizing-memory-bandwidth-on-stream-triad, данная статья также использует конфигурацию запуска 1 поток на ядро.
Авторы выражают благодарность студенту ВМК ННГУ А. Ларину за помощь в проверке некоторых идей по оптимизации.