




| Гамбия |
Инспектор
Спонсор: Microsoft
Вы можете этот курс.
Самостоятельная работа 12:
Создание структуры и модели интеллектуального анализа. Задача кластеризации
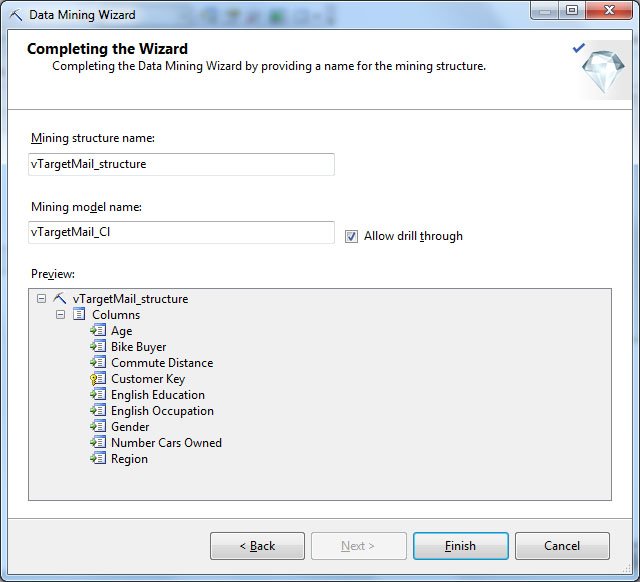
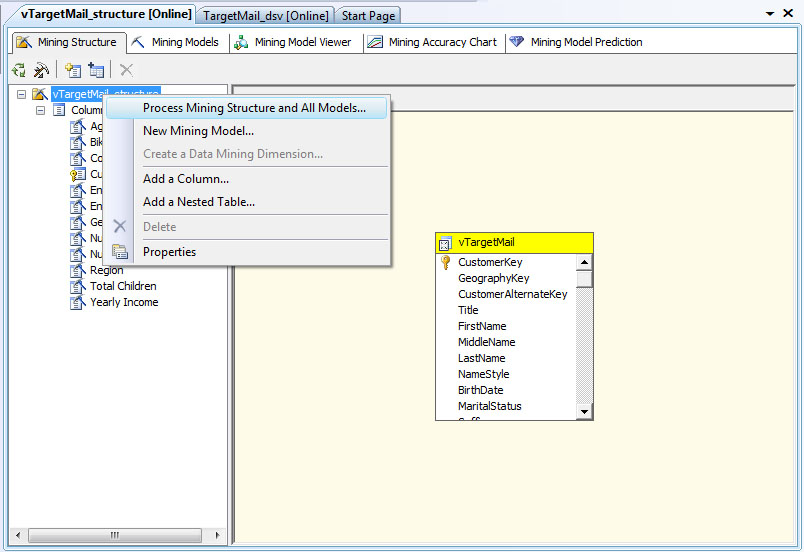
Последнее окно мастера позволяет указать названия для структуры и модели интеллектуального анализа. Предлагаемые по умолчанию названия лучше отредактировать, так чтобы они явно указывали, что это за объект. Например, созданную структуру назовем vTargetMail_structure, а основанную на алгоритме кластеризации модель - vTargetMail_Cl. Установим также флажок "Allowdrillthrough", что позволит проводить детализацию, например, просматривать отдельные записи, относимые к тому или иному кластеру ( рис. 28.9). После чего, т.к. мы работает в режиме immediate, на сервере интеллектуального анализа будут созданы структура и модель. А в среде BIDevStudio будет открыто окно редактора, позволяющее проводить дельнейшую работу с созданными объектами. В частности, из контекстного меню на вкладке MiningStructure можно запустить обработку структуры и всех моделей ( рис. 28.10). В процессе обработки данные будет загружены в структуру и произойдет обучение моделей.
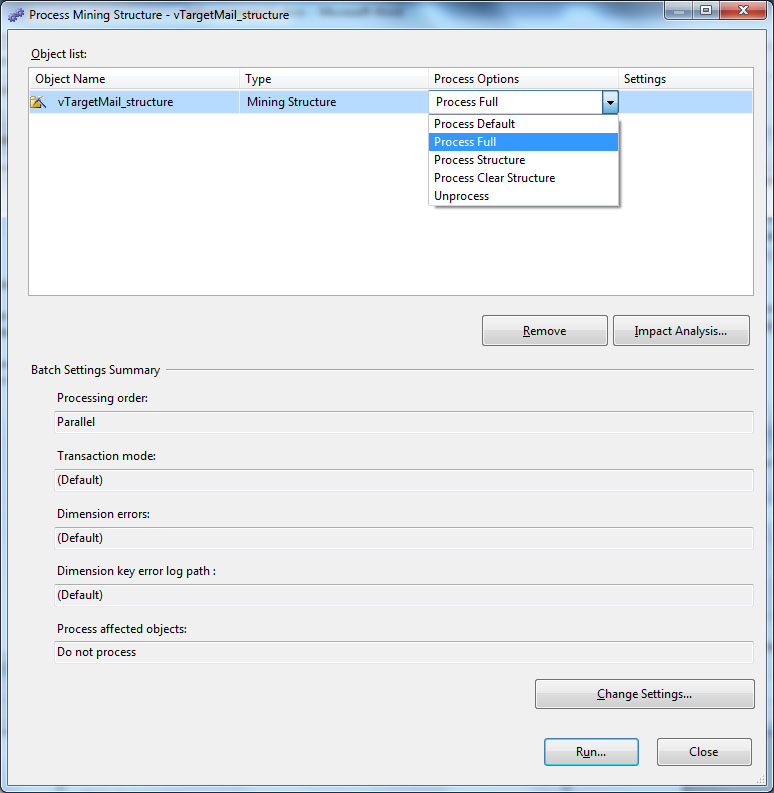
Можно выбрать тип обработки объекта ( рис. 28.11):
| ProcessFull (полная обработка) | объект полностью обрабатывается, для случая структуры происходит обработка структуры и всех ее моделей; |
| ProcessDefault (обработка по умолчанию) | сервер выполняет действия, необходимые для приведения данного объекта в обработанное состояние. Например, если ProcessDefault выполняется для отдельной модели, будет обработана именно эта модель (обработка других моделей, относящихся к структуре проводиться не будет); |
| ProcessStructure (обработка структуры) | может проводиться только для структуры, при этом читаются и кэшируются данные, обработка моделей не производится; |
| ProcessClearStructure(очистка структуры) | использование этой операции в отношении структуры приведет к тому, что кэш структуры будет очищен от исходных данных, но содержащиеся в ней модели сохранятся в обработанном состоянии; |
| Unprocess (отмена обработки) | переводит объект в необработанное состояние; в случаеструктуры, из кэшей будут удалены данные и содержащиеся в структуре модели будут переведены в необработанное состояние. |
Запускаем полную обработку для созданной структуры с настройками по умолчанию. И получаем сообщение об ошибке, что в источнике данных указано значение ImpersonationMode, которое не поддерживается для операций обработки ( рис. 28.12).
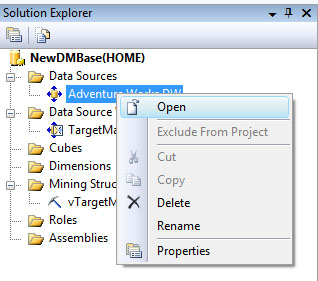
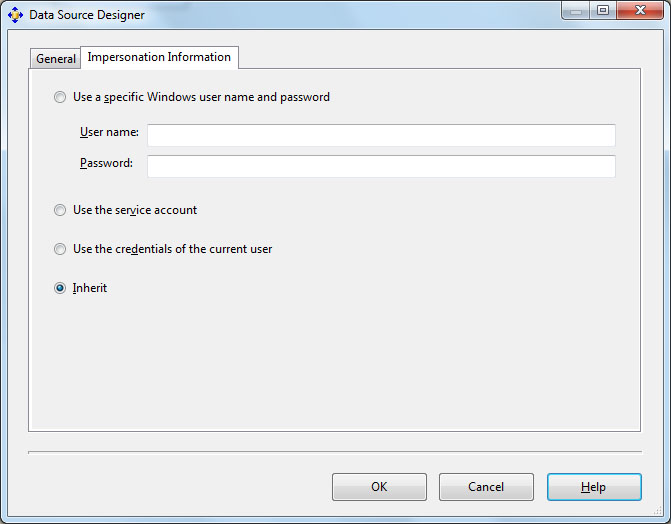
В "Начало работы в BIDevStudio" , посвященной созданию источника данных, отмечалось, что к настройке ImpersonationMode мы еще вернемся. Сделаем это сейчас. Закроем окна с сообщениями об ошибке и окна мастера обработки. В окне SolutionExplorer найдем используемый источник данных и откроем его в редакторе ( рис. 28.13). На вкладке Impersonation Information вместо установленного ранее "Usethecredentialsof the current user" выбираем вариант "Inherit" (наследовать). Как отмечается в справке. В этом варианте будет использоваться различные учетные записи (пользователя, службы) в зависимости от выполняемой операции.
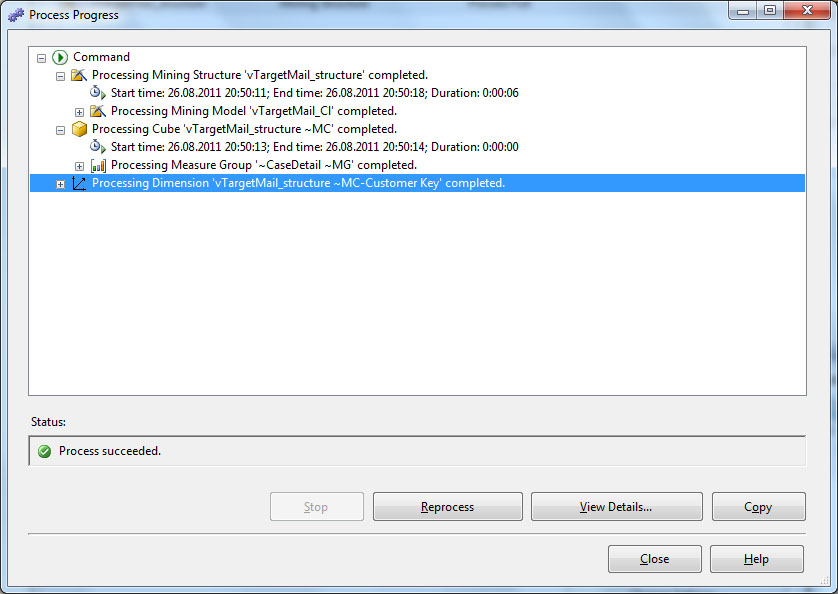
После изменения настройки, повторно запускаем полную обработку структуры, которая сейчас должна завершиться успешно.
Задание1. По аналогии с рассмотренным примером создайте структуру и модель интеллектуального анализа.
После обработки можно открыть в редакторе структуру и на вкладке MiningModelViewer ознакомится с построенной моделью ( рис. 28.16). Инструмент ClusterProfiles ( рис. 28.17) позволяет увидеть характеристики выявленных кластеров. Например, кластер 4 объединяет клиентов старшего возраста (средний возраст около 63 лет), работающих в сфере управления (EnglishOccupation='Management').
Здесь же можно переименовать кластеры, провести детализацию (опция DrillThrough в контекстном меню), чтобы увидеть записи, относимые к каждому кластеру.
Задание2. Ознакомьтесь с результатами кластеризации. Охарактеризуйте полученные кластеры. Посмотрите, все ли добавленные в модель столбцы учитывались в процессе кластеризации или некоторые были проигнорированы (для этого посмотрите данные на вкладке MiningModels).
Получение номера кластера
Теперь рассмотрим, как можно получить список клиентов с идентификаторами присвоенных им кластеров. Для этого можно использовать конструкцию прогнозирующего соединения (PREDICTIONJOIN) и функцию Cluster().
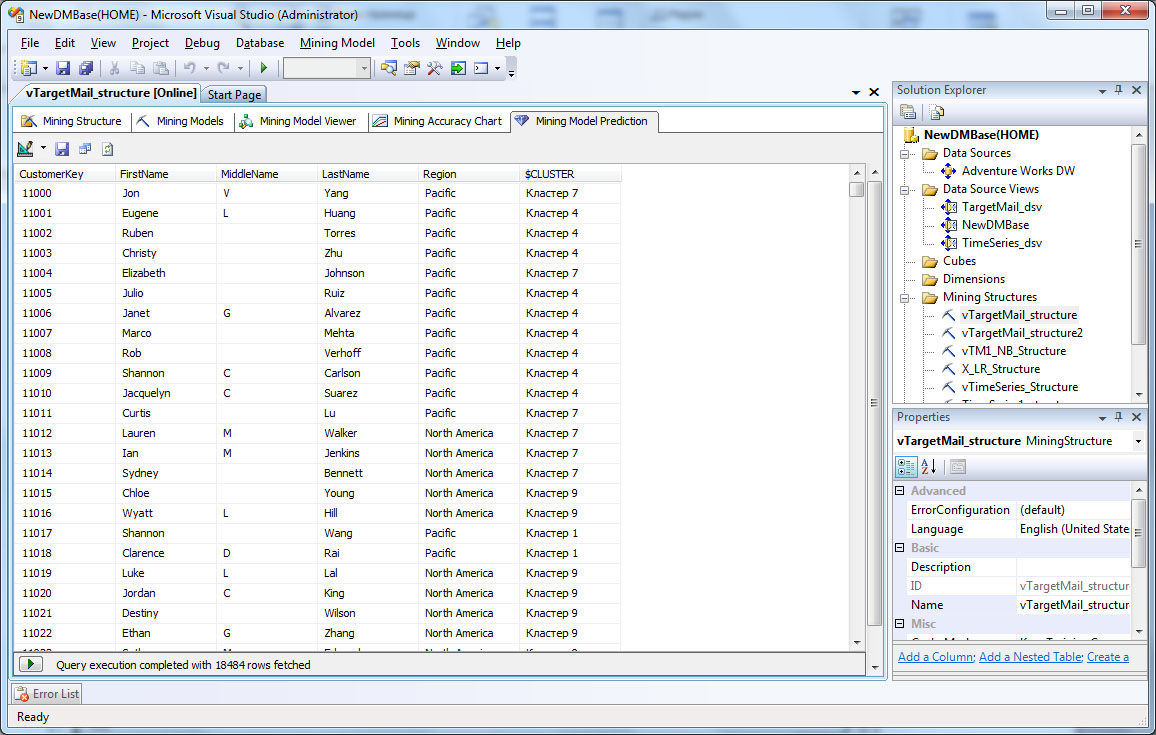
В среде BIDevStudio в окне просмотра модели перейдем на вкладку MiningModelPrediction. В окне SelectInputTables нажмем кнопку SelectCaseTable и укажем откуда брать варианты: представление источника данных TargetMail_dsv и в нем vTargetMail. После этого надо выбрать список отображаемых в результатах запроса атрибутов. Пусть это будет ключ клиента (CustomerKey), его имя, отчество или второе имя и фамилия (FirstName, MiddleName, LastName) и регион проживания (Region). Также нам нужно получить значение функции Cluster ( рис. 28.18). Когда запрос сформирован в конструкторе можно переключиться к представлению результатов (кнопка с изображением таблицы на панели инструментов окна MiningModelPrediction). Результат выполнения прогнозирующего запроса приведен на рис. 28.19, а его код представлен ниже.
SELECT
t.[CustomerKey],
t.[FirstName],
t.[MiddleName],
t.[LastName],
t.[Region],
Cluster()
From
[vTargetMail_Cl]
PREDICTIONJOIN
OPENQUERY([Adventure Works DW],
'SELECT
[CustomerKey],
[FirstName],
[MiddleName],
[LastName],
[Region],
[Gender],
[YearlyIncome],
[TotalChildren],
[NumberChildrenAtHome],
[EnglishEducation],
[EnglishOccupation],
[NumberCarsOwned],
[CommuteDistance],
[Age],
[BikeBuyer]
FROM
[dbo].[vTargetMail]
') AS t
ON
[vTargetMail_Cl].[Gender] = t.[Gender] AND
[vTargetMail_Cl].[Yearly Income] = t.[YearlyIncome] AND
[vTargetMail_Cl].[Total Children] = t.[TotalChildren] AND
[vTargetMail_Cl].[Number Children At Home] = t.[NumberChildrenAtHome] AND
[vTargetMail_Cl].[English Education] = t.[EnglishEducation] AND
[vTargetMail_Cl].[English Occupation] = t.[EnglishOccupation] AND
[vTargetMail_Cl].[Number Cars Owned] = t.[NumberCarsOwned] AND
[vTargetMail_Cl].[Commute Distance] = t.[CommuteDistance] AND
[vTargetMail_Cl].[Region] = t.[Region] AND
[vTargetMail_Cl].[Age] = t.[Age] AND
[vTargetMail_Cl].[Bike Buyer] = t.[BikeBuyer]
Листинг
.
Задание 3. По аналогии с рассмотренным примером, выведите список клиентов с идентификаторами кластеров, к которым их относит модель.
Воспользуйтесь функцией ClusterProbability, чтобы получить оценку вероятности того, что данный вариант находится в указанном кластере.