| Гамбия |
Инспектор
Вы можете этот курс.
Лекция 13:
DMX. Параметры алгоритмов интеллектуального анализа данных. Упрощённый алгоритм Байеса, деревья решений, линейная регрессия
< Самостоятельная работа 11 || Лекция 13 || Лекция 14 >
Аннотация: В данной лекции мы рассмотрим некоторые особенности определения моделей данных, основанных на упрощенном алгоритме Байеса и деревьях принятия решений.
Ключевые слова: DMX, алгоритм, discretization, значение, покупатель, атрибут, тип содержимого, входные данные, MSDN, дерево принятия решений, regressor, параметр
Упрощенный алгоритм Байеса
На предыдущих лекциях мы разбирали формат команд DMX для создания структур и моделей интеллектуального анализа данных. В частности, создать структуру, включающую одну модель можно с помощью следующей команды:
CREATE [SESSION] MINING MODEL <model>
(
[(<column definition list>)]
)
USING <algorithm> [(<parameter list>)] [WITH DRILLTHROUGH]
Если мы создаем модель, использующую упрощенный алгоритм Байеса, то в качестве названия алгоритма надо указать Microsoft_Naive_Bayes. Кроме того надо учитывать следующее:
- тип содержимого для входного атрибута может быть Cyclical, Discrete, Discretized, Key, Table и Ordered, для прогнозируемого - Cyclical, Discrete, Discretized, Table и Ordered; обработка атрибутов типа Continuous (непрерывные) недопускается;
- должен быть определен хотя бы один выходной атрибут;
- алгоритм не поддерживает детализацию, соответственно опция [WITH DRILLTHROUGH] неприменима.
Рассмотрим пример создания модели, прогнозирующей значение атрибута [BikeBuyer] (покупатель велосипеда) на основе значений атрибутов [Age] (возраст), [NumberCarsOwned] (число машин в собственности), ключевой атрибут - [CustomerKey].
CREATE MINING MODEL vTM1_NB (
[Customer Key] LONG KEY,
[Age] LONG DISCRETIZED,
[Number Cars Owned] LONG DISCRETE,
[Bike Buyer] LONG DISCRETE PREDICT_ONLY)
USING Microsoft_Naive_Bayes
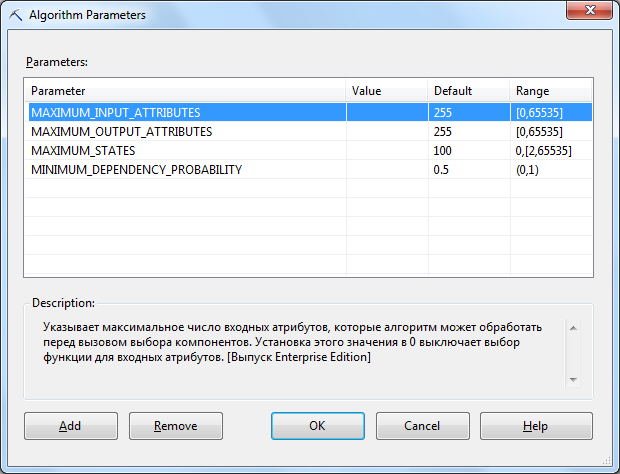
После выполнения данной инструкции будет создана структура vTM1_NB_Structure и модель vTM1_NB с параметрами по умолчанию. Эти параметры приведены на рис. 13.1 (просмотр параметров алгоритма из среды BIDevStudio)
Если значения по умолчанию не устраивают, можно явно казать значения при создании модели или изменить их впоследствии. Ниже приведены описания параметров алгоритма.
| MAXIMUM_INPUT_ATTRIBUTES | указывает максимальное количество входных атрибутов, которые алгоритм может обработать перед вызовом выбора характеристик. Если входов больше, чем это число, алгоритм по выявленным характеристикам отберет самые важные и проигнорирует остальные. Установка этого значения равным 0, отключает выбор характеристик для входных атрибутов, т.е. рассматриваться будут все входные атрибуты. Значение по умолчанию - 255. |
| MAXIMUM_OUTPUT_ATTRIBUTES | аналогично задает максимальное количество выходных атрибутов, которые алгоритм может обработать перед вызовом выбора характеристик. Установка этого значения равным 0 отключает выбор характеристик для выходных атрибутов. Значение по умолчанию равно 255. |
| MINIMUM_DEPENDENCY_PROBABILITY | задает минимальную вероятность зависимости между входными и выходными атрибутами (т.е. "пороговая" вероятность того, что входной атрибут влияет на значение выходного). Это значение используется для ограничения размера содержимого, формируемого алгоритмом. Это свойство может быть установлено равным от 0 до 1. Большие значение уменьшают количество атрибутов в содержимом модели.Значение по умолчанию равно 0,5. |
| MAXIMUM_STATES | указывает максимальное количество состояний атрибутов, поддерживаемое алгоритмом. Если количество состояний атрибутов превышает максимально возможное количество состояний, то алгоритм использует наиболее частые состояния атрибутов и считает остальные состояния отсутствующими.Значение по умолчанию равно 100. |
Деревья решений и линейная регрессия
При использовании языка DMX,создание модели для прогнозирования дискретного атрибута с помощью алгоритма MicrosoftDecisionTrees может выглядеть примерно следующим образом:
CREATE MINING MODEL vTM1_DT (
[Customer Key] LONG KEY,
[Age] LONG CONTINUOUS,
[Number Cars Owned] LONG DISCRETE,
[Bike Buyer] LONG DISCRETE PREDICT_ONLY)
USING Microsoft_Decision_Trees
Обратите внимание, что в отличие от рассмотренного ранее примера создания модели на базе упрощенного алгоритма Байеса, в данном случае допустим тип содержимого Continuous и необязательно проводить дискретизацию "непрерывных" числовых параметров при создании структуры и модели. В то же время надо учитывать, что если прогнозируемый атрибут дискретен, а входные данные непрерывны, вход непрерывных столбцов автоматически дискретизируется [6].
Несколько иначе будет выглядеть создание модели для прогнозирования значений непрерывного атрибута. Здесь алгоритму понадобится использовать независимую переменную-регрессор. Можно это явно указать при создании модели. В приведенном ниже примере мы хотим прогнозировать годовой доход в зависимости от возраста и числа машин. При этом возраст можно явно указать в качестве потенциального регрессора.
CREATEMININGMODELvTM2_DT (
[CustomerKey] LONGKEY,
[Age] LONGREGRESSORCONTINUOUS,
[NumberCarsOwned] LONGDISCRETE,
[Yearly Income] LONG CONTINUOUS PREDICT_ONLY)
USING Microsoft_Decision_Trees
В то же время, как отмечается в MSDN, если столбец указан как регрессор, это не значит, что он будет использован в этом качестве в окончательной модели. И наоборот, алгоритм дерева принятия решений секционирует набор данных на области со значимыми шаблонами, даже если для столбца не задан флаг REGRESSOR.
Можно применить параметр модели FORCED_REGRESSOR для обеспечения того, чтобы использовался конкретный регрессор. Этот параметр может применяться с алгоритмом дерева принятия решений и алгоритмом линейной регрессии.
И раз уж речь зашла об алгоритме линейной регрессии рассмотрим, как создать соответствующую модель.
CREATE MINING MODEL X_LR(
[ID] LONG KEY,
[X] LONG REGRESSOR CONTINUOUS,
[Y] LONG CONTINUOUS PREDICT)
USING Microsoft_Linear_Regression
Как мы разбирали в "Надстройки интеллектуального анализа данных для MicrosoftOffice" , алгоритма линейной регрессии приводит к использованию особого варианта алгоритма дерева решений с параметрами, которые ограничивают поведение алгоритма и требуют использования определенных типов данных на входе. К требованиям в частности относятся:
- Каждая модель должна содержать один числовой или текстовый столбец, который однозначно идентифицирует каждую запись (тип key). Составные ключи не допускаются.
- Необходимо наличие как минимум одного прогнозируемого столбца. В модель можно включить несколько прогнозируемых атрибутов, однако они должны иметь непрерывные числовые типы данных. Тип данных datetime нельзя использовать в качестве прогнозируемого атрибута даже в случае, если собственный формат хранения данных является числовым.
- Во входных столбцах должны содержаться непрерывные числовые данные; кроме того, они должны иметь подходящий тип.
Теперь перейдем к рассмотрению возможных параметров моделей деревьев решений и линейной регрессии, которые можно использовать для "тонкой настройки" алгоритма.
< Самостоятельная работа 11 || Лекция 13 || Лекция 14 >