Инспектор
Вы можете этот курс.
Опубликован: 06.08.2007 | Уровень: профессионал | Доступ: платный
Лекция 8: Организация таблиц символов
Аннотация: В данной лекции рассматривается организация таблиц символов. Рассмaтриваются некоторые основные способы организации таблиц символов в компиляторе: таблицы идентификаторов, таблицы расстановки, двоичные деревья и реализация блочной структуры. Приведены также примеры программного кода и графическая интерпретация таблиц символов и идентификаторов.
Ключевые слова: компилятор, информация, поиск, память, поле, конфликт имен, функция расстановки, список поиска, ориентированное дерево, лексикографический порядок, антирефлексивность, список свободной памяти
В процессе работы компилятор хранит информацию об объектах программы в специальных таблицах символов. Как правило, информация о каждом объекте состоит из двух основных элементов: имени объекта и описания объекта. Информация об объектах программы должна быть организована таким образом, чтобы поиск ее был по возможности быстрее, а требуемая память по возможности меньше.
Кроме того, со стороны языка программирования могут быть дополнительные требования к организации информации. Имена могут иметь определенную область видимости. Например, поле записи должно быть уникально в пределах структуры (или уровня структуры), но может совпадать с именем объекта вне записи (или другого уровня записи). В то же время имя поля может открываться оператором присоединения, и тогда может возникнуть конфликт имен (или неоднозначность в трактовке имени). Если язык имеет блочную структуру, то необходимо обеспечить такой способ хранения информации, чтобы, во-первых, поддерживать блочный механизм видимости, а во-вторых - эффективно освобождать память при выходе из блока. В некоторых языках (например, Аде) одновременно (в одном блоке) могут быть видимы несколько объектов с одним именем, в других такая ситуация недопустима.
Мы рассмотрим некоторые основные способы организации таблиц символов в компиляторе: таблицы идентификаторов, таблицы расстановки, двоичные деревья и реализацию блочной структуры.
Таблицы идентификаторов
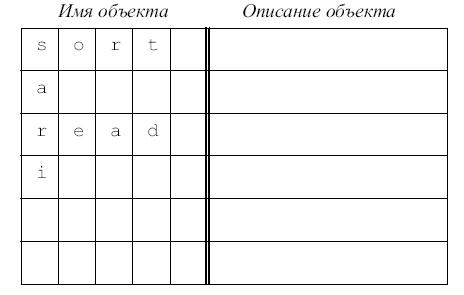
Как уже было сказано, информацию об объекте обычно можно разделить на две части: имя (идентификатор) и описание. Если длина идентификатора ограничена (или имя идентифицируется по ограниченному числу первых символов идентификатора), то таблица символов может быть организована в виде простого массива строк фиксированной длины, как это изображено на рис. 7.1. Некоторые входы могут быть заняты, некоторые - свободны.
Ясно, что, во-первых, размер массива должен быть не меньше числа идентификаторов, которые могут реально появиться в программе (в противном случае возникает переполнение таблицы); во-вторых, как правило, потенциальное число различных идентификаторов существенно больше размера таблицы.
Заметим, что в большинстве языков программирования символьное представление идентификатора может иметь произвольную длину. Кроме того, различные объекты в одной или в разных областях видимости могут иметь одинаковые имена, и нет большого смысла занимать память для повторного хранения идентификатора. Таким образом, удобно имя объекта и его описание хранить по отдельности. В этом случае идентификаторы хранятся в отдельной таблице - таблице идентификаторов. В таблице символов же хранится указатель на соответствующий вход в таблицу идентификаторов. Таблицу идентификаторов можно организовать, например, в виде сплошного массива. Идентификатор в массиве заканчивается каким-либо специальным символом EOS ( рис. 7.2). Второй возможный

вариант - в качестве первого символа идентификатора в массив заносится его длина.
Таблицы расстановки
Одним из эффективных способов организации таблицы символов является таблица расстановки (или хеш-таблица ). Поиск в такой таблице может быть организован методом повторной расстановки. Суть его заключается в следующем.
Таблица символов представляет собой массив фиксированного размера N. Идентификаторы могут храниться как в самой таблице символов, так и в отдельной таблице идентификаторов.
Определим некоторую функцию h1 (первичную функцию расстановки), определенную на множестве идентификаторов и принимающую значения от 0 до N - 1 (то есть 0 <= h1(id) <= N - 1, где id - символьное представление идентификатора). Таким образом, функция расстановки сопоставляет идентификатору некоторый адрес в таблице символов.
Пусть мы хотим найти в таблице идентификатор id. Если элемент таблицы с номером h1(id) не заполнен, то это означает, что идентификатора в таблице нет. Если же занят, то это еще не означает, что идентификатор id в таблицу занесен, поскольку (вообще говоря) много идентификаторов могут иметь одно и то же значение функции расстановки. Для того чтобы определить, нашли ли мы нужный идентификатор, сравниваем id с элементом таблицы h1(id). Если они равны - идентификатор найден, если нет - надо продолжать поиск дальше.
Для этого вычисляется вторичная функция расстановки h2(h) (значением которой опять таки является некоторый адрес в таблице символов). Возможны четыре варианта:
- элемент таблицы не заполнен (то есть идентификатора в таблице нет),
- идентификатор элемента таблицы совпадает с искомым (то есть идентификатор найден),
- адрес элемента совпадает с уже просмотренным (то есть таблица вся просмотрена и идентификатора нет)
- предыдущие варианты не выполняются, так что необходимо продолжать поиск.
Для продолжения поиска применяется следующая функция расстановки h3(h2), h4(h3) и т.д. Как правило, hi = h2 для i >= 2. Аргументом функции h2 является целое в диапазоне [0, N - 1] и она может быть быть устроена по-разному. Приведем три варианта.
- h2(i) = (i + 1) mod N. Берется следующий (циклически) элемент массива. Этот вариант плох тем, что занятые элементы "группируются" , образуют последовательные занятые участки и в пределах этого участка поиск становится по-существу линейным.
- h2(i) = (i + k) mod N, где k и N взаимно просты. По-существу это предыдущий вариант, но элементы накапливаются не в последовательных элементах, а "разносятся".
- h2(i) = (a * i + c) mod N - "псевдослучайная последовательность". Здесь c и N должны быть взаимно просты, b = a-1 кратно p для любого простого p, являщегося делителем N, b кратно 4, если N кратно 4 [6].
Поиск в таблице расстановки можно описать следующей функцией:
void Search(String Id,boolean * Yes,int * Point)
{int H0=h1(Id), H=H0;
while (1)
{if (Empty(H)==NULL)
{*Yes=false;
*Point=H;
return;
}
else if (IdComp(H,Id)==0)
{*Yes=true;
*Point=H;
return;
}
else H=h2(H);
if (H==H0)
{*Yes=false;
*Point=NULL;
return;
}
}
}Функция IdComp(H,Id) сравнивает элемент таблицы на входе H с идентификатором и вырабатывает 0, если они равны. Функция Empty(H) вырабатывает NULL, если вход H пуст. Функция Search присваивает параметрам Yes и Pointer соответственно следующие значения :
true, P - если нашли требуемый идентификатор, где P - указатель на соответствующий этому идентификатору вход в таблице,
false, NULL - если искомый идентификатор не найден, причем в таблице нет свободного места, и
false, P - если искомый идентификатор не найден, но в таблице есть свободный вход P.
Занесение элемента в таблицу можно осуществить следующей функцией:
int Insert(String Id)
{boolean Yes;
int Point=-1;
Search(Id,&Yes,&Point);
if (!Yes && (Point!=NULL)) InsertId(Point,Id);
return(Point);
}Здесь функция InsertId(Point,Id) заносит идентификатор Id для входа Point таблицы.