
| Россия |
Инспектор
Вы можете этот курс.
Опубликован: 25.12.2006 | Уровень: специалист | Доступ: платный
Лекция 1:
Введение. Компьютеры и Мозг
Символы и образы, алгоритмы и обучение
Трудности современной схемотехники
Главное отличительное свойство образов - большая информационная насыщенность, или, выражаясь языком электротехники, широкополосность информации. Иными словами, образ характеризуется числом бит на порядки превосходящим информационную размерность символа. Сравните 32-64-разрядные машинные слова современных ЭВМ и графические образы, характеризуемые мегабайтами информации. При этом, образ является единым информационным объектом. Многие его атрибуты (например, связность областей) являются глобальными - их нельзя вычленить, обрабатывая отдельные части образа независимо.
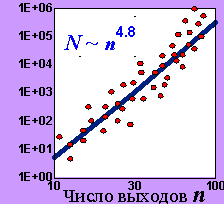
Можно, конечно, обрабатывать образы последовательно, шаг за шагом, небольшими порциями - символами, как это до сих пор и делают компьютеры. Машинные слова современных процессоров имеют размерности от 16 до 64. Однако, это с неизбежностью замедляет вычисления. Повышение параллелизма за счет увеличения разрядности универсальных процессоров идет медленно и с большим трудом, т.к. сопровождается резким усложнением их структуры. Согласно эмпирическому закону Рента, число элементов современных электронных схем, оперирующих n-разрядной информацией растет как n4.8 (см. рис. 1.4).
Очевидно, что эта тенденция, распространенная на размерность n>100, приводит к нереалистичным размерам электронных схем. Следовательно, коренное увеличение быстродействия, требуемое для обработки образов в реальном времени, должно сопровождаться не менее коренным изменением схемотехники. Должны появиться специализированные процессоры образов, построенные на новых принципах, отличных от используемых в универсальных компьютерах.
Специфика этого нового поколения процессоров диктуется самой природой образной информации - ее широкополосностью.
Специфика образной информации
Широкополосность образов имеет далеко идущие последствия. Пусть компьютер манипулирует n-разрядными символами. Количество информации,
требуемое для описания произвольного преобразования таких символов составляет 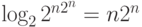 бит. Иными словами, для описания произвольного алгоритма обработки n-разрядных символов потребуется 2n таких символов.
Это типичный пример "комбинаторного взрыва".
бит. Иными словами, для описания произвольного алгоритма обработки n-разрядных символов потребуется 2n таких символов.
Это типичный пример "комбинаторного взрыва".
| Разрядность n машинных слов | Длина произвольного алгоритма |
|---|---|
| 8 | 256B |
| 16 | 128KB |
| 32 | 16GB |
| ... | ... |
| 1024 | 21000B |
Отсюда и следует качественное различие обработки символьной (малоразрядной) и образной (многоразрядной) информации. Для символов в принципе возможно описать любой способ их обработки. Для образов это в принципе невозможно. Естественно, существуют относительно тривиальные преобразования образов, поддающиеся формализации, т.е. имеющие компактное описание. На таких операциях построены графические ускорители и программные пакеты обработки изображений. Однако, в общем случае операции с образами неформализуемы. Преобразование образов, следовательно, должно основываться на алгоритмах, описанных лишь частично.
Для таких неформализуемых задач частичным описанием алгоритма является некое подмножеством полной таблицы преобразований - множество примеров, или обучающее множество. Возникает новый класс задач - восстановления алгоритма по набору примеров, обучения на примерах.
Процессоры образов должны обладать способностью обобщения конечного числа примеров на потенциально необозримое множество возможных ситуаций, иными словами, способностью предсказуемого поведения в новых ситуациях. В этом своем качестве они противоположны обычным компьютером, где алгоритм в явном виде задает поведение во всех мыслимых ситуациях.
Итак, возникает новая парадигма вычислительных машин: алгоритмы, порождаемые данными в универсальном процессе обучения, специализированные для данного класса операций с образами, адаптированные под конкретные информационные задачи. Это - естественный путь развития вычислительной техники, который обеспечивает одновременно и универсальность и простоту архитектуры таких универсальных спец-процессоров.
Нейрокомпьютеры
Нейрокомпьютинг, как Вы уже догадались, как раз и является описанной выше новой парадигмой вычислительных систем. Основная задача нейрокомпьютеров - обработка образов, основанная на обучении - та же, что и у биологических нейросистем. Подобно биологическим, искусственные нейросети нацелены на параллельную обработку широкополосных образов. В новой схемотехнике, как и в мозгу, остутствуют общие шины, нет разделения на активный процессор и пассивную память. Вычисления, как и обучение, распределены по всем активным элементам - нейронам, каждый из которых есть элементарный процессор образов, т.к. производит хотя и простейшую операцию, но сразу над большим количеством входов. Как вычисления, так и обучение полностью параллельны. В этом сила природных нейрокомпьютеров. Это дает возможность решать задачи, непосильные даже самым мощным суперкомпьютерам, несмотря на миллионнократную разницу в быстродействии элементной базы.
Перспективы нейрокомпьютинга
Вписав появление нейрокомпьютинга в общий процесс эволюции компьютеров, мы получаем возможность заглянуть в ближайшее будущее - экстраполируя сегодняшние тенденции.
Вездесущие умные нейрочипы
Сегодняшний нейрокомпьютинг проходит "обкатку", в основном, в программном продукте для задач ассоциативной обработки данных, редко используя при этом свой "параллельный" потенциал. Такие приложения как раз и являются основной темой данной книги. Эпоха истинного - параллельного - нейрокомпьютинга начнется с выходом на рынок широкого ассортимента аппаратных средств - специализированных нейрочипов для обработки изображений, речи и прочей сенсорной информации. Можно представить себе, например, дверные замки, распознающие хозяина по виду, голосу, и быть может, запаху в совокупности. Системы жизнеобеспечения жилищ станут адаптивными и обучаемыми. Все бытовые приборы поумнеют и приобретут способность угадывать, что от них требуется именно в данный момент. Провозвестником таких изменений можно считать нейросетевой блок адаптивного управления в недавно появившемся пылесосе фирмы Samsung.
Сенсорные датчики приобретут способность реагировать, а регулирующие системы - ощущать. Умные контроллеры, распознающие потенциально опасные ситуации и умеющие принимать адекватные превентивные решения, получат распространение в сложных электрических и тепловых сетях. На них будут основываться системы регулирования транспортными потоками и потоками данных в компьютерных сетях и сотовой связи.
Операционные системы будущего
Однако, наибольшие изменения, коснутся, по-видимому, самих компьютеров. По мнению Билла Гейтса, главы небезызвестной Microsoft, высказанному им на собрании совета директоров, через 10 лет 90% операционной системы будет занято решением задач распознавания образов. Таким образом, при проектировании будущих поколений компьютеров нейрокомпьютинг выдвигается на первый план.
Можно даже представить себе примерный сценарий проникновения нейросистем в компьютеры будущего, связанный с развитием глобальной сети Internet. Сейчас именно она направляет развитие компьютерных систем, постепенно превращая разрозненную сеть персоналок, рабочих станций и мэйнфреймов в единый мировой сетевой компьютер с неограниченными информационными ресурсами. Известная фирма Forrester Research, занимающаяся прогнозированием рынков, оценивает рынок услуг, связанных с Internet, в 2001 году на уровне $350 млрд. Практически все крупные компьютерные фирмы уже включились в борьбу за этот гигантский потенциальный рынок. Достаточно упомянуть ту же Microsoft, тратящую по $100 млн. в год только на исследования, связанные с Internet.
И подобно тому, как эпоха великих открытий XV века стимулировала развитие астрономии и точной механики для совершенствования навигационных приборов, освоение нового - информационного - океана требует развития новых средств навигации - ассоциативного поиска, создания адаптивных и автономных агентов. (Уже сейчас индексация Сети ведется автономными роботами.) Вспомним, каким мощным стимулом развития персональных ЭВМ был удобный графический интерфейс пользователя. Новый интерфейс пользователя для работы в Сети будет основываться на агентах, представляющих интересы пользователя в сети. Этот новый вид программного обеспечения, получивший название agentware, претендует на центральное место в будущей системе человеко-машинного общения. Между тем, первые экземпляры agentware уже появились на рынке, и что характерно, многие основаны на технологии нейросетей (см., например, http://f.agentware.com). Это, по-видимому, сегодня кратчайший путь к созданию легко обучаемых автономных электронных секретарей. Естественно предположить, что именно на этом направлении, в силу его стратегической важности, в ближайшем будущем будет достигнут наибольший прогресс.
Видимо, искусственный интеллект, о котором так долго говорили и спорили, начнет, наконец, материализовываться в этих пока что очень примитивных нейро-агентах. Вскоре электронные агенты вынуждены будут вступить в общение не только со своим хозяином и пассивными данными, но и с другими такими же агентами. В Сети возникнет новый социум с новыми правилами отношений. Разум же и личность, напомним, - понятия социальные. Агенты, учащиеся принимать решения от лица пользователя в социальном окружении, неизбежно приобретут все атрибуты личности.
Но это в будущем. Современный же нейрокомпьютинг - только первая ласточка. В наше время эта технология распознавания ситуаций и принятия решений отрабатывается в конкретных, четко очерченных областях (например, игра на бирже), не требующих знания социального контекста, пока недоступного компьютерам. До принятия действительно значимых управленческих решений нейрокомпьютерами еще очень далеко. Но дорогу осилит идущий.