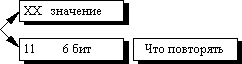

| Россия, г. Смоленск ул. Николаева д. 19а кв. 56 |
Инспектор
Вы можете этот курс.
Опубликован: 10.10.2007 | Уровень: профессионал | Доступ: платный | ВУЗ: Московский государственный университет имени М.В.Ломоносова
Лекция 5:
Алгоритмы архивации без потерь
Аннотация: В этой лекции речь пойдет об алгоритмах группового кодирования, их достоинствах и недостатках, сферах применения, а также будут даны примеры их использования в популярных форматах цифрового изображения
Ключевые слова: run-length encoding, RLE, архивация, counter, PCX, максимальная степень, TIFF, TGA, алгоритм, байт, потоки данных, подстрока, размер файла, подцепочка, переполнение, LZW, хэш-таблица, хэш-функция, логические операции, исключающее ИЛИ, ARJ, GIF, Архиватор, CCITT, e-consulting, intern, telephone, регулярное выражение, префиксный код, код завершения, пропускная способность, IBM, когерентность
Алгоритм RLE
Первый вариант алгоритма
Данный алгоритм необычайно прост в реализации. Групповое кодирование - от английского Run Length Encoding (RLE) - один из самых старых и самых простых алгоритмов архивации графики. Изображение в нем (как и в нескольких алгоритмах, описанных ниже) вытягивается в цепочку байт по строкам растра. Само сжатие в RLE происходит за счет того, что в исходном изображении встречаются цепочки одинаковых байт. Замена их на пары <счетчик повторений, значение> уменьшает избыточность данных.
Алгоритм декомпрессии при этом выглядит так:
Initialization(...);
do {
byte = ImageFile.ReadNextByte();
if(является счетчиком(byte)) {
counter = Low6bits(byte)+1;
value = ImageFile.ReadNextByte();
for(i=1 to counter) DecompressedFile.WriteByte(value)
}
else {
DecompressedFile.WriteByte(byte)
}
while(!ImageFile.EOF());В данном алгоритме признаком счетчика ( counter ) служат единицы в двух верхних битах считанного файла (рис. 5.1):
Соответственно оставшиеся 6 бит расходуются на счетчик, который может принимать значения от 1 до 64. Строку из 64 повторяющихся байтов мы превращаем в два байта, т.е. сожмем в 32 раза.
Алгоритм рассчитан на деловую графику - изображения с большими областями повторяющегося цвета. Ситуация, когда файл увеличивается, для этого простого алгоритма не так уж редка. Ее можно легко получить, применяя групповое кодирование к обработанным цветным фотографиям. Для того, чтобы увеличить изображение в два раза, его надо применить к изображению, в котором значения всех пикселов больше двоичного 11000000 и подряд попарно не повторяются.
Упражнение: Предложите два-три примера "плохих" изображений для алгоритма RLE. Объясните, почему размер сжатого файла больше размера исходного файла.
Данный алгоритм реализован в формате PCX. См. пример в приложении.
Второй вариант алгоритма
Второй вариант этого алгоритма имеет большую максимальную степень сжатия и меньше увеличивает в размерах исходный файл.
Алгоритм декомпрессии для него выглядит так:
Initialization(...);
do {
byte = ImageFile.ReadNextByte();
counter = Low7bits(byte)+1;
if(если признак повтора(byte)) {
value = ImageFile.ReadNextByte();
for (i=1 to counter) CompressedFile.WriteByte(value)
}
else {
for(i=1 to counter){
value = ImageFile.ReadNextByte();
CompressedFile.WriteByte(value)
}
}
while(!ImageFile.EOF());Признаком повтора в данном алгоритме является единица в старшем разряде соответствующего байта (рис. 5.2):
Как можно легко подсчитать, в лучшем случае этот алгоритм сжимает файл в 64 раза (а не в 32 раза, как в предыдущем варианте), в худшем увеличивает на 1/128. Средние показатели степени компрессии данного алгоритма находятся на уровне показателей первого варианта.
Похожие схемы компрессии использованы в качестве одного из алгоритмов, поддерживаемых форматом TIFF, а также в формате TGA.
Характеристики алгоритма RLE:
Степени сжатия: Первый вариант: 32, 2, 0,5. Второй вариант: 64, 3, 128/129. (Лучшая, средняя, худшая степени)
Класс изображений: Ориентирован алгоритм на изображения с небольшим количеством цветов: деловую и научную графику.
Симметричность: Примерно единица.
Характерные особенности: К положительным сторонам алгоритма, пожалуй, можно отнести только то, что он не требует дополнительной памяти при архивации и разархивации, а также быстро работает. Интересная особенность группового кодирования состоит в том, что степень архивации для некоторых изображений может быть существенно повышена всего лишь за счет изменения порядка цветов в палитре изображения.