
|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Инспектор
Спонсор: Intel
Вы можете этот курс.
Опубликован: 30.05.2014 | Уровень: для всех | Доступ: платный | ВУЗ: Нижегородский государственный университет им. Н.И.Лобачевского
Лекция 5: Элементы оптимизации прикладных программ для Intel Xeon Phi. Intel C/C++ Compiler
Векторизация
В этом разделе рассматриваются возможности векторизации приложений с использованием Intel C/C++ Compiler. Информация, представленная в данном разделе, актуальна для всех моделей программирования на сопроцессоре, а также применима при программировании на обычном CPU.
Для того чтобы приложение эффективно использовало вычислительные возможности сопроцессора Intel Xeon Phi, необходимо выполнение двух важных условий: приложение должно обладать высокой степенью параллельности, а так же иметь возможности для векторизации своего кода.
Рассмотрим простой пример:
float *restrict A, *B, *C;
for (int i = 0; i < n; ++i)
{
A[i] = B[i] + C[i];
}
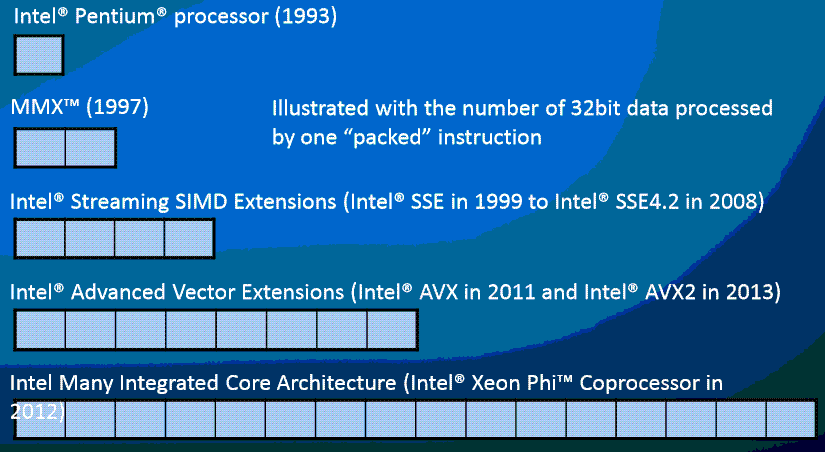
При исполнении такого кода в скалярном виде процессор будет выполнять одно сложение за такт и потратит на этот участок n тактов. В то же время современный процессор с поддержкой SSE может за такт выполнить 4 сложения, с поддержкой AVX – 8, а сопроцессор Intel Xeon Phi – 16 ( рис. 5.5). А это означает, что если такой код будет скомпилирован с использованием векторных инструкций процессора, то он может быть выполнен в несколько раз быстрее.
Каким образом можно сделать свой код векторным, используя компилятор компании Intel? Существует несколько вариантов:
- В некоторых простых случаях компилятор может сам векторизовать ваш код, дополнительно ему можно давать рекомендации;
- Можно использовать возможности параллельного расширения Intel Cilk Plus (SIMD директивы, элементарные функции и специальную технологию Array Notation для массивов) для самостоятельной векторизации кода;
- Можно воспользоваться библиотеками с уже векторизованным кодом, например, Intel MKL. Следует, однако, понимать, что использование подобных библиотек не всегда приводит к ускорению вашего кода.
- Можно использовать язык ассемблера с векторными инструкциями для оптимизации критичных участков кода, либо, что более удобно, оболочки этих инструкций в виде функций языка Си (intrinsics). Существуют также библиотеки классов SIMD, которые являются, по сути, надстройкой более высокого уровня над векторными командами процессора.
В данной лекции будут рассмотрены только две первые возможности - автоматическая векторизация и применение возможностей Intel Cilk Plus.
Автоматическая векторизация
Как уже отмечалось выше, для векторизации вашего кода можно не предпринимать никаких действий и довериться компилятору. Компилятор Intel по умолчанию ищет участки кода, которые можно и имеет смысл векторизовать. Это допустимый подход в тех случаях, когда вы не уверены в эффективности векторизации или у вас просто нет времени вносить изменения в значительную часть исходного кода.
Рассмотрим процесс векторизации более подробно. В качестве примера возьмем следующий код:
for(i=0;i<*p;i++)
{
A[i] = B[i]*C[i];
sum = sum + A[i];
}
Перед тем, как выполнить автоматическую векторизацию кода, компилятор пытается проверить выполнение следующих условий:
- *p является инвариантом цикла;
- A, B и C являются инвариантами цикла;
- A[] не является другим именем для B[], C[] и/или sum (нет перекрытия по памяти между этими данными);
- sum не является другим именем для B[] и/или C[] (нет перекрытия по памяти между этими данными);
- операция "+" является ассоциативной;
- ожидается ускорение векторной версии данного кода по отношению к скалярной.
Если ответ на все эти вопросы положителен, тогда компилятор выполняет автоматическую векторизацию. Однако компилятор не всегда может дать однозначно положительный ответ на один или несколько подобных вопросов в силу сложности участка кода. И в этом случае программист может помочь компилятору принять правильное решение.
Например, для компилятора часто сложным является ответ на вопрос о том, что массив A[] не перекрываются с массивами B[] и C[]. Для того чтобы отразить это в синтаксисе языка, можно объявить указатель A с ключевым словом restrict:
float* restrict A;
Такое объявление говорит компилятору о том, что массив A[] не перекрывается с другими массивами.
Вопрос определения инвариантов цикла для компилятора тоже не тривиален. По умолчанию если компилятор не может принять решения о том, является ли та или иная переменная является инвариантом, он считает ее не инвариантом, тем самым обеспечивая корректность кода. Однако и векторизацию такого цикла компилятор выполнить не может. Для того чтобы сказать компилятору об отсутствии зависимостей в цикле, используется директива #pragma ivdep перед телом цикла:
#pragma ivdep
for(i=0; i < *p; i++)
{
A[i] = B[i]*C[i];
sum = sum + A[i];
}
Директива ivdep дает команду компилятору игнорировать недоказанные зависимости. Однако если компилятор нашел и доказал зависимость, то векторизации цикла даже с этой директивой не произойдет.
Отметим, что данная директива поддерживаются и языком Fortran, где имеет вид !dir$ ivdep.
Использование директивы SIMD
Векторизация с помощью директивы #pragma simd дополняет автоматическую векторизацию так же, как распараллеливание с помощью #pragma omp дополняет автораспараллеливание. По сути, директивы simd и omp являются прямыми аналогами, позволяя выполнить векторизацию и распараллеливание вручную. При этом корректность работы программы в обоих случая не гарантируется и должна обеспечиваться разработчиком.
Пример использования директивы simd приведен ниже [5.3]:
void add_floats(float *a, float *b, float *c, float *d, float *e, int n){
int i;
#pragma simd
for (i=0; i<n; i++){
a[i] = a[i] + b[i] + c[i] + d[i] + e[i];
}
}
Как и #pragma omp, директива simd может содержать дополнительные параметры, посредством которых можно сообщить компилятору о том, как корректно и эффективно векторизовать данный участок кода. Полное описание директивы содержится в соответствующем разделе документации по компилятору [5.4].
Рассмотрим основные параметры simd директивы:
-
vectorlength(n) – данный параметр определяет количество итераций цикла, которые могут быть выполнены независимо за одну векторную операцию. Например, если алгоритм построен таким образом, что независимы только порции по 4 итерации цикла, а между порциями есть зависимости, тогда имеет смысл использовать этот параметр. Если этого не сделать, то при достаточно большом размере векторных регистров компилятор векторизует большее число итераций цикла, что приведет к некорректному коду.
#pragma simd vectorlength(4) for (i = 0; i < n; i++) { a[i] = a[i] + b[i] + c[i]; } -
linear(var1:step1 [,var2:step2]...) – этот параметр сообщает компилятору, что переменные var инкрементируются с шагом step на каждой итерации цикла. Обычно речь идет о тех переменных, которые выступают в роли индексов при обращении к элементам массивов:
#pragma simd linear(k:j) for (i = 0; i < n; i += step) { k += j; a[i] = a[i] + b[n - k + 1]; } -
reduction(oper:var1 [,var2]…) – параметр аналогичен соответствующему параметру директивы omp, обеспечивает выполнение операции редукции для заданного списка переменных по окончании выполнения операций цикла:
int x = 0; #pragma simd reduction(+:x) for (i = 0; i < n; ++i) x = x + A[i]; -
private(var1[, var2]...) – параметр аналогичен соответствующему параметру директивы omp, сообщает компилятору о необходимости создания отдельного экземпляра переменной для каждой итерации цикла. Определены также параметры firstprivate и lastprivate, позволяющие задать начальное и конечное значение переменной в рамках каждой итерации цикла. В качестве примера использования данного параметра можно привести код функции для вычисления числа Пи:
double pi(int count) { int i; double pi = 0.0; double t; #pragma simd private(t) reduction(+:pi) for (i=0; i<count; i++) { t = (double)((i+0.5)/count); pi += 4.0/(1.0+t*t); } pi /= count; return pi; }
Отметим, что на настоящий момент в компиляторах Intel активно улучшается поддержка процесса векторизации с использованием директивы simd, повышается область ее применения и добавляются новые возможности.
Svetlana Svetlana