|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Инспектор
Вы можете этот курс.
Опубликован: 30.05.2014 | Уровень: для всех | Доступ: платный | ВУЗ: Нижегородский государственный университет им. Н.И.Лобачевского
Лекция 5: Элементы оптимизации прикладных программ для Intel Xeon Phi. Intel C/C++ Compiler
Аннотация: В данном разделе рассматривается offload модель программирования для сопроцессора Intel Xeon Phi с архитектурой Intel Many Integrated Core (MIC).
Расширения языков программирования C/С++ и Fortran
Презентацию к лекции Вы можете скачать здесь.
В данном разделе рассматривается offload модель программирования для сопроцессора Intel Xeon Phi с архитектурой Intel Many Integrated Core (MIC). Дается расширенное описание синтаксических конструкций (расширений языков C/С++ и Fortran) для работы с сопроцессором. Даются рекомендации по эффективной работе с Intel Xeon Phi.
В "Выполнение программ на Intel Xeon Phi. Модели организации вычислений с использованием Intel Xeon Phi " было дано описание моделей организации вычислений на сопроцессоре Intel Xeon Phi, в частности, приведены примеры программ для работы с сопроцессором режиме offload. В данной лекции программирование в режиме offload обсуждается подробно.
Для переноса участков кода на Intel MIC программисту предоставляется возможность использования конструкций вида #pragma, а также новых ключевых слов в языках C/С++. Применение конструкций вида #pragma похоже на работу с директивами OpenMP, а ключевые слова являются расширением Intel Cilk Plus.
Язык Fortran не поддерживает работу с расширением Cilk Plus, однако дает возможность использовать директивы, аналогичные #pragma для языков C/C++. Дальнейшее изложение будет вестись применительно к языкам C/C++. Возможности, поддерживаемые языком Fortran, будут описываться отдельно.
Следует отметить, что по умолчанию для offload участков программы компилятор генерирует код, способный исполняться как на сопроцессоре, так и на обычном центральном процессоре. Это позволяет вашей программе корректно работать даже при отсутствии Intel Xeon Phi.
Еще одно достоинство данной модели программирования состоит в том, что компилятор берет на себя все заботы о копировании кода на сопроцессор, копировании всех нужных для его работы данных и результатов его исполнения, выделении и удалении памяти на Intel MIC. Программисту необходимо только указать участок программы для работы на сопроцессоре и дать компилятору рекомендации касательно копирования нужной этому коду памяти.
Подчеркнем, что память центрального процессора и сопроцессора не является разделяемой реально или виртуально на основе аппаратного обеспечения. Это означает, что данные должны копироваться из одной памяти в другую на программном уровне.
Выделяют две offload модели передачи данных – явную и неявную. На языке Fortran можно использовать только явную модель.
При использовании явной модели программист должен указать те переменные, которые нужно скопировать из одной памяти в другую, с помощью директив #pragma.
Неявная модель предполагает разделение данных между CPU и MIC. Программист отмечает те переменные, которые должны быть доступны как из кода сопроцессора, так и из управляющего кода.
Явная схема работы с памятью в режиме offload
Как уже отмечалось выше, явная схема работы с памятью предполагает использование #pragma директив. Достоинством такого подхода является возможность компиляции вашего кода любым компилятором. Если используется не Intel Compiler, то код будет скомпилирован для работы на центральном процессоре, неизвестные директивы будут проигнорированы без генерации ошибок. Использование же ключевых слов приведет к ошибке времени компиляции.
| Описание | C/C++ синтаксис | Семантика |
|---|---|---|
| Директива offload |
#pragma offload <clauses> <statement> |
Запуск участка кода на сопроцессоре или CPU |
| Ключевое слово для указания MIC функции или переменной |
__attribute__((target(mic))) |
Компиляция функции или объявление переменной одновременно для CPU и сопроцессора |
| Указание MIC блока кода |
#pragma offload_attribute(push, target(mic)) … #pragma offload_attribute(pop) |
Компиляция блока кода одновременно для CPU и сопроцессора |
| Отдельная передача данных |
#pragma offload_transfer target(mic) |
Обеспечивает синхронную или асинхронную передачу данных между CPU и сопроцессором |
Рассмотрим подробно директивы запуска участка программы на сопроцессоре и копирования данных. Сводная информация по этим директивам приведена в таблице 5.1.
Отметим, что язык Fortran поддерживает набор аналогичных директив, информация по которым приведена в таблице 5.2.
| Описание | C/C++ синтаксис | Семантика |
|---|---|---|
| Директивы offload |
!dir$ omp offload <clauses> <statement> |
Запуск параллельного (OpenMP) участка кода на сопроцессоре или CPU |
dir$ offload <clauses> <statement> |
Запуск участка кода (вызов функции) на сопроцессоре или CPU | |
| Ключевое слово для указания MIC функции или переменной |
!dir$ attributes offload:<mic> :: <ret-name> OR <var1,var2,…> |
Компиляция функции или объявление переменной одновременно для CPU и сопроцессора |
| Отдельная передача данных |
!dir$ offload_transfer target(mic) |
Обеспечивает синхронную или асинхронную передачу данных между CPU и сопроцессором |
В качестве примера использования описанных выше директив рассмотрим следующий код:
__attribute__((target(mic))) void func(float* a,
float* b, int count, float c, float d)
{
#pragma omp parallel for
for (int i = 0; i < count; ++i)
{
a[i] = b[i]*c + d;
}
}
int main()
{
const int count = 100;
float a[count], b[count], c, d;
…
#pragma offload target(mic)
func(a, b, count, c, d);
…
}
Функция func() указывается в качестве участка кода для компиляции под Intel Xeon Phi (одновременно она будет скомпилирована для исполнения на CPU). Вызов этой функции указывается в качестве тела директивы offload, что приводит к ее запуску на сопроцессоре. Здесь же происходит обмен данными с Xeon Phi в автоматическом режиме.
Заметим, что в случае отсутствия в системе сопроцессора, программа останется корректной и будет исполняться на CPU. В данном случае решение о том, где запускать offload часть, принимается автоматически в момент исполнения программы. В первую очередь делается попытка использовать сопроцессор, а если это не удалось – используется CPU. Причины неудачи могут быть следующими: отсутствие сопроцессора, все сопроцессоры заняты другими расчетами, сбой при попытке offload’а.
Отметим также, что у программиста есть возможность указать номер конкретного сопроцессора, на котором будет исполняться offload код. И в этом случае программа либо запустится на указанном сопроцессоре, либо завершится с ошибкой времени исполнения.
Для указания номера сопроцессора следует использовать директиву:
#pragma offload target(mic:n)
Здесь n – это желаемый номер сопроцессора. Может быть как константой, так и переменной. Если в качестве номера указано число, которое больше общего количества сопроцессоров, доступных в системе, то код будет выполнен на сопроцессоре с номером (n % <ОбщееЧислоXeonPhi>).
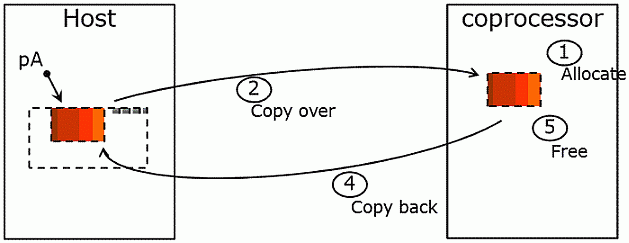
Полезно рассмотреть процесс запуска на Intel Xeon Phi по шагам ( рис. 5.1):
- На сопроцессоре выделяется память под массивы a[] и b[].
- Выполняется передача данных (всех массивов и переменных) на сопроцессор.
- Функция запускается на исполнение на Intel Xeon Phi.
- Выполняется передача данных (всех массивов) с сопроцессора в оперативную память.
- Удаляется память на сопроцессоре.
Важно отметить, что весь этот процесс выполняется в синхронном режиме, т.е. выполнение программы на CPU блокируется до тех пор, пока результаты работы функции на MIC не будут доступны в оперативной памяти процессора.
Как видно из примера, даже в таком простом случае выполняется достаточно много лишних действий, связанных с передачей данных. Во-первых, при копировании массивов на сопроцессор массив a[] копировать не надо, так как его значения вычисляются в процессе работы функции func(). Во-вторых, при копировании данных назад в оперативную память процессора можно не передавать массив b[], так как он не изменяется в рамках данной функции.
Для повышения эффективности здесь достаточно воспользоваться дополнительными параметрами директивы offload, которые приведены в таблице 5.3.
| Операторы (clauses) | C/C++ синтаксис | Семантика |
|---|---|---|
| Target спецификация | target(name[:card_number]) | Явное указание того, где запускать код |
| Условный offload | if (condition) | Запуск кода, если условие истинно |
| Вход | in (var-list [modifiers]) | Копирование с хоста на сопроцессор |
| Выход | out (var-list [modifiers]) | Копирование с сопроцессора на хост |
| Вход и выход | inout (var-list [modifiers]) | Копирование в обе стороны |
| Отмена копирования | nocopy (var-list [modifiers]) | Локальные данные сопроцессора |
| Асинхронный offload | signal(signal-slot) | Режим асинхронного offload’а |
| Асинхронный offload | wait(signal-slot) | Ожидание завершения асинхронного offload’а |
| Модификаторы (modifiers) | ||
| Размер памяти при копировании | length (element-count-expr) | Размер указывается в элементах, а не в байтах |
| Условное выделение | alloc_if (condition) | Выделить память на сопроцессоре, если условие истинно |
| Условное освобождение | free_if (condition) | Удалить память на сопроцессоре, если условие истинно |
| Выравнивание | align (expression) | Задание минимального выравнивания данных на сопроцессоре |
Копирование поддерживается для следующих типов:
- Скалярные переменные всех встроенных типов данных (локальные переменные копируются автоматически, указания модификаторов не требуется);
- Структуры с возможностью побитового копирования (т.е. не содержащие членов-указателей);
- Массивы перечисленных выше типов данных.
Иными словами, поддерживается только побитовое копирование данных. Для более сложных типов данных, содержащих указатели на дополнительные поля, копирование придется делать вручную.
Svetlana Svetlana