
|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Инспектор
Спонсор: Intel
Вы можете этот курс.
Опубликован: 30.05.2014 | Уровень: для всех | Доступ: платный | ВУЗ: Нижегородский государственный университет им. Н.И.Лобачевского
Лекция 5: Элементы оптимизации прикладных программ для Intel Xeon Phi. Intel C/C++ Compiler
Использование дополнительных параметров offload директивы применительно к предыдущему примеру приведено ниже:
__attribute__((target(mic))) void func(float* a,
float* b, int count, float c, float d)
{
#pragma omp parallel for
for (int i = 0; i < count; ++i)
{
a[i] = b[i]*c + d;
}
}
int main()
{
const int count = 100;
float a[count], b[count], c, d;
…
#pragma offload target(mic) in(b) out(a)
func(a, b, count, c, d);
…
}
Теперь выполняется обмен только теми данными, которые нужны. Длина массивов здесь не указывается, т.к. массивы статические. Переменные count, c и d будут скопированы на сопроцессор автоматически.
Работа с динамическими массивами чуть сложнее. В частности, необходимо явно указывать размер данных при копировании:
#define ALLOC alloc_if(1) free_if(0)
#define FREE alloc_if(0) free_if(1)
#define REUSE alloc_if(0) free_if(0)
void f()
{
int *p = (int *)malloc(100*sizeof(int));
// Memory is allocated for p,
// data is sent from CPU and retained
#pragma offload target(mic:0) in(p[0:100] : ALLOC)
{ p[6] = 66; }
…
// Memory for p reused from previous offload
// and retained once again
// Fresh data is sent into the memory
#pragma offload target(mic:0) in(p[0:100] : REUSE)
{ p[6] = 66; }
…
// Memory for p reused from previous offload,
// freed after this offload.
// Final data is pulled from coprocessor to CPU
#pragma offload target(mic:0) out(p[0:100] : FREE)
{ p[7] = 77; }
…
}
В данном примере демонстрируется также возможность хранения данных на сопроцессоре между вызовами кода на нем.
Рассмотрим этот пример подробней.
Во-первых, мы динамически выделяем память на центральном процессоре. К этому моменту данные существуют только в оперативной памяти CPU.
Первое обращение к сопроцессору приводит к выделению памяти на нем и копированию туда данных из оперативной памяти. После чего на MIC изменяется элемент p[6] . После окончания этого шага имеем почти идентичные копии массива p[] на CPU и сопроцессоре. Отличается один элемент p[6] , который равен 66 на сопроцессоре. По окончании шага данные на сопроцессоре не удаляются.
При втором обращении к сопроцессору выделения/удаления памяти не происходит, однако происходит копирование данных из оперативной памяти в память сопроцессора, т.е. выполняется обновление массива p[].
На заключительном шаге данные с сопроцессора копируются в оперативную память, после чего память на MIC освобождается. Обратите внимание, что элемент p[7] на CPU будет равен 77 по завершении операции.
Рассмотрим еще один пример работы с динамической памятью. Но на этот раз будем использовать данные, размещенные только на сопроцессоре:
void f()
{
int *p;
…
// The nocopy clause ensures CPU values pointed to by p
// are not transferred to coprocessor
#pragma offload target(mic:0) nocopy(p)
{
// Allocate dynamic memory for p on coprocessor
p = (int *)malloc(100);
p[0] = 77;
…
}
..
// The nocopy clause ensures p is not altered
// by the offload process
#pragma offload target(mic:0) nocopy(p)
{
// Reuse dynamic memory pointed to by p
… = p[0]; // Will be 77
}
}
Обратите внимание, что при использовании модификатора nocopy() автоматического выделения, а значит и удаления памяти не происходит. Это позволяет нам выделять память только в рамках сопроцессора и использовать ее для хранения данных между вызовами кода для Intel MIC.
Как уже отмечалось выше, при использовании offload директивы для исполнения участка кода на сопроцессоре основной CPU-поток приостанавливается до тех пор, пока сопроцессор не завершит свою работу. Для того чтобы обеспечить одновременную работу процессора и сопроцессора, либо нескольких сопроцессоров, рекомендуется использовать несколько CPU-потоков, каждый из которых будет отвечать за выполнение расчетов на своем устройстве.
Приведенный ниже пример показывает, как организовать одновременную работу процессора и сопроцессора:
double __attribute__((target(mic)))
myworkload(double input)
{
// do something useful here
return result;
}
int main(void)
{
//…. Initialize variables
#pragma omp parallel sections
{
#pragma omp section
{
#pragma offload target(mic)
result1= myworkload(input1);
}
#pragma omp section
{
result2= myworkload(input2);
}
}
}
Для создания вспомогательных CPU-потоков не обязательно использовать возможности технологии OpenMP. Подойдет любое доступное вам средство, начиная от потоков операционной системы и заканчивая специальными библиотеками (например, TBB).
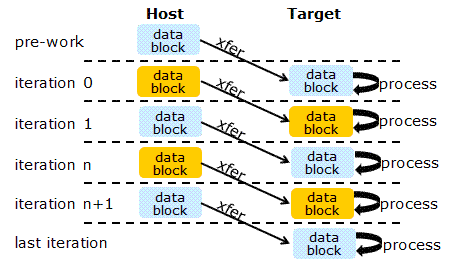
Следующий пример демонстрирует применение асинхронного offload режима для организации схемы двойной буферизации данных. Метод двойной буферизации применяется для того, чтобы уменьшить время передачи данных за счет одновременного выполнения передач и полезных расчетов ( рис. 5.2).
Идея метода заключается в следующем. Поток входных данных делится на блоки. Перед началом работы алгоритма первый блок данных копируется на сопроцессор. Далее инициируется копирование второго блока данных, и одновременно запускаются расчеты на первом блоке. К моменту окончания расчетов второй блок данных в идеале уже доступен на сопроцессоре, соответственно можно запустить расчеты для него, и одновременно начать загрузку третьего блока. И так далее.
В коде с использованием асинхронных возможностей offload режима это выглядит следующим образом:
int main(int argc, char* argv[])
{
// Allocate & initialize in1, res1,
// in2, res2 on host
#pragma offload_transfer target(mic:0) in(cnt)\
nocopy(in1, res1, in2, res2 : length(cnt) \
alloc_if(1) free_if(0))
do_async_in();
// Free MIC memory
#pragma offload_transfer target(mic:0) \
nocopy(in1, res1, in2, res2 : length(cnt) \
alloc_if(0) free_if(1))
return 0;
}
void do_async_in()
{
float lsum;
int i;
lsum = 0.0f;
#pragma offload_transfer target(mic:0) \
in(in1 : length(cnt) \
alloc_if(0) free_if(0)) signal(in1)
for (i = 0; i < iter; i++)
{
if (i % 2 == 0)
{
#pragma offload_transfer target(mic:0) \
if(i !=iter - 1) in(in2 : length(cnt) \
alloc_if(0) free_if(0)) signal(in2)
#pragma offload target(mic:0) nocopy(in1) \
wait(in1) out(res1 : length(cnt) \
alloc_if(0) free_if(0))
{
compute(in1, res1);
}
lsum = lsum + sum_array(res1);
}
else
{
#pragma offload_transfer target(mic:0) \
if(i != iter - 1) in(in1 : length(cnt) \
alloc_if(0) free_if(0)) signal(in1)
#pragma offload target(mic:0) nocopy(in2) \
wait(in2) out(res2 : length(cnt) \
alloc_if(0) free_if(0))
{
compute(in2, res2);
}
lsum = lsum + sum_array(res2);
}
} // for
} // do_async_in()
В завершении раздела о явной схеме работы с памятью рассмотрим пример работы со сложными структурами данных и дадим метод их передачи на сопроцессор:
typedef struct {
int m1;
char *m2;
} nbwcs;
void sample11()
{
nbwcs struct1;
struct1.m1 = 10;
struct1.m2 = malloc(11);
int m1;
char *m2;
// Disassemble the struct for transfer to target
m1 = struct1.m1;
m2 = struct1.m2;
#pragma offload target(mic) inout(m1) inout(m2 : length(11)
{
nbwcs struct2;
// Reassemble the struct on the target
struct2.m1 = m1;
struct2.m2 = m2;
...
}
...
}
Основная идея здесь заключается в необходимости передачи полей сложной структуры по отдельности, после чего их можно собрать воедино уже в рамках сопроцессора.
Svetlana Svetlana