| Россия, г. Москва |
Инспектор
Вы можете этот курс.
Опубликован: 02.06.2014 | Уровень: для всех | Доступ: платный | ВУЗ: Нижегородский государственный университет им. Н.И.Лобачевского
Самостоятельная работа 2: Оптимизация вычислительно трудоемкого программного модуля для архитектуры Intel Xeon Phi. Линейные сортировки
Модификация сортировки LSD
Внесём изменения в метод exectute класса Placer5Читатель может самостоятельно оценить вклад каждого из внесённых изменений во время работы программы. :
- Избавимся от повторного вычисления значений inpUC[i<<3] .
- Выполним разворачивание цикла на две итерации – это уменьшит ко-личество операций сравнения и снизит зависимость между итерациями.
- Выполним упреждающую загрузку данных в кэш-память с помощью функции _mm_prefetch. Значение _MM_HINT_T0 означает, что данные надо загрузить в ближайший кэш к ядру L1 (а т.к. архитектура кэша инклюзивная, то и в L2).
task* execute()
{
unsigned char *inpUC=(unsigned char *)inp + byteNum;
int end = size - size%2;
int end_prefetch = end-8;
_mm_prefetch((const char*)&(out[counter[inpUC[(0)<<3]]]), _MM_HINT_T0);
_mm_prefetch((const char*)&(out[counter[inpUC[(1)<<3]]]), _MM_HINT_T0);
for(int i=0; i<end_prefetch; i+=2)
{
int next = i+1;
_mm_prefetch(
(const char*)&(out[counter[inpUC[(i+8)<<3]]]),
_MM_HINT_T0);
_mm_prefetch(
(const char*)&(out[counter[inpUC[(i+9)<<3]]]),
_MM_HINT_T0);
int &c1=counter[inpUC[i<<3]];
int &c2=counter[inpUC[next<<3]];
out[c1++]=inp[i];
out[c2++]=inp[next];
}
for(int i=end_prefetch; i<end; i+=2)
{
int &c1=counter[inpUC[i<<3]];
int &c2=counter[inpUC[(i+1)<<3]];
out[c1++]=inp[i];
out[c2++]=inp[i+1];
}
for(int i=end; i<size; i++)
{
int &c=counter[inpUC[i<<3]];
out[c++]=inp[i];
}
return NULL;
}
Внесём изменения в функцию exectute класса LSDParallelSorter, чтобы выделять память под масси-вы объектов один раз.
task* execute()
{
int *counters = new int[256 * nThreads];
int byteNum = 0;
Counter **ctr1 = new Counter*[nThreads-1];
Placer **pl1 = new Placer*[nThreads-1];
Counter **ctr2 = new Counter*[nThreads-1];
Placer **pl2 = new Placer*[nThreads-1];
int s = size / nThreads;
for(;byteNum<8;byteNum+=2)
{
for(int i=0; i<nThreads-1; i++)
{
ctr1[i] = new (allocate_child())
Counter(mas + i*s, s, byteNum, counters + 256 * i);
ctr2[i] = new (allocate_child())
Counter(tmp + i*s, s, byteNum+1, counters + 256 * i);
pl1[i] = new (allocate_child())
Placer(mas + i*s, tmp, s, byteNum, counters + 256 * i);
pl2[i] = new (allocate_child())
Placer(tmp + i*s, mas, s, byteNum+1, counters + 256 * i);
}
Counter &ctrLast1 = *new (allocate_child())
Counter(mas + s * (nThreads-1), size - s * (nThreads-1) ,
byteNum, counters + 256 * (nThreads-1));
Counter &ctrLast2 = *new (allocate_child())
Counter(tmp + s * (nThreads-1), size - s * (nThreads-1) ,
byteNum+1, counters + 256 * (nThreads-1));
Placer &plLast1 = *new (allocate_child())
Placer(mas + s * (nThreads-1),tmp, size - s * (nThreads-1),
byteNum, counters + 256 * (nThreads-1));
Placer &plLast2 = *new (allocate_child())
Placer(tmp + s * (nThreads-1),mas, size - s * (nThreads-1),
byteNum+1, counters + 256 * (nThreads-1));
set_ref_count(nThreads+1);
for(int i=0; i<nThreads-1; i++)
spawn(*(ctr1[i]));
spawn_and_wait_for_all(ctrLast1);
int sm = 0;
for(int j=0; j<256; j++)
{
for(int i=0; i<nThreads; i++)
{
int b=counters[j + i * 256];
counters[j + i * 256]=sm;
sm+=b;
}
}
set_ref_count(nThreads+1);
for(int i=0; i<nThreads-1; i++)
spawn(*(pl1[i]));
spawn_and_wait_for_all(plLast1);
set_ref_count(nThreads+1);
for(int i=0; i<nThreads-1; i++)
spawn(*(ctr2[i]));
spawn_and_wait_for_all(ctrLast2);
sm = 0;
for(int j=0; j<256; j++)
{
for(int i=0; i<nThreads; i++)
{
int b=counters[j + i * 256];
counters[j + i * 256]=sm;
sm+=b;
}
}
set_ref_count(nThreads+1);
for(int i=0; i<nThreads-1; i++)
spawn(*(pl2[i]));
spawn_and_wait_for_all(plLast2);
}
delete[] pl1;
delete[] pl2;
delete[] ctr1;
delete[] ctr2;
delete[] counters;
return NULL;
}
Сравним время работы модифицированной версии и базовой на хосте ( рис. 4.25) и сопроцессоре ( рис. 4.26, рис. 4.27) при сортировке 100 миллионов эле-ментов.
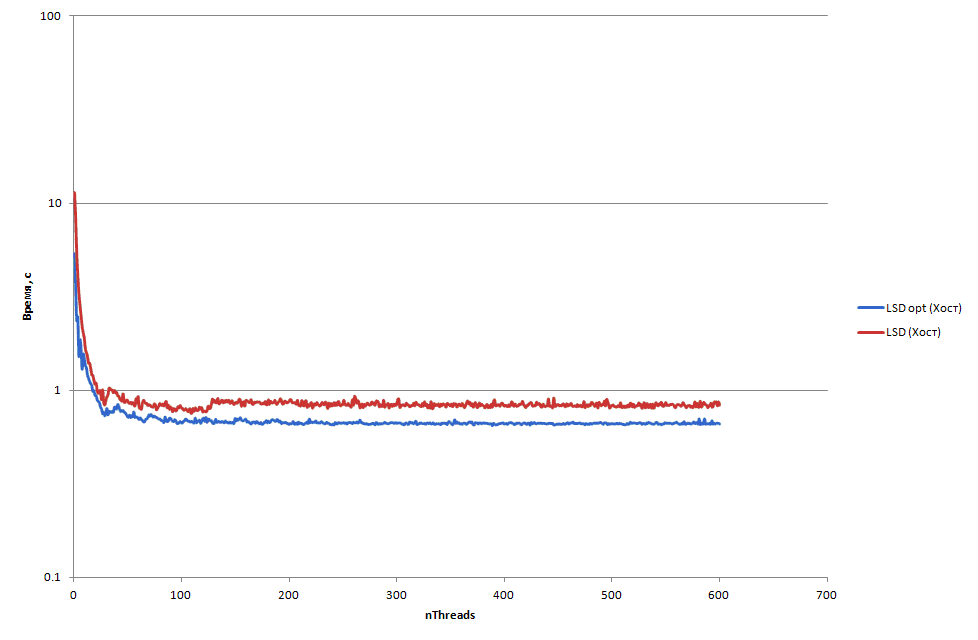
увеличить изображение
Рис. 4.25. Сравнение параллельных реализаций LSD на хосте при сор-тировки 100 миллионов элементов