| Россия, г. Москва |
Инспектор
Вы можете этот курс.
Опубликован: 02.06.2014 | Уровень: для всех | Доступ: платный | ВУЗ: Нижегородский государственный университет им. Н.И.Лобачевского
Самостоятельная работа 2: Оптимизация вычислительно трудоемкого программного модуля для архитектуры Intel Xeon Phi. Линейные сортировки
Анализ параллельной реализации
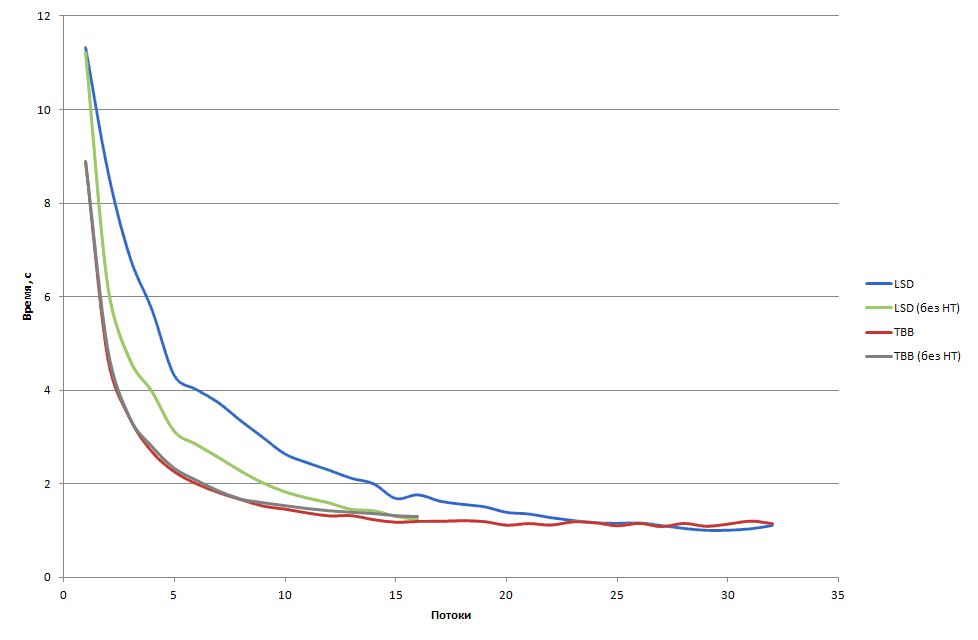
Для начала, приведём результаты экспериментов на хостовой машине в двух режимах запуска ( рис. 4.15):
- Запуск на всех доступных логических процессорах (максимум 32 потока);
- Запуск не более чем одного потока на каждое ядро (максимум 16 потоков).
увеличить изображение
Рис. 4.15. Время сортировки 100 миллионов элементов на хосте с привязкой и без привязки к ядрам. Реализации: TBB и LSD (внутренне распараллеливание)
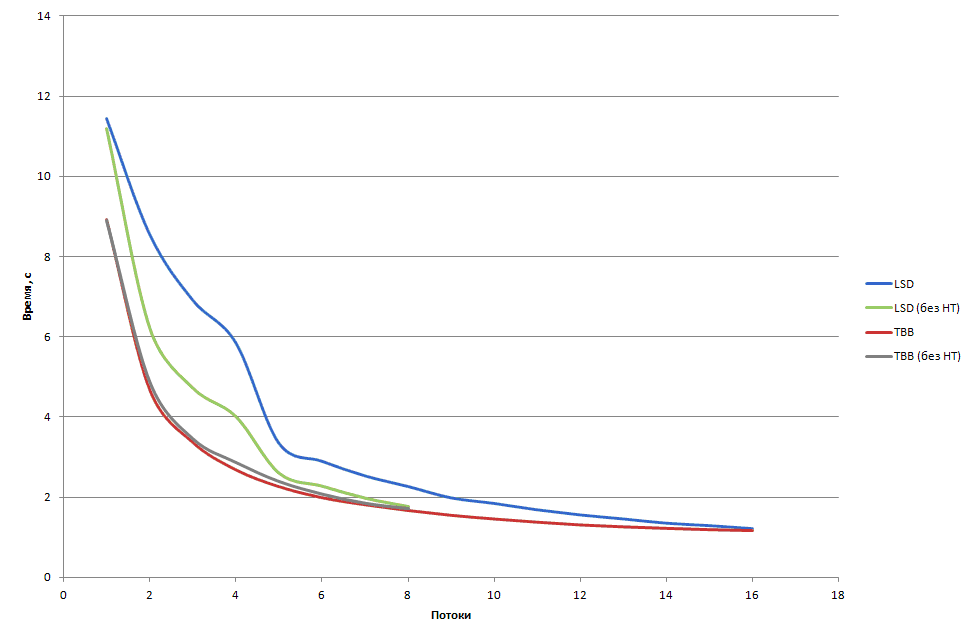
Приведём аналогичные результата при запуске только на одном процессоре ( рис. 4.16). Будет снова два режима запуска:
- Запуск на всех доступных логических процессорах (максимум 16 потоков);
- Запуск не более чем одного потока на каждое ядро (максимум 8 потоков).
увеличить изображение
Рис. 4.16. Время сортировки 100 миллионов элементов на 1 процессоре на хосте с привязкой и без привязки к ядрам. Реализации: TBB и LSD (внутренне распараллеливание)
Время работы параллельной LSD реализации на одном процессоре (16 потоков) составило 1.22 с, на двух процессорах (32 потока) – 1 с. Далее все эксперименты на хосте будут проводиться на всех доступных логических процессорах.
Реализация сортировки в MKL не является параллельной, поэтому она не приведена на графике выше. На 100 миллионах элементов время сортировки с использованием библиотеки MKL составляет 9.4 с.
Из рис. 4.16 видно, что при запуске приложения в 16 потоков в режиме одного потока на ядро время работы LSD реализации ощутимо меньше, чем при запуске на всех доступных логических ядрах. Планировщик потоков ОС выбирает для приложения наиболее свободные логические процессоры из доступных. Таким образом, когда приложение выполняется на всех логических ядрах, может сложиться ситуация, когда 2 потока будут выполняться на одном ядре, поэтому результат получается достаточно предсказуемым, т.к. два аппаратных потока, работающих на одном ядре, будут конкурировать за ресурсы этого ядра (кэш-память, вычислительные блоки), что снизит общую производительность приложения.
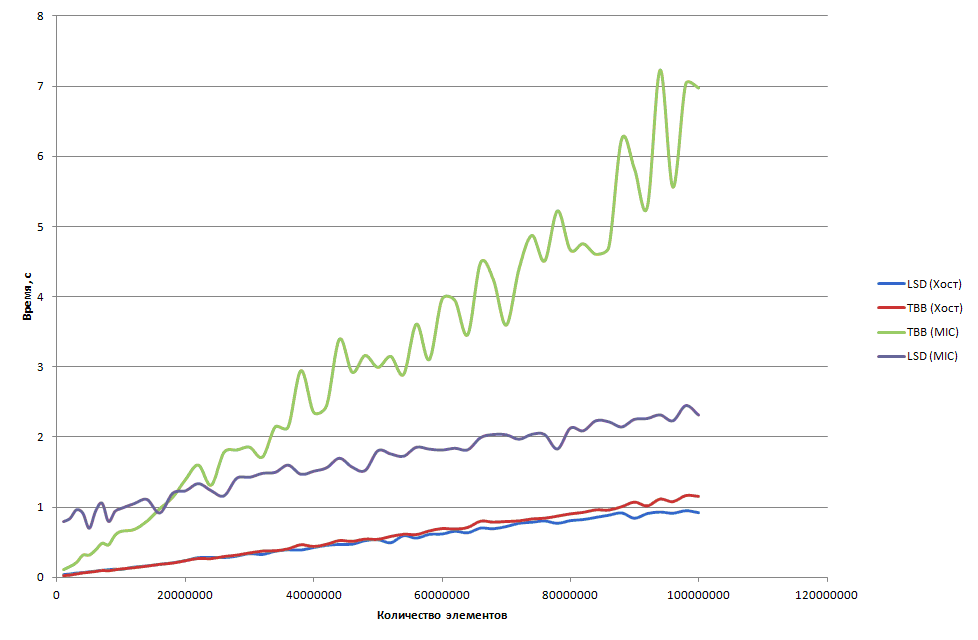
Ниже представлены графики зависимости времени работы параллельных реализаций TBB и LSD в зависимости от количества сортируемых элементов ( рис. 4.17). На графике также приведены результаты работы функции сортировки из библиотеки MKL.
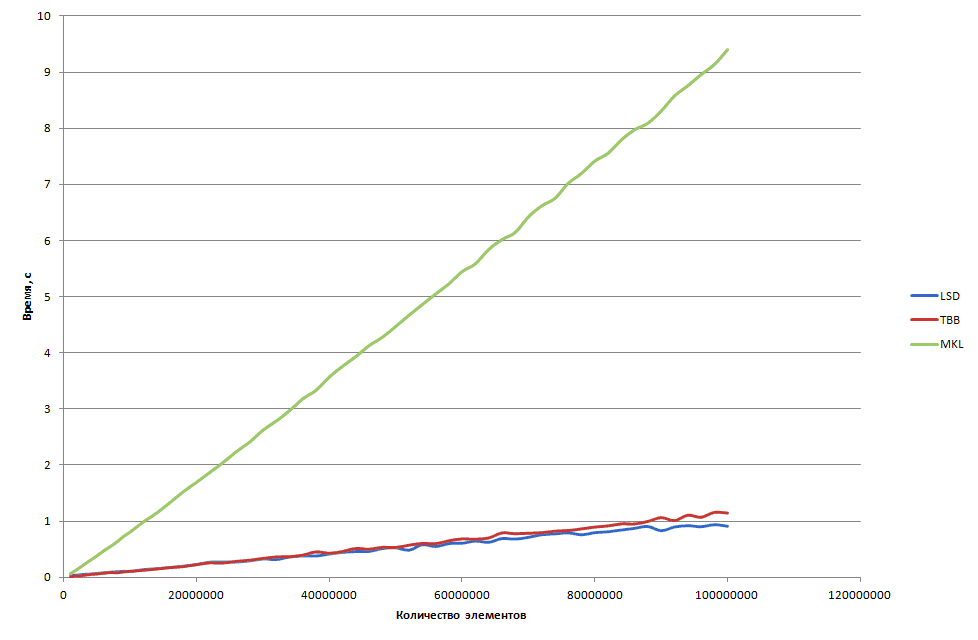
увеличить изображение
Рис. 4.17. Время сортировки при запуске в 32 потока. Реализации: MKL, TBB и LSD (внутренне распараллеливание)
Далее рассмотрим результаты запусков на сопроцессоре. Intel Xeon Phi имеет по 4 аппаратных потока на каждое ядро, поэтому на графике представлены три кривые ( рис. 4.18):
- LSD – приложение выполнялось на всех логических процессорах – по 4 потока на ядро;
- LSD:2 – приложение выполнялось только на логических процессорах с нечётными номерами (1, 3, 5, 7 и т.д.)3Логический процессор с номером 0 больше всего используется ОС сопроцессора, поэтому исключим его из списка потоков на которых будет запускаться приложение. – по 2 потока на ядро;
- LSD:4 - приложение выполнялось только на логических процессорах с номерами 1, 5, 9 и т.д. – по 1 потоку на ядро.
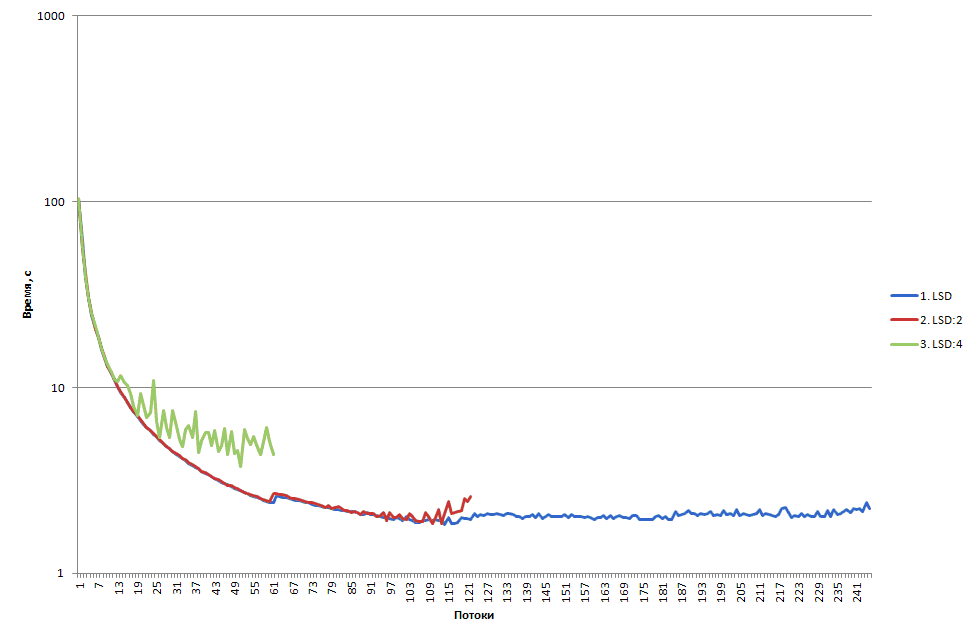
увеличить изображение
Рис. 4.18. Время сортировки 100 миллионов элементов на сопроцессоре с различной привязкой к ядрам
Обратим внимание, что сначала все три графика совпадают. При увеличении количества потоков версия 3 начинает работать медленнее, чем остальные. Дело в том, что в версии LSD:4 количество доступных потоков для приложения ограничено величиной 61 и ОС вынуждена планировать потоки приложения только среди них, при этом в ОС есть и другие потоки, которым требуется процессорное время. Это приводит к конкуренции сторонних потоков за выбранные логические процессоры. Это утверждение будет справедливо и для версии 2 (LSD:2). Для лучшей визуализации данного эффекта имеет смысл для каждого количества потоков выполнить несколько запусков и выбрать среди них минимальное время работы. Тогда кривая LSD:4 будет наиболее близка к LSD:2, а LSD:2 – к LSD. Читателю рекомендуется проделать это самостоятельно.
Для наглядности представим диаграмму времени работы параллельной LSD реализации при сортировке 100 миллионов элементов с привязкой к ядрам.
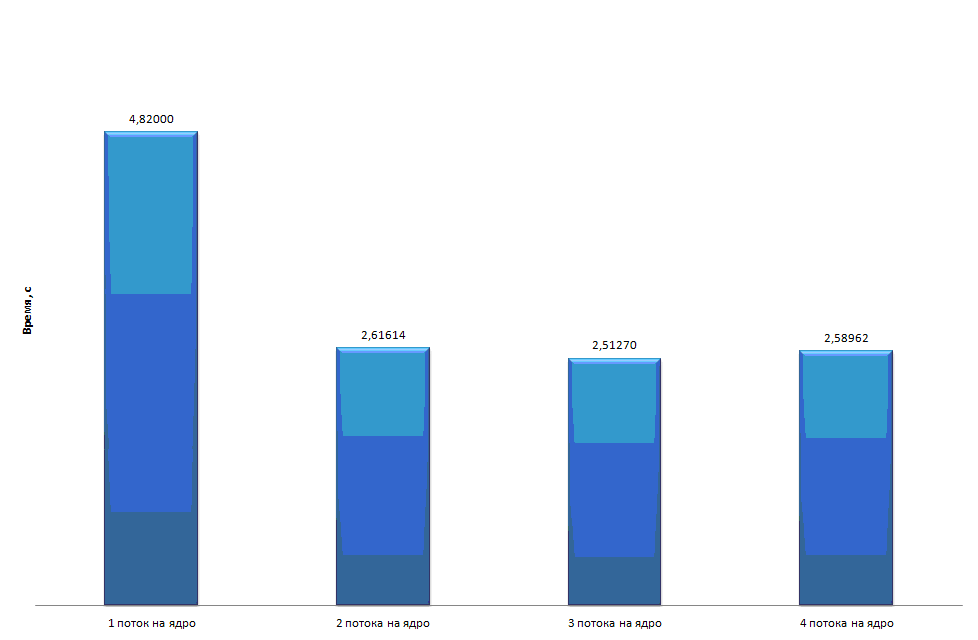
увеличить изображение
Рис. 4.19. Времени работы параллельной LSD реализации при сортировке 100 миллионов элементов с привязкой к ядрам
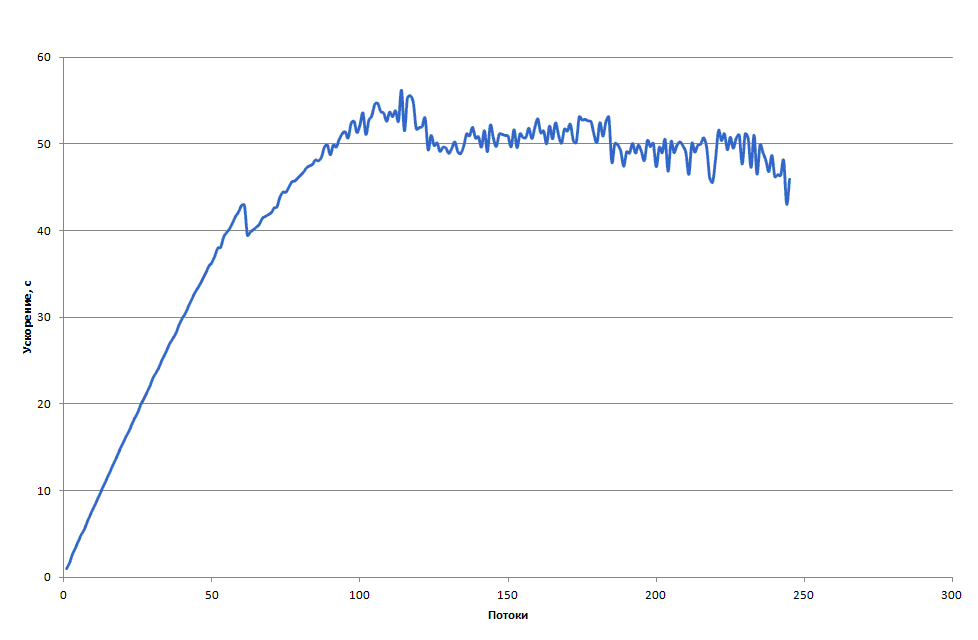
Приведём график ускорения параллельной LSD реализации на Intel Xeon Phi при сортировке 100 миллиона элементов ( рис. 4.20). Отметим, что на границе в 61-62 потока наблюдается резкий скачок времени. На сопроцессоре доступно 61 ядро, а при использовании 62 потоков, как минимум два из всех потоков будут выполняться на одном ядре. Это приводит к конкуренции потоков за ресурсы кэш-памяти ядер.
Максимальное ускорение, а следовательно и минимальное время работы, достигается на 115 потоках и составляет 56,2. Минимальное время работы LSD на сопроцессоре составляет 1,83 с. Таким образом, максимальная эффективность достигается при использовании двух потоков на ядро. Увеличение количества потоков негативно сказывается на времени работы программы из-за возрастающей конкуренции за ресурсы ядер.
Время работы поразрядной сортировки (LSD) на одном ядре на хосте составило 11,47 с, на сопроцессоре – 102,95 с. Значительное отставание по времени работы на сопроцессоре обусловлено существенной разницей в производительности ядер. Кроме того, как уже отмечалось, однопоточное приложение на Intel Xeon Phi простаивает каждый второй такт процессора. Для наглядности приведём диаграмму времени работы параллельной LSD реализации при запуске на одном ядре ( рис. 4.21).
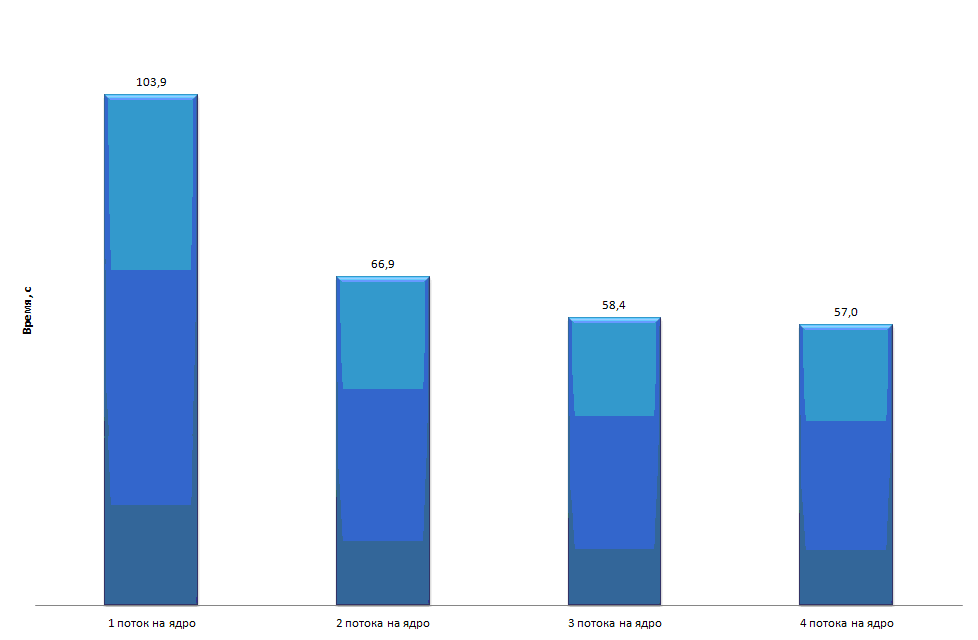
увеличить изображение
Рис. 4.21. Время сортировки 100 миллионов элементов на сопроцессоре на одном ядре
Из рис. 4.21 видно, что при использовании двух потоков на ядро получается существенное ускорение. Использование 4-х потоков на ядро не даёт существенного выигрыша по сравнению с 3-мя.
Ниже представлены графики зависимости времени работы параллельных реализаций TBB и LSD в зависимости от количества сортируемых элементов ( рис. 4.22) на хосте и сопроцессоре (MIC). Все реализации запускались на максимально доступном количестве аппаратных потоков: 32 на хосте и 244 на сопроцессоре. Заметим, что лучшее время работы параллельной реализации LSD на сопроцессоре достигается при использовании 115 потоков, но на общем виде графиков это не отразится. Читателю рекомендуется самостоятельно провести эксперименты с выбором оптимального количества потоков для каждого количества сортируемых элементов (для каждой размерности необходимо выполнить запуск на всём диапазоне допустимого количества потоков и выбрать из них минимум).
Из графиков выше можно сделать вывод, что сортировка не лучшим образом реализуется на сопроцессоре Intel Xeon Phi. Заметим, что минимальное время работы сортировки 100 миллиона элементов на хосте составило 1 с при использование двух процессоров и 1.22 с при использовании одного процессора, на Intel Xeon Phi – 1,83 с. Времена получились сопоставимы. Разберём подробнее полученные результаты.