| Россия, г. Москва |
Инспектор
Вы можете этот курс.
Опубликован: 02.06.2014 | Уровень: для всех | Доступ: платный | ВУЗ: Нижегородский государственный университет им. Н.И.Лобачевского
Самостоятельная работа 2: Оптимизация вычислительно трудоемкого программного модуля для архитектуры Intel Xeon Phi. Линейные сортировки
Слияние "Разделяй и властвуй"
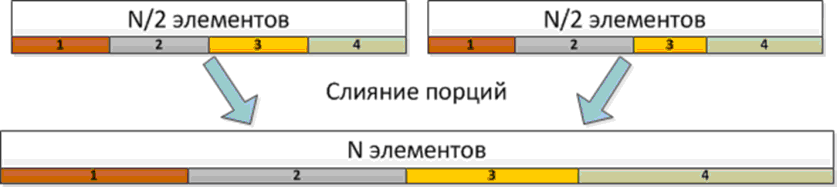
Идея слияния по алгоритму "Разделяй и властвуй" заключается в разбиении массивов на участки, которые можно слить независимо [ [ 4.8 ] ]. В первом массиве выбирается центральный элемент x (он разбивает массив на две равные половины), а во втором массиве с помощью бинарного поиска находится позиция наибольшего элемента меньшего x (позиция этого элемента разбивает второй массив на две части). После такого разбиения первые и вторые половины массивов могут сливать независимо, т.к. в первых половинах находятся элементы меньшие элемента x, а во второй – большие ( рис. 4.9). Для слияния двух массивов несколькими потоками можно в первом массиве выбрать несколько ведущих элементов, разделив его на равные порции, а во втором массиве найти соответствующие подмассивы. Каждый поток получит свои порции на обработку.
Эффективность такого слияние во многом зависит от того, насколько равномерно произошло "разделение" второго массива.
Создайте пустой файл main.cpp и скопируйте в него код из файла main_lsd3.cpp.
Класс Splitter выполняет слияние двух отсортированных массивов.
class Splitter:public task
{
private:
double *mas1;
double *mas2;
double *tmp;
int size1;
int size2;
public:
Splitter(double *_mas1, double *_mas2, double *_tmp,
int _size1, int _size2): mas1(_mas1),
mas2(_mas2), tmp(_tmp), size1(_size1),
size2(_size2)
{}
task* execute()
{
int a = 0;
int b = 0;
int i = 0;
while( (a != size1) && (b != size2))
{
if(mas1[a] <= mas2[b])
{
tmp[i] = mas1[a];
a++;
}
else
{
tmp[i] = mas2[b];
b++;
}
i++;
}
if (a == size1)
{
int j = b;
for(; j<size2; j++, i++)
tmp[i] = mas2[j];
}
else
{
int j=a;
for(; j<size1; j++, i++)
tmp[i] = mas1[j];
}
return NULL;
}
};
Класс LSDParallelSorter реализует рекурсивный алгоритм слияния, выполняя последовательную сортировку, в том случае, если размер сортируемой порции массива меньше, чем значение поля portion (значение этого поля задаётся при создании объекта в функции LSDParallelSortDouble). Слияние двух отсортированных массивов начинается с разбиения массивов на порции (для этого используется метод BinSearch(), реализующий бинарный поиск). Далее создаются задачи для слияния каждой пары полученных подмассивов и выполняется их параллельный запуск на выполнение.
class LSDParallelSorter:public task
{
private:
double *mas;
double *tmp;
int size;
int portion;
int threads;
private:
int BinSearch(double *mas, int l, int r, double x)
{
if(l==r)
return l;
if(l+1==r)
if(x<mas[l])
return l;
else
return r;
int m = (l+r)/2;
if(x<mas[m])
r = m;
else
if(x>mas[m])
l=m;
else
return m;
return BinSearch(mas, l, r, x);
}
public:
LSDParallelSorter(double *_mas, double *_tmp, int _size,
int _portion, int _threads): mas(_mas),
tmp(_tmp), size(_size),
portion(_portion), threads(_threads)
{}
task* execute()
{
if(size <= portion)
{
LSDSortDouble(mas, tmp, size);
}
else
{
LSDParallelSorter &sorter1 = *new (allocate_child())
LSDParallelSorter(mas, tmp, size/2, portion,
threads/2);
LSDParallelSorter &sorter2 = *new (allocate_child())
LSDParallelSorter(mas + size/2, tmp + size/2,
size - size/2, portion,
threads/2);
set_ref_count(3);
spawn(sorter1);
spawn_and_wait_for_all(sorter2);
Splitter **sp = new Splitter*[threads-1];
int s = size/2;
s /= threads;
int l = 0, r = s;
int l2 = 0, r2;
for(int i=0; i<threads-1; i++)
{
double x = mas[r];
r2 = BinSearch(mas + size/2, 0, size - size/2, x);
sp[i] = new (allocate_child())
Splitter(mas+l, mas + size/2 + l2,
tmp+l+l2, r-l, r2-l2);
l += s;
r += s;
l2 = r2;
}
Splitter &spl = *new (allocate_child())
Splitter(mas+l, mas + size/2 + l2,
tmp+l+l2, size/2-l,
size - size/2 - l2);
set_ref_count(threads+1);
for(int i=0; i<threads-1; i++)
spawn(*(sp[i]));
spawn_and_wait_for_all(spl);
for(int i=0; i<size; i++)
mas[i] = tmp[i];
delete[] sp;
}
return NULL;
}
};
В функцию LSDParallelSortDouble() необходимо внести небольшие изменения, т.к. теперь в конструктор класса LSDParallelSorter передаётся количество потоков.
void LSDParallelSortDouble(double *inp, int size,
int nThreads)
{
double *out=new double[size];
int portion = size/nThreads;
if(size%nThreads != 0)
portion++;
LSDParallelSorter& sorter = *new (task::allocate_root())
LSDParallelSorter(inp ,out, size, portion, nThreads);
task::spawn_root_and_wait(sorter);
delete[] out;
}
Соберите получившуюся реализацию и проведите тест для 10 миллионов элементов при разном числе потоков. Результаты, полученные авторами на тестовой инфраструктуре, представлены на рис. 4.10.
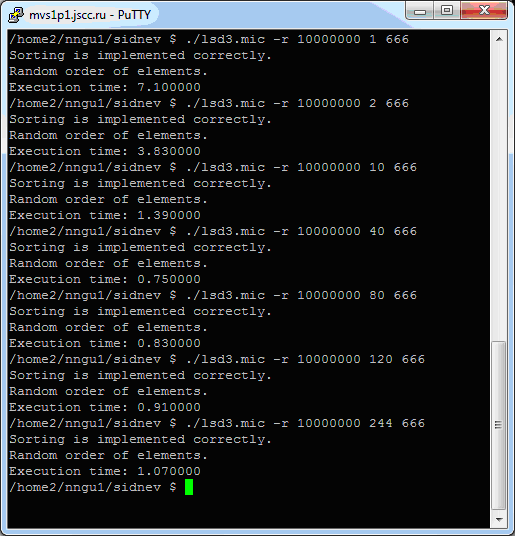
Рис. 4.10. Результаты параллельной побайтовой восходящей сортировки при использовании слияния "Разделяй и властвуй" на Intel Xeon Phi
Здесь мы запускали только вариант со случайным заполнением, но с разным числом потоков. Результаты очень похожи на предыдущие. Для наглядности приведём графики времени сортировки 10 миллионов ( рис. 4.11) и 100 миллионов ( рис. 4.12) элементов с помощью параллельного алгоритма LSD с использованием слияния "Разделяй и властвуй" на сопроцессоре.
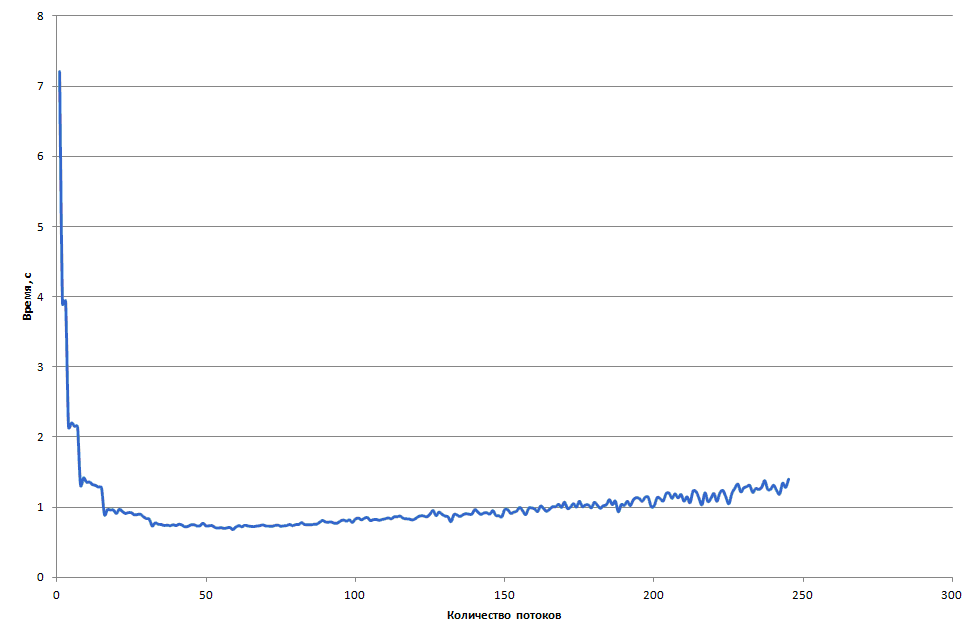
увеличить изображение
Рис. 4.11. Время сортировки 10 миллионов элементов с помощью параллельного алгоритма LSD с использованием слияния "Разделяй и властвуй" на Intel Xeon Phi
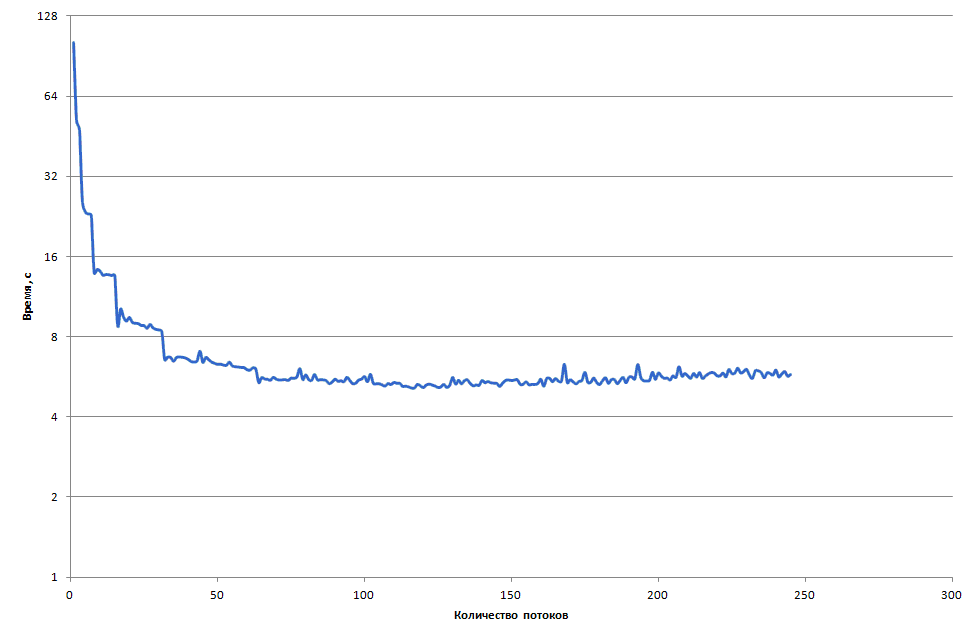
увеличить изображение
Рис. 4.12. Время сортировки 100 миллионов элементов с помощью параллельного алгоритма LSD с использованием слияния "Разделяй и властвуй" на Intel Xeon Phi
Максимальное ускорение, равное 19.7, достигается при использовании 129 потоков.