Инспектор
Вы можете этот курс.
Опубликован: 22.12.2006 | Уровень: специалист | Доступ: платный | ВУЗ: Московский государственный университет путей сообщения
Лекция 13:
Задача логического вывода и когерентность кэш-памяти в ВС SPMD-архитектуры
Проблема когерентности кэш-памяти решается совместно с проблемой "data flow"
Проблема управления когерентностью кэшей и ее совмещение с синхронизацией параллельных вычислений
Основное противоречие, разрешаемое при проектировании симметричных многопроцессорных ВС, — резкое различие скоростей работы операционных устройств и устройств оперативной (главной), прямоадресуемой, разделяемой (общей) памяти (ОП).
Для уравнивания этих скоростей используются два механизма: расслоение памяти и многоуровневая буферизация, выражающаяся в иерархии памяти. (Здесь мы не затрагиваем вопросов минимизации числа обращений к памяти при выполнении операций на стеке, построения многовходовой памяти и др.) Верхним уровнем буферизации памяти является многофункциональное СОЗУ, использующее технологию построения операционных устройств и входящее в состав каждого процессора. Основные области СОЗУ предназначены для организации кэшей команд (чаще называют буфером команд) и кэшей данных. Текущая обработка данных производится с использованием этих кэшей и предполагает оперативное, по возможности — параллельное с обработкой данных, обновление информации во взаимодействии с ОП.
Программные коды на протяжении времени выполнения программ остаются неизменными, и потому проблема организации буфера команд ограничена проблемой подкачки и, возможно, быстрого изменения порядка считывания команд (для чего используется принцип ассоциативной памяти).
Проблема кэша данных сопряжена с проблемой когерентности — проблемой коррекции общих данных, оказавшихся в момент их обработки размноженными и распределенными между кэшами разных процессоров. Данные, находящиеся в кэшах разных процессоров, могут быть изменены одним процессором, что, в соответствии с алгоритмическим замыслом, должно или не должно стать предметом коррекции кэшей других процессоров.
Например, решая конечно-разностным методом (методом "сеток") дифференциальное уравнение, мы при очередной итерации по рекуррентному соотношению находим значение функции-решения в узле через подобные решения в соседних узлах. Пусть вычислительный процесс построен так, что близкие узлы обрабатываются разными процессорами и области сетки оказались одновременно представленными в разных кэшах. Тогда, если некоторый процессор рассчитал новое приближение в узле, то, по замыслу алгоритмиста-программиста, он, произведя необходимую запись в ОП, может не препятствовать другим процессорам использовать старое приближение в этом узле — до окончания шага итерации по всей сетке, сочтя такое препятствование сложным. Но, по замыслу же программиста, процессор может немедленно сообщить кэшам других процессоров новое значение функции в узле — для ускорения процесса сходимости. Можно привести примеры, когда на разных процессорах запускаются процедуры с общими локальными данными (с одинаковыми виртуальными адресами), но с разной динамически складывающейся историей изменения значений. Можно себе представить, что все процессоры меняют значение некоторой величины в ОП по принципу "кто последний", но сами пользуются в дальнейшем своим значением. Здесь обмен уточненными значениями привел бы к ошибке. Значит, не всеми данными и не всегда надо обмениваться. Таким образом, в целом процесс когерентности должен быть управляемым и соотнесенным с замыслом программиста.
В то же время надо помнить, что одна из главных функций кэша — отображение текущего состояния ОП в памяти на "быстрых" регистрах каждого процессора. Поэтому представляется, что отображать во всех кэшах любые изменения в ОП все же нужно. Просто в некоторых случаях это следует делать немедленно, а в других — не столь срочно.
Необязательность немедленного соблюдения когерентности принципиально может выражаться при программировании значением признака, по которому при расчете значения переменной и записи его в ОП исключается попытка замещения значения переменной новым в кэшах других процессоров. Это означает, что кэш будет обновлен "естественным" путем — путем считывания из ОП данных или областей памяти в последующем счете.
Если заведомо известно, что все процессоры работают по разным задачам, то эта проблема отсутствует. Но если процессоры работают в рамках одной задачи, проблема когерентности обретает актуальность.
Особую актуальность эта проблема имеет в технологии SPMD, где максимальное внимание уделяется именно тому, чтобы на всех процессорах выполнялась одна и та же программа (см. целесообразность программирования метода "сеток") при совместной обработке общих массивов данных. Примером может служить одновременный запуск СУБД на разных процессорах при организации многоканального доступа к базе данных. При этом неизбежна синхронизация обработки отдельных общих данных или их подмассивов. Для такой синхронизации применяются принципы data flow, которые при конкретной реализации могут использовать механизм семафоров, но могут воспользоваться и более "быстрым" механизмом закрытия адресов. Он отмечает те адреса, или непосредственно регистры, по которым запрещено считывание до поступления в них данных. И если механизм семафоров эффективен на уровне программ (закрытый семафор вызывает прерывание и обращение процессора к очереди заданий), то механизм закрытия адресов ориентирован на уровень команд: команда пытается считать значение, пока оно не поступит в регистр с "закрытым" адресом.
Например, примитивная программа умножения всех элементов массива (одна из операций "свертки массива") может быть размножена и распределена между процессорами как программа умножения двух соседних элементов и засылки результата в продолжение этого же массива. Процессоры "проходят" по всему расширяемому ими массиву, и когда-то некоторые из них пытаются умножать промежуточные результаты, которые могут быть еще не получены. Тогда каждое умножение, при некотором предположении об общей синхронизации начала работы ВС, должно начинаться с закрытия адреса результата — для предотвращения его преждевременного использования. Засылка результата умножения в "закрытый" регистр разрешает его использование.
Процедура совмещения когерентности и синхронизации
При непредсказуемом распределении данных по кэш-памяти (точнее, областей памяти, содержащих эти данные), правильную работу такого механизма нужно аппаратно поддержать. Процессоры должны оперативно обмениваться информацией о закрываемых и модифицированных данных. При отсутствии такого оперативного обмена иногда предполагают даже сброс всех кэшей, в той их части, где в них отображается состояние ОП, при каждой записи в ОП. Далее кэши начинают естественным образом формироваться заново. При "медленной" памяти, по сравнению с операционными устройствами, это равносильно прерыванию.
В проекте "Эльбрус-3" элемент синхронизации, подобный закрытию адресов, реализован битами значимости быстрых регистров. При организации считывания в эти регистры из ОП их биты значимости "взводятся", что запрещает считывание из них. Биты значимости "сбрасываются" по окончании записи в них. Нами уже была показана возможность расширения этого механизма для синхронизации выполнения рассмотренных выше векторных операций "свертки массивов". Применение механизма семафоров в этом случае было бы неэффективным.
На алгоритмическом уровне решения задач мы знаем и учитываем порядок преобразования конкретных данных. Именно этот порядок определяет частичную упорядоченность работ, впоследствии распределяемых между процессорами. Значит, синхронизация использования общих данных справедливо должна закладываться на уровне написания алгоритма и реализовываться при трансляции с помощью наиболее простых средств синхронизации. Таким средством может служить расширение принципа "закрытия" адресов, охватывающего решение проблемы когерентности кэшей.
Типами данных, участвующими в поддержке когерентности кэшей, являются глобальные переменные ("глобалы"), массивы (также глобалы) и их дескрипторы, а также — примитивы синхронизации или другая информация (в частности, информация о закрытых адресах), синхронизирующая параллельный вычислительный процесс. Локальные данные процедур не участвуют в сохранении когерентности кэшей. Всем указанным данным, как правило, соответствуют специальные области кэшей (СОЗУ), реализованные с помощью специфических механизмов их обработки. Типизация данных и специализация областей кэша по типам данных конкретизирует и упрощает процедуры взаимного влияния кэшей. Но при этом некоторые величины, аппаратно поддерживаемые как глобалы, в действительности могут быть локальными данными, как было сказано выше относительно метода "сеток".
Во всем диапазоне промежуточных решений, известны два крайних способа комплексирования модулей ВС (процессоров, модулей ОП и др.): на основе общей магистрали и на основе перекрестного (матричного) коммутатора. Магистраль разделяет время обменов. Коммутатор разрешает одновременные не пересекающиеся обмены. В МВК Эльбрус-2 общая магистраль облегчает решение проблемы когерентности. Однако расслоение памяти немыслимо без коммутатора, тем более при большом числе процессоров и модулей памяти в системе. Практика построения семейства "Эльбрус" показала необходимость сочетания и того, и другого. Достаточно остановиться на проблеме обеспечения надежности, требующей взаимного контроля процессоров и выполнения реконфигурации системы. Таким образом, существующую магистраль, осуществляющую в основном передачи "каждый — всем", целесообразно дополнить функциями обеспечения когерентности.
Схема обеспечения когерентности представлена на рис. 13.1.
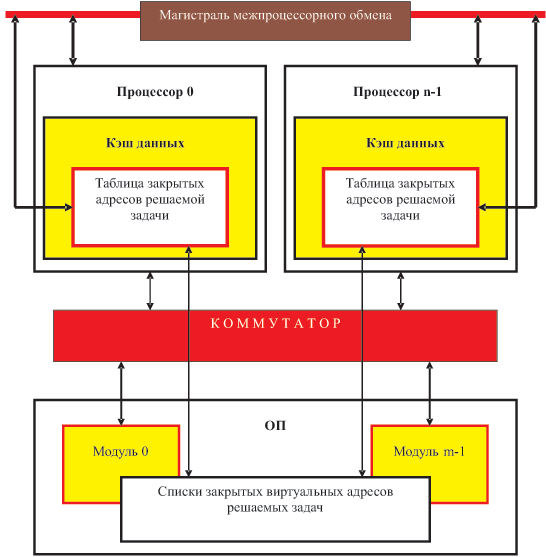
В начале решения новой задачи, использующей, естественно, виртуальные адреса, динамически переводимые в физические адреса ОП, в кэше данных каждого процессора формируется первоначально пустая таблица закрытых адресов решаемой задачи. Для этого целесообразно использовать ассоциативную память. По мере динамического заполнения, каждая строка этой таблицы (рис. 13.2) содержит виртуальный адрес (по мере конкретизации и упрощения организации работы ВС можно рассмотреть вариант, когда это — физические адреса ОП), который запрещено использовать до записи по нему рассчитанной величины. В этой же строке указан соответствующий адрес регистра в кэше.

В программе в явном виде должны присутствовать команды закрытия адресов. При этом должны быть указаны виртуальные адреса. Эти адреса пополняют динамически изменяемые списки закрытых виртуальных адресов решаемых задач, хранимые в ОП. По каждой команде закрытия адресов в соответствующих таблицах в кэшах всех процессоров, относящихся к этой задаче, (в общем случае не все процессоры могут решать одну и ту же задачу), формируется строка указанного ранее вида. Теперь каждое обращение к регистру кэша будет соотноситься с информацией в таблице, обеспечивая готовность остановить вычисления на процессоре в ожидании поступления необходимых данных. Каждая же запись по виртуальному адресу (здесь-то и наблюдается алгоритмический уровень синхронизации, исключающий анализ любой записи промежуточного результата вычислений) сопровождается, наряду с записью в ОП, поиском во всех кэшах, связанных с данной задачей, этого виртуального адреса для соответствующей замены по нему. Одновременно производится поиск в таблицах закрытых адресов в кэшах всех процессоров, начиная со своего процессора. Строки с указанным виртуальным адресом исключаются, а в указанный в строке регистр поступает найденное значение. Если вычисления были приостановлены из-за отсутствия этих значений, они продолжаются. Как сказано выше, все таблицы одновременно поддерживаются в ОП в виде списков закрытых адресов по каждой задаче, что необходимо при прерываниях. И, как мы отметили выше, все эти действия могут выполняться при отсутствии признака необязательности.
Мы не рассматриваем вопроса о том, как процессор находит данные по виртуальным адресам в своем кэше. Это увело бы нас из области взаимодействия кэшей в область их устройства. В "Эльбрусах" достаточно примеров кэшей — и специализированных по типам, и использующих различные способы организации. Например, наиболее подходящий для нашего случая принцип ассоциативной памяти успешно применен в ассоциативном запоминающем устройстве глобалов.
Рассмотренный принцип поддержки когерентности кэшей совместно с поддержкой синхронизации при использовании общих данных — управлением параллельным процессом по принципу data flow нуждается в анализе и развитии в соответствии с конкретизацией схем вычислительных процессов. Это неразрывно связано с проблемой ориентации симметричной ВС и проведением моделирования и экспериментального программирования.
Таким образом, проблема когерентности кэшей обретает адресную, смысловую, алгоритмическую направленность в общем плане синхронизации параллельных вычислений. Предложенное решение позволяет планировать лишь неизбежные действия, внося в решение проблемы когерентности элемент управления.