Инспектор
Вы можете этот курс.
Опубликован: 22.12.2006 | Уровень: специалист | Доступ: платный | ВУЗ: Московский государственный университет путей сообщения
Лекция 9:
Вычислительные системы нетрадиционной архитектуры
Ассоциативные вычисления и ВС
Главное отличие ассоциативной ВС от обычной системы последовательной обработки информации состоит в использовании ассоциативной памяти или подобного устройства, а не памяти с адресуемыми ячейками.
Ассоциативная память (АП) допускает обращение за данными на основе их признака или ключевого слова: имени, набора характеристик, задания диапазона и т.д.
Распространенный вид АП — таблица с двумя столбцами: " запросное поле — ответное поле. Строка таблицы занимает регистр памяти. По ключевому слову обрабатываются запросные поля: производится поиск на основе сравнений и выдается результат из одного (или более) ответных полей. При помощи маскирования можно выделить только те поля в ключевом слове, которые нужно использовать при поиске для сравнения.
Типичными операциями сравнения, выполняемыми ассоциативной памятью, являются: "равно — не равно", "ближайшее меньше чем — ближайшее больше чем", "не больше чем — не меньше чем", "максимальная величина — минимальная величина", "между границами — вне границ", "следующая величина больше — следующая величина меньше" и др. Т.е. все это есть операции отношения и определения принадлежности.
Поскольку ассоциативные ВС характеризуются только активным использованием АП в вычислениях, то в целом эти ВС обладают обычными свойствами, могут производить сложные преобразования данных и принадлежать типу ОКМД (STARAN, PEPE) или МКМД. Для параллельного обращения (для ускорения поиска) АП разбита на модули (32 модуля — в STARAN).
Когда в 1980 г. был провозглашен так называемый "Японский вызов" о построении ВС сверхвысокой производительности, то одним из пунктов была указана необходимость самого широкого использования принципов самообучающихся систем — систем, способных накапливать опыт и выдавать результат решения задачи без счета самой задачи. Это значит, что применение ассоциативных ВС неотделимо от проблемы искусственного интеллекта.
Предположим, мы пользуемся значениями функции  . Мы
можем запрограммировать счет этой функции на РС, и каждый раз, когда нам надо, задаем x и
запускаем программу, пользуясь прекрасным современным сервисом.
. Мы
можем запрограммировать счет этой функции на РС, и каждый раз, когда нам надо, задаем x и
запускаем программу, пользуясь прекрасным современным сервисом.
Предположим, та же функция сложна, а ее счет — важный элемент алгоритма управления в реальном времени. Решение приходит сразу: зададим эту функцию таблично, а для ускорения выборки включим в ВС ассоциативную память. Предусмотрим на ней операции, позволяющие производить простейшую интерполяцию. А именно, для данного значения x найти наибольший x1 < x и наименьший x2 >= x. Для них выбрать f(x1) и f(x2). Тогда вместо счета точного значения f(x) процессору остается произвести хотя бы линейную интерполяцию
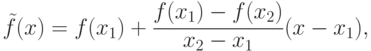
Однако в повседневной жизни мы очень часто решаем трудноформализуемые задачи, когда алгоритм решения не очевиден. Но мы учимся, обретаем опыт, затем оцениваем складывающуюся ситуацию на "похожесть" и принимаем решение.
Простейшая задача: как мы автоматически определяем, на сколько надо повернуть рулевое колесо, чтобы остаться на дороге? Ведь первый раз мы въезжали в бордюр! Значит, некая таблица постепенно сложилась и зафиксировалась в нашем сознании.
Пожалуй, наиболее полно автоматически и с наибольшей практичностью решение задачи самообучения представлено в артиллерии, точнее — в правилах стрельбы.
После занятия огневой позиции подготовка установок для ведения огня занимает много времени. На рассчитанных установках по каждой цели производится пристрелка, когда цель захватывается в широкую вилку, затем по наблюдениям вилка "половинится" до тех пор, пока на середине узкой вилки не переходят на поражение. После стрельбы следует замечательная команда "Стой, записать...", по которой наводчик на щите орудия пишет номер цели и все пристрелянные установки по ней. Такая работа проделывается и по фиктивным целям — реперам. Постепенно при "работе" на данной местности запоминаются пристрелянные установки по многим целям и реперам. С их появлением и развитием подготовка данных по вновь появляющимся целям резко упрощается, т.к. сводится к переносу огня от ближайшей цели или репера, т.е. к внесению поправок по дальности и направлению. Доказано, что при этом достаточно сразу назначать захват цели в узкую вилку, т.е. пристрелка упрощается. Правила стрельбы существуют века, однако вряд ли кто-то осознавал теоретически, что речь идет о реализации самообучающейся системы.
Для трудноформализуемых задач управления или для увеличения производительности вычислительных средств известно так называемое ситуационное управление. Оно заключается в том, что для каждого значения вектора, описывающего сложившуюся ситуацию, известно значение вектора, описывающего то решение, которое следует принять. Если все ситуации отразить невозможно, должно быть задано правило интерполяции (аналог интерполяции, обобщенной интерполяции).
Итак, пусть исходная ситуация характеризуется вектором X = {x1, ..., xm}. По значению X, т.е. по его компонентам, принимается решение Y, также представляющее собой вектор, Y = {y1, ..., yn}.
(Значения X и Y могут определяться целыми и вещественными,
булевыми. Изначально они могут иметь нечисловую природу: "темнее — светлее",
"правее — левее", "ласковее — суровее" и т.д. Мы не будем рассматривать проблему
численной оценки качественных или эмоциональных категорий.)
Предположим, для любых двух значений X1 и X2, а также Y1 и Y2 определено отношение xi(1) <= xi(2) (или наоборот), yj(1) <= yj(2) (или наоборот).
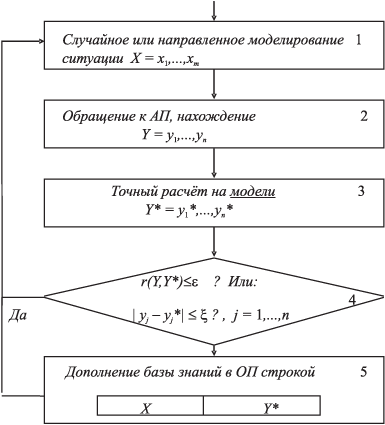
Структура ассоциативной памяти и общий вид ее обработки показаны на рисунке 9.5.
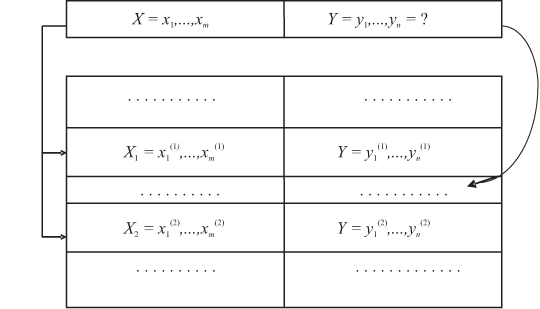
Пусть поступила входная ситуация X, для которой необходимо найти решение Y. В АП находятся два вектора X1 и X2, минимально отличающиеся по всем координатам от вектора X. для Для этих векторов там же записаны векторы решения Y1 и Y2 соответственно. Однако если для компоненты xi выполняется условие xi <= xi(1)(xi >= xi(1)), то должно выполняться условие xi >= xi(2)(xi <= xi(2)), i = 1, ..., m. Таким образом, отыскивается "вилка", которой принадлежит входная ситуация. Тогда, опираясь на известные решения на границах этой вилки, необходимо выдать промежуточное решение для данной ситуации. Это можно сделать методом той же обобщенной интерполяции
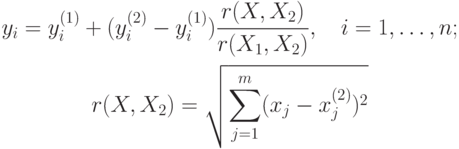
Если известно, что точность Y достаточна, принципиально возможно дополнение АП новой строкой

Однако динамика развития и уточнения АП как базы знаний представляется иной. Далеко не всегда по ошибочному принятию решений целесообразно развивать базу знаний. "Учение на ошибках" может привести к трагедии (или к частному срыву процесса управления), особенно на этапе обучения системы.
Обучение системы целесообразно проводить на достаточно точной модели, максимально использующей точный расчет компонент решения. Применение модели для обучения используется не только на специально предусмотренном этапе обучения системы, но и вне реального цикла управления, т.е. когда система работает в режиме дежурства, параллельно с функциональным контролем. Тогда алгоритм ее работы представлен на рис. 9.6.