|
При прохождении теста 1 в нем оказались вопросы, который во-первых в 1 лекции не рассматривались, во-вторых, оказалось, что вопрос был рассмаотрен в самостоятельно работе №2. Это значит, что их нужно выполнить перед прохождением теста? или это ошибка? |
Инспектор
Вы можете этот курс.
Опубликован: 20.08.2013 | Уровень: для всех | Доступ: платный | ВУЗ: Новосибирский Государственный Университет
Самостоятельная работа 3:
Машинное обучение
3. Обзор возможностей библиотеки OpenCV для решения задач обучения без учителя
3.1. Задача кластеризации
Задача кластеризации заключается в разбиении выборки 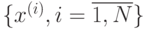 на непересекающиеся подмножества таким образом, чтобы схожие точки (обычно близкие в некоторой метрике) попали в одно подмножество (кластер), а точки из разных кластеров сильно друг от друга отличались (были далеки). Для решения данной задачи в библиотеки OpenCV реализован метод центров тяжести (k-means) и EM-алгоритм. В данной лабораторной работе рассматривается использование программной реализации метод центров тяжести, как одного из наиболее популярных алгоритмов кластеризации на настоящий момент.
на непересекающиеся подмножества таким образом, чтобы схожие точки (обычно близкие в некоторой метрике) попали в одно подмножество (кластер), а точки из разных кластеров сильно друг от друга отличались (были далеки). Для решения данной задачи в библиотеки OpenCV реализован метод центров тяжести (k-means) и EM-алгоритм. В данной лабораторной работе рассматривается использование программной реализации метод центров тяжести, как одного из наиболее популярных алгоритмов кластеризации на настоящий момент.
3.2. Метод центров тяжести (k-means)
Метод центров тяжести разбивает выборку на заданное количество кластеров 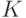 путем выбора их центров. Поиск центров кластеров производится из соображений минимизации суммарного расстояния от каждой точки до ближайшего центра с помощью метода локальной оптимизации. Так как алгоритм не гарантирует достижения глобального минимума, ключевую роль играет начальная инициализация центров кластеров. Распространенным методом является случайный (с равной вероятностью) выбор точек из имеющегося множества . Однако алгоритм центров тяжести, запущенный на таких начальных данных может выдать в результате локальный минимум сколь угодно хуже глобального. Альтернативой является метод k-means++ [ 5 ], предложенный Д. Артуром и С. Вассильвицким, основанный на последовательном выборе точек из выборки случайным образом, но с вероятностью пропорциональной квадрату расстояния от точки до ближайшего уже выбранного центра. В данном случае, математическое ожидание отношения найденного минимума к глобальному является величиной
путем выбора их центров. Поиск центров кластеров производится из соображений минимизации суммарного расстояния от каждой точки до ближайшего центра с помощью метода локальной оптимизации. Так как алгоритм не гарантирует достижения глобального минимума, ключевую роль играет начальная инициализация центров кластеров. Распространенным методом является случайный (с равной вероятностью) выбор точек из имеющегося множества . Однако алгоритм центров тяжести, запущенный на таких начальных данных может выдать в результате локальный минимум сколь угодно хуже глобального. Альтернативой является метод k-means++ [ 5 ], предложенный Д. Артуром и С. Вассильвицким, основанный на последовательном выборе точек из выборки случайным образом, но с вероятностью пропорциональной квадрату расстояния от точки до ближайшего уже выбранного центра. В данном случае, математическое ожидание отношения найденного минимума к глобальному является величиной 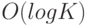 .
.
Метод центров тяжести с евклидовой метрикой реализован в библиотеке OpenCV в виде функции kmeans модуля core:
double kmeans( InputArray data,
int K,
InputOutputArray bestLabels,
TermCriteria criteria,
int attempts,
int flags,
OutputArray centers=noArray() );
Рассмотрим параметры данной функции:
- data – матрица типа CV_32F, в которой каждой строке соответствует точка выборки.
- K – количество кластеров, получаемых на выходе алгоритма.
-
bestLabels – матрица размера
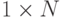 , в которую для каждой точки
, в которую для каждой точки 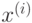 будет сохранен номер кластера, в который попала данная точка.
будет сохранен номер кластера, в который попала данная точка. - criteria – критерий останова итерационного метода оптимизации. Алгоритм k-means может закончить работу либо после совершения заданного количества итераций, либо если каждый центр кластера сдвинется на величину меньше criteria.epsilon.
- attempts – количество запусков алгоритма k-means с различными начальными центрами кластеров. В качестве конечного разбиения будет возвращен наилучший из полученных результатов.
- flags – метод генерации центров кластеров перед запуском алгоритма k-means. Допустимые значения: KMEANS_RANDOM_CENTERS – случайный равновероятный выбор центров, KMEANS_PP_CENTERS – случайный выбор методом k-means++, KMEANS_USE_INITIAL_LABELS – для первого запуска используется заданное с помощью параметра bestLabels разбиение.
- centers – матрица с наилучшими найденными центрами кластеров. Каждая строка соответствует координатам центра одно кластера.
Данная функция возвращает сумму квадратов расстояний от каждой точки до ближайшего к ней центра.
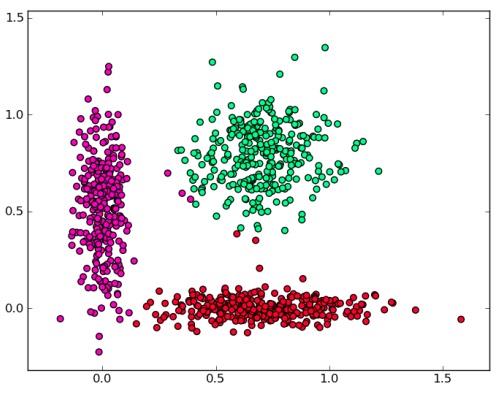
Рассмотрим пример использования функции kmeans для кластеризации точек на плоскости. Результат полученной кластеризации приведен на рис. 8.5.
#include <opencv2/core/core.hpp>
using namespace cv;
Mat generateDataset()
{
int n = 300;
Mat data(3 * n, 2, CV_32F);
randn(data(Range(0, n), Range(0, 1)), 0.0, 0.05);
randn(data(Range(0, n), Range(1, 2)), 0.5, 0.25);
randn(data(Range(n, 2 * n), Range(0, 1)), 0.7, 0.25);
randn(data(Range(n, 2 * n), Range(1, 2)), 0.0, 0.05);
randn(data(Range(2 * n, 3 * n), Range(0, 1)),
0.7, 0.15);
randn(data(Range(2 * n, 3 * n), Range(1, 2)),
0.8, 0.15);
return data;
}
int main(int argc, char* argv[])
{
Mat samples = generateDataset();
Mat labels;
Mat centers;
kmeans(samples,
3,
labels,
TermCriteria(TermCriteria::COUNT +
TermCriteria::EPS, 10000, 0.001),
10,
KMEANS_PP_CENTERS,
centers);
return 0;
}
Александра Максимова
Алена Борисова
|
В лекции по обработке полутоновых изображений (http://www.intuit.ru/studies/courses/10621/1105/lecture/17979?page=2) увидела следующий фильтр:
В описании говорится, что он "делает изображение более чётким, потому что, как видно из конструкции фильтра, в однородных частях изображение не изменяется, а в местах изменения яркости это изменение усиливается". Что вижу я в конструкции фильтра (скорее всего ошибочно): F(x, y) = 2 * I(x, y) - 1/9 I(x, y) = 17/9 * I(x, y), где F(x, y) - яркость отфильтрованного пикселя, а I(x, y) - яркость исходного пикселя с координатами (x, y). Что означает обычное повышение яркости изображения, при этом без учета соседних пикселей (так как их множители равны 0). Объясните, пожалуйста, как данный фильтр может повышать четкость изображения? |
