Инспектор
Вы можете этот курс.
Опубликован: 19.11.2012 | Уровень: для всех | Доступ: платный | ВУЗ: Национальный исследовательский университет "Высшая Школа Экономики"
Лекция 7:
Передача информации
Аннотация: Передача информации является одним из основных информационных процессов. Передача информационных сообщений происходит при устном общении людей, при разговоре по телефону, при использовании визуальных сигналов (жесты, специальные сигналы с использованием флажков, световых приборов), а также с применением различных технических средств связи (телеграф, радио и т.п.).
Ключевые слова: оптоволоконный кабель, ПО, кодирование, слово, компромисс, избыточность, источник сообщения, скорость передачи, выход, подмножество, таблица, декодирование, четность, мера, абсолютная величина числа, расстояние, гипотеза, выделенная вершина, перечисление, алгоритм, вероятность, векторные, пространство, сложение, операции, поле, умножение, равенство, вектор, линейная комбинация, множества, оболочка, доказательство, плоскость, система линейных уравнений, норма вектора, выражение, матрица, длина, размерность, Единичная матрица, линейный код, компонент, базис, Произведение, линейное уравнение, путь, отображение, ядро, разбиение, класс, ранг, систематический, представление, значение
Модель процесса передачи. Двоичный симметричный канал
Обработка информации в вычислительных системах невозможна без передачи сообщений между отдельными элементами (оперативной памятью и процессором, процессором и внешними устройствами). Примеры процессов передачи данных приведены в следующей таблице.
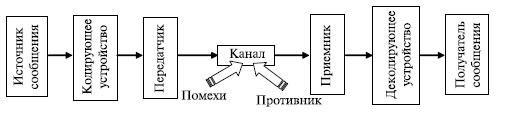
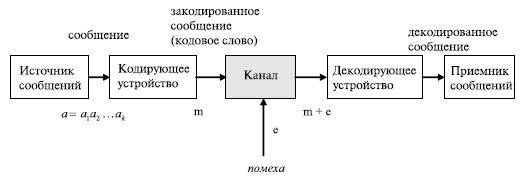
В перечисленных выше процессах передачи можно усмотреть определенное сходство. Общая схема передачи информации [31], [33], [32] показана на рис.7.1.
В канале сигнал подвергается различным воздействиям, которые мешают процессу передачи. Воздействия могут быть непреднамеренными (вызванными естественными причинами) или специально организованными (созданными) с какой-то целью некоторым противником. Непреднамеренными воздействиями на процесс передачи (помехами) могут являться уличный шум, электрические разряды (в т. ч. молнии), магнитные возмущения (магнитные бури), туманы, взвеси (для оптических линий связи) и т.п.
Для изучения механизма воздействия помех на процесс передачи данных и способов защиты от них необходима некоторая модель. Процесс возникновения ошибок описывает модель под названием двоичный симметричный канал (ДСК) [32], [33], схема которой показана на рис.7.2.
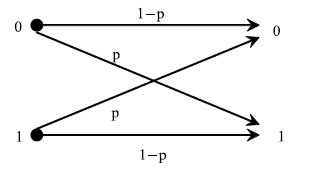
При передаче сообщения по ДСК в каждом бите сообщения с вероятностью  может произойти ошибка, независимо от наличия ошибок в других битах. Ошибка заключается в замене знака 0 на 1 или 1 на 0.
может произойти ошибка, независимо от наличия ошибок в других битах. Ошибка заключается в замене знака 0 на 1 или 1 на 0.
Некоторые типы ошибок:
- замена знака 0 на 1 или 1 на 0
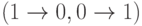 ;
; - вставка знака
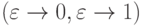 ;
; - пропуск знака
 .
.
Чаще других встречается замена знака. Этот тип ошибок исследован наиболее полно.
Способы повышения надежности передачи сообщений
Если при кодировании сообщений используются оптимальные коды, то при появлении всего лишь одной ошибки все сообщение или его значительная часть может быть искажена. Рассмотрим пример. Пусть кодирование элементарных сообщений 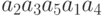 источника осуществляется с использованием кодовой таблицы
источника осуществляется с использованием кодовой таблицы
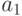


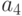
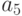
Тогда закодированное сообщение имеет вид 011011100110. Если в первом знаке произойдет ошибка, то будет принято сообщение 111011100110, которое декодируется в слово 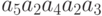 . Полное искажение сообщения из-за одной ошибки происходит вследствие того, что одно кодовое слово переходит в другое кодовое слово в результате замены одного или нескольких знаков. Пример показывает, что оптимальное кодирование плохо защищает сообщения от воздействия ошибок.
. Полное искажение сообщения из-за одной ошибки происходит вследствие того, что одно кодовое слово переходит в другое кодовое слово в результате замены одного или нескольких знаков. Пример показывает, что оптимальное кодирование плохо защищает сообщения от воздействия ошибок.
На практике необходим компромисс между экономностью кода и защитой от ошибок.
Сначала удаляется "бесполезная" избыточность (в основном статистическая), а затем добавляется "полезная" избыточность, которая помогает обнаруживать и исправлять ошибки.
Рассмотрим некоторые методы повышения надежности передачи данных. Широко известными методами борьбы с помехами являются следующие [34]:
- передача в контексте;
- дублирование сообщений;
- передача с переспросом.
Рассмотрим подробней каждый из этих способов.
- Передача в контексте. С этим хорошо известным и общепринятым способом сталкивался каждый, кто, пытаясь передать по телефону с плохой слышимостью чью-либо фамилию, называл вместо букв, ее составляющих, какие-нибудь имена, первые буквы которых составляют данную фамилию. В данном случае правильному восстановлению искаженного сообщения помогает знание его смыслового содержания.
- Дублирование сообщений. Этот способ тоже широко применяется в житейской практике, когда для того, чтобы быть правильно понятым, нужное сообщение повторяют несколько раз.
- Передача с переспросом. В случае, когда получатель имеет связь с источником сообщений, для надежной расшифровки сообщений пользуются переспросом, т. е. просят повторить все переданное сообщение или часть его.
Общим во всех этих способах повышения надежности является введение избыточности, то есть увеличение тем или иным способом объема передаваемого сообщения для возможности его правильной расшифровки при наличии искажений.
Следует отметить, что введение избыточности уменьшает скорость передачи информации, так как только часть передаваемого сообщения представляет интерес для получателя, а избыточная его доля введена для предохранения от шума и не несет в себе полезной информации.
Естественно выбирать такие формы введения избыточности, которые позволяют при минимальном увеличении объема сообщения обеспечивать максимальную помехоустойчивость.
Принципы обнаружения и исправления ошибок с использованием кодов
Способы введения избыточности, позволяющие обнаруживать и исправлять ошибки, можно разделить на два класса, один из которых соответствует блоковым кодам, а другой - сверточным кодам [33]. Обе схемы кодирования применяются на практике. При блоковом кодировании последовательность, составленная из полученных в результате коди-рования источника кодовых слов, разбивается на блоки одинаковой длины. Каждый блок перед отправкой в канал обрабатывается независимо от других. Выход устройства, выполняющего сверточное кодирование, напротив, зависит не только от обрабатываемых в данный момент знаков, но и от предыдущих знаков. Остановимся более подробно на блоковом кодировании.
Как было показано ранее, ошибка в одном лишь разряде может испортить все сообщение. Чтобы избежать таких тяжелых последствий, сообщения, закодированные каким-либо экономным кодом, перед направлением в канал делятся на блоки одинаковой длины и каждый блок передается отдельно. При этом методы, позволяющие обнаруживать и исправлять ошибки, применяются к каждому блоку. Такой прием напоминает разделение большого судна на несколько изолированных друг от друга отсеков, что позволяет при пробоине в одном отсеке сохранить судно и груз в других отсеках.
Рассмотрим схему передачи данных, показанную на рис.7.3.
С кодирующего устройства в канал поступают закодированные блоки (кодовые слова) одинаковой длины  . В канале в результате действия различных помех в некоторых битах передаваемого сообщения могут происходить ошибки. Процедуру кодирования при передаче и
. В канале в результате действия различных помех в некоторых битах передаваемого сообщения могут происходить ошибки. Процедуру кодирования при передаче и
декодирования при приеме с использованием одной и той же кодовой таблицы иллюстрируем рис.7.4. Предполагается, что появление ошибок описывается моделью дискретного симметричного канала

В геометрической интерпретации эти блоки можно рассматривать как точки n-мерного пространства 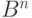 , где
, где  . Точки этого пространства представляют собой последовательности чисел 0 и 1 длины . Пространства для
. Точки этого пространства представляют собой последовательности чисел 0 и 1 длины . Пространства для  можно представить в виде угловых точек единичного интервала (
можно представить в виде угловых точек единичного интервала (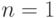 ), вершин квадрата со стороной, равной 1 (
), вершин квадрата со стороной, равной 1 (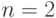 ), и вершин куба с ребрами длины 1 (
), и вершин куба с ребрами длины 1 (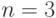 ). Эти пространства условно изображены на рис.7.5.
). Эти пространства условно изображены на рис.7.5.
Код, используемый для обнаружения и исправления ошибок, представляет собой некоторое подмножество пространства . В качестве примера можно привести код  . Кодовые слова этого кода как точки пространства
. Кодовые слова этого кода как точки пространства  изображены на рис. 7.6 белыми кружками. Если представить куб расположенным в трехмерном пространстве, то словам данного кода соответствуют вершины тетраэдра. Более полезным
изображены на рис. 7.6 белыми кружками. Если представить куб расположенным в трехмерном пространстве, то словам данного кода соответствуют вершины тетраэдра. Более полезным

с практической точки зрения является то, что каждое слово кода содержит четное число единиц. Если при передаче кодового слова через канал произойдет одна ошибка, то число единиц в слове станет нечетным. Проверяя свойство четности числа единиц в слове после получения его из канала на приемном конце, можно обнаружить одну ошибку. В данном случае для кодирования четырех знаков используется 3 двоичных разряда, хотя достаточно двух. Однако благодаря такой избыточности удается обнаружить одну ошибку.
В соответствии с общей схемой передачи сообщений в кодирующем и декодирующем устройствах используется одна и та же кодовая таблица и, следовательно, множество кодовых слов. При передаче кодового слова через канал возможны следующие ситуации.
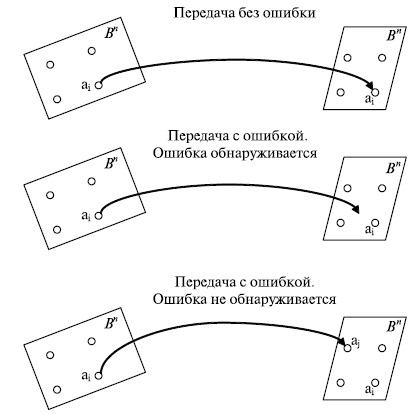
Передавалось и было получено некоторое кодовое слово 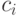 . Эта ситуация, которая показана в верхней части рис.7.7, соответствует отсутствию ошибок при передаче.
. Эта ситуация, которая показана в верхней части рис.7.7, соответствует отсутствию ошибок при передаче.
Передавалось кодовое слово ci, а получено было сообщение, которое не является кодовым словом. При попытке декодировать это сообщение будет обнаружено, что такого слова в кодовой таблице нет. Это означает, что ошибка, произошедшая при передаче и исказившая кодовое слово, обнаружена. Эта ситуация изображена в средней части рис.7.7.
В процессе передачи кодовое слово 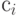 может так исказиться из-за ошибок, что оно превратится в другое кодовое слово
может так исказиться из-за ошибок, что оно превратится в другое кодовое слово 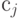 . В этом случае ошибка не обнаруживается, поскольку полученное сообщение также является кодовым словом, и декодирование будет выполнено неверно. Такая ситуация показана в нижней части рис.7.7.
. В этом случае ошибка не обнаруживается, поскольку полученное сообщение также является кодовым словом, и декодирование будет выполнено неверно. Такая ситуация показана в нижней части рис.7.7.