Инспектор
Вы можете этот курс.
Опубликован: 19.11.2012 | Уровень: для всех | Доступ: платный | ВУЗ: Национальный исследовательский университет "Высшая Школа Экономики"
Лекция 3:
Инструменты традиционного и сетевого информационного поиска
Аннотация: Понятие информационного поиска появилось только в середине прошлого века. Оно объединило такие, казалось бы, разные виды деятельности, как составление библиотечных каталогов и библиографических указателей, организация библиотек и справочно-информационного обслуживания, архивное дело, создание словарей, справочников, энциклопедий, вспомогательных указателей к монографиям и сборникам.
Ключевые слова: представление, поиск, ПО, место, разделы, информация, указатель, Произведение, деятельность, запрос, индекс, компьютер, массив, выход, запоминающее устройство, контур, блок-схема, предметная рубрика, индексатор, информационный шум, классификационная схема, резюме, элемент текста, пользователь языка, тезаурус, дескриптор, связь, определитель, автоматизированные информационные системы, цитирование, слово, работ, очередь, последовательный поиск, сочетания, подразделения, рубрикатор, значение
Предыстория и сущность
В основе этого понятия лежит представление о том, что поиск необходимой информации в любом собрании документов практически невозможен путем прочтения или даже беглого просмотра текстов всех документов данного собрания. Поэтому уже с незапамятных времен для поиска информации применяют ряд логических процедур, которые в совокупности и составляют процесс информационного поиска. Прочтение полного текста документа заменили просмотром заглавий, аннотаций, рефератов. Однако и эта процедура в многотысячных собраниях документов оказалась слишком трудоемкой. Документы пришлось систематизировать по содержанию, которое условно стали обозначать индексами, т. е. буквами и/или цифрами. Систематизация по разделам наук (классам) - один из самых первых способов раскрытия содержания научно-технических документов, моделирующий работу человеческого сознания и восходящий к глубокой древности.
По мере увеличения количества письменных и печатных документов и объема наших знаний о мире их классификация усложнялась. Эти классификации получили название иерархических. Многотомные схемы классификации конца прошлого - начала нашего века насчитывали десятки тысяч классов, подклассов, отдельных рубрик. Специалистам смежных областей знания и особенно массовому читателю библиотек стало трудно ориентироваться в схемах классификации и определять в их иерархии место той рубрики, по которой необходимо получать информацию.
Да и сами рубрики, которые строго ориентированы на узкие разделы наук, подвергающихся непрерывному процессу дифференциации, перестали удовлетворять специалистов-практиков, которым нужна была все более комплексная, предметная информация. Это привело к созданию в 70-х годах XIX в. предметной или, точнее, алфавитно-предметной классификации. На долгие годы она стала господствующей при составлении энциклопедий, вспомогательных указателей к трудам, систематически излагающим проблему или раздел науки, а в США, где она была создана, - при организации каталогов.
Стремительный рост объемов литературы значительно усложнил также задачу идентификации каждого произведения печати. Библиотеки первыми столкнулись с необходимостью создать инструмент, при помощи которого можно было бы быстро и надежно устанавливать наличие определенного произведения в их фондах. Таким инструментом стал в XIX в. авторский, именной указатель (алфавитный каталог, по библиотечной терминологии), который однозначно идентифицировал произведение по фамилиям лиц, принимавших участие в его создании или же связанных с его содержанием. Таким образом, до середины ХХ в. возможности содержательного поиска информации по справочникам или документов, содержащих нужную информацию, в библиотеках ограничивались тремя способами: систематическим, предметным и алфавитным.
Традиционной технологией реализации этих способов были списки, перечни книг и статей, содержавших необходимую информацию. С 70-х годов XIX в. эти сведения стали записываться на дискретных носителях - библиотечных карточках из плотного картона формата 75х125 мм (размер сложенной пополам американской почтовой карточки). Следует отдать должное этой традиционной технологии. Она успешно обеспечивала культурный прогресс на протяжении целого столетия вплоть до нынешнего этапа научно-технической революции, позволила накапливать и использовать многомиллионные собрания документов, обслуживать тематические потребности ученых и специалистов в необходимой им информации. На ней и сегодня еще в значительной степени зиждется деятельность всей мировой библиотечной системы - этого краеугольного камня человеческой культуры, важными составными частями которой является наука и техника.
Однако недостаточность, ограниченность этой технологии стала все более остро ощущаться уже в первой четверти ХХ в. В науке первыми почувствовали это химики из-за быстрого роста числа синтезируемых ими веществ. Обычные методы оповещения - библиографические указатели, библиотечные каталоги, справочники - начали значительно отставать по времени от успехов исследователей и перестали охватывать их результаты в полном объеме. Революции в физике и электронике, характеризующие середину прошлого столетия, усугубили трудности информационной коммуникации.
Процедуры и понятия
Научное сообщество осознало необходимость организационного оформления информационной деятельности, которая в течение нескольких десятилетий подспудно созревала в недрах науки и техники. Большая наука индустриального типа, пришедшая на смену "малой" науке университетского типа, выдвинула задачу создания систем научно-технической информации. Именно в это время, в конце 40-х - начале 50-х гг. прошлого века были сформулированы понятия информационного поиска, информационно-поисковой системы, информационно-поискового языка, была выдвинута задача механизации, а затем и автоматизации информационного поиска.
К этому времени стало ясно, что информационный поиск - это совокупность логических процедур, в результате которых в ответ на информационный запрос выдается либо необходимая информация, либо документы, в которых она может содержаться, либо библиографические адреса этих документов. В первом случае поиск получил название фактографического, во втором - документального, в третьем - библиографического. Эти процедуры сводятся к следующему.
Каждый вновь появляющийся документ подвергается анализу, в результате которого определяется его смысловое содержание. Затем это абстрактное представление о содержании (считается, что оно должно совпадать с авторским) выражается на некотором информационно-поисковом языке, т. е. синтезируется в виде библиографического описания и индекса.
Индекс образуется путем мысленного сопоставления основного смыслового содержания с потенциальными запросами потребителей информации. Эти запросы как бы зафиксированы в схемах классификации и обозначены индексами. Сама процедура выражения основного смыслового содержания документов и информационных запросов на информационно-поисковом языке получила название индексирования и составляет существенную часть аналитико-синтетической обработки документов. Информационный поиск, таким образом, заключается в замене содержательного прочтения полного текста документов формальным сличением (сравнением на соответствие) их поисковых образов с запросами на языке индексов.
Понятно, что такая замена значительно упрощает и убыстряет нахождение нужной информации, делает возможной автоматизацию процедуры сравнения. Но за это приходится платить неполнотой и неточностью поиска. Описанные выше логические процедуры допускают субъективизм осуществляющих их лиц, а используемые информационно-поисковые языки несовершенны и не способны адекватно передавать содержание документов и смысл запросов. Следовательно, информационные потери и шум - неизбежные условия информационного поиска. Когда говорят, что поиск осуществлен со 100-процентной полнотой, имеют в виду, что информационного поиска не производилось, а был осуществлен полный перебор всех текстов (современная технология в некоторых случаях предоставляет такую возможность).
Информационный поиск реализуется при помощи информационно-поисковой системы, которая в абстрактном виде должна состоять из информационно-поискового языка, правил перевода на этот язык и критерия смыслового соответствия, определяющего объем выдачи документов или информации (критерий выдачи). Конкретная система включает также средства реализации (перечень, картотека, механический селектор, компьютер), информационный массив и обслуживающий персонал.
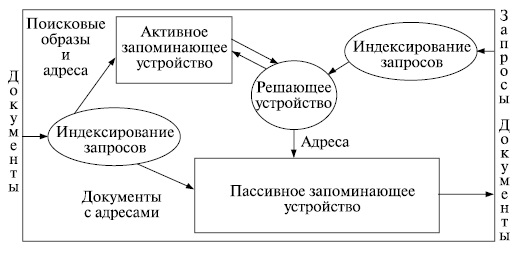
Функционирование простейшей документальной информационно-поисковой системы можно проследить по ее блок-схеме на рис. 3.1. В системе имеется два входа (для документов и запросов) и один выход (для выдачи документов по запросам). На входах имеются преобразователи для индексирования документов и запросов. Поисковые образы документов вместе с адресами их хранения (номерами) направляются в активное запоминающее устройство (ЗУакт), а сами документы - в пассивное (ЗУпас). Индексы каждого запроса сравниваются с индексами всех документов в решающем устройстве (РУ), которое в случае их соответствия (полного или предусмотренного критерием выдачи) дает в хранилище (ЗУпас) команду на выдачу документа. Это хранилище составляет как бы второй контур системы (сами документы), которого нет у библиографических (одноконтурных) систем.
Даже названия элементов на блок-схеме говорят о компьютерной реализации информационно-поисковой системы. Однако блок-схема верно обрисовывает работу любой системы, включая и наиболее традиционные. Это легко видеть на примере библиотеки. Преобразователи на входах соответствуют отделам обработки и справочно-библиографическому, ЗУакт - каталогам, ЗУпас - фондам. Нет в библиотеке только РУ - оно моделируется интеллектом читателя, который (хотя часто он и не осознает этого) вырабатывает собственный критерий выдачи и собственную стратегию поиска.
Не случайно именно эта интеллектуальная часть функционирования информационно-поисковой системы представила наибольшие трудности для автоматизации, именно она больше всего сдерживала развитие этих систем. Камнем преткновения явились, прежде всего, традиционные информационно-поисковые языки, ограничивающие возможности содержательного поиска информации. Расхожее мнение о том, что эти языки трудно поддаются автоматизации, неверно. Но они рассчитаны на ручную реализацию, и поэтому использование их в компьютерах удорожает поиск, ограничивает число пользователей и не дает никаких выигрышей, т. е. не снимает ограничений, присущих этим языкам.
А ограничения эти стали особенно ощутимыми на нынешнем этапе научно-технической революции. Прежде всего, традиционная технология поиска рассчитана на стабильный, медленно меняющийся состав запросов. В схемах классификации и перечнях предметных рубрик уже заранее как бы скоординированы все понятия, по которым можно извлекать информацию из документов и затем производить по ним поиск (такие языки поэтому и получили название предкоординатных). Это приводит к тому, что при возникновении новой проблемы или направления исследований, по которым имеется полученная прежде информация, система не обеспечивает ее поиска. Ведь эта тематика раньше не была сформулирована и не нашла места в схемах классификации и списках предметных рубрик, а значит, и индексирование по ней не производилось.
Другими словами, традиционная технология поиска не позволяет искать информацию по любому, заранее не предвиденному сочетанию признаков. При этом субъективизм индексатора при извлечении основного содержания документа увеличивает информационный шум и потери, предопределенные характером традиционных поисковых языков. Нельзя не отметить также, что основанные на них системы ручного поиска, даже фактографические, не предназначены для манипулирования полученными из них данными. Они не имеют логического аппарата для содержательной переработки этих данных. Подобная задача всегда решалась самими потребителями без помощи информационных систем.